参考资料:《实战Java高并发程序设计》
1. 简介
-
分而治之是一个非常有效的处理大量数据的方法。
-
Fork一词原义是吃饭用的叉子,也有分叉的意思。Linux中使用fork()函数来创建子进程,从而使系统进程可以多一个执行分支。Java中也沿用了类似的命名。
-
Join的含义和Thread.join()类似,表示等待。也就是使用fork()后系统多了一个执行分支(线程),所以需要等待这个线程执行完毕,才有可能得到最终结果。
-
在实际使用中,如果毫无顾忌地使用fork()开启线程,那么很有可能导致系统因开启过多线程而严重影响性能。所以JDK给出了一个ForkJoinPool线程池,对于fork方法并不急着开启线程,而是提交给ForkJoinPool线程池处理,以节省系统资源。
-
使用Fork&Join进行进行数据处理的总体结构如下:
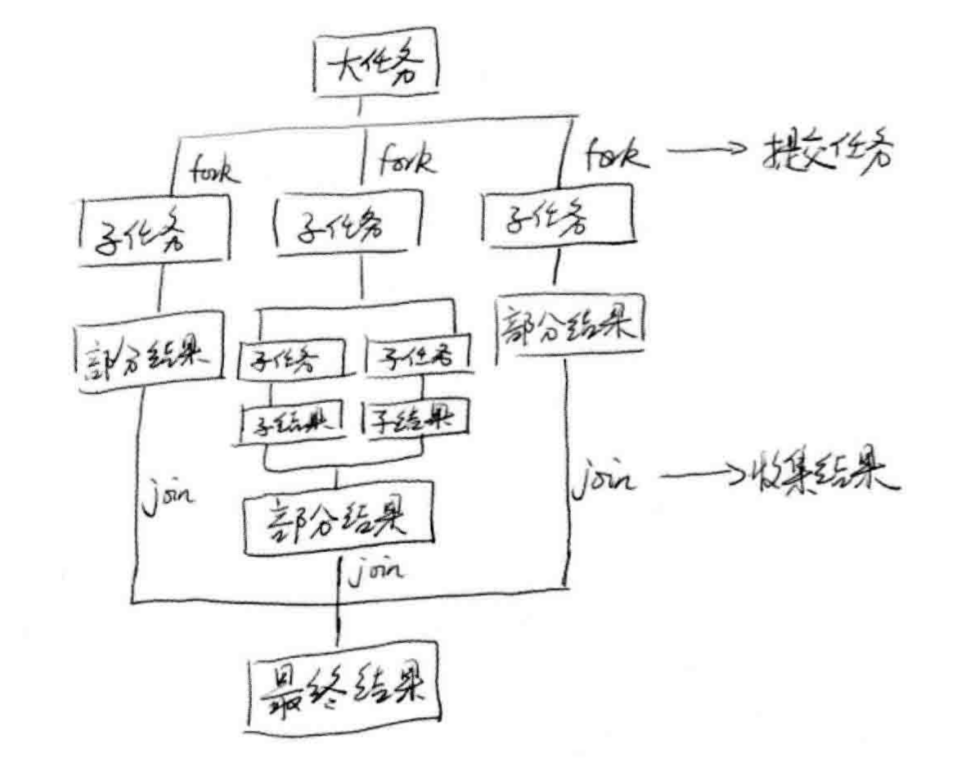 forkJoin.png-208.1kB
forkJoin.png-208.1kB
-
由于线程池的优化,提交的任务和线程数量并不是一对一的关系。在绝大多数情况下,一个物理线程实际上是需要处理多个逻辑任务的。因此,每个线程必然需要拥有一个任务队列。所以,可能遇到这样一种情况:线程A已经把自己的任务都执行完成了,而线程B还有一堆任务等着处理。此时,线程A就会“帮助”线程B,从线程B的任务队列中拿一个任务过来处理,尽可能地达到平衡。示意图:
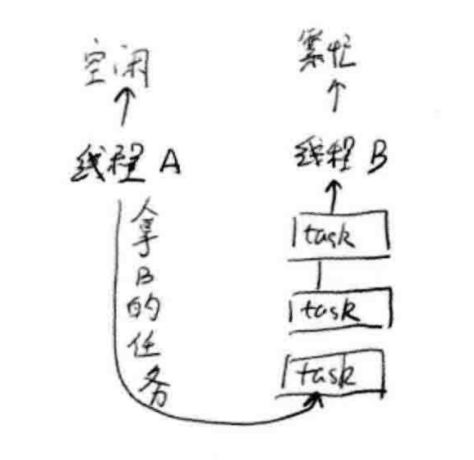 queue.png-63.8kB
queue.png-63.8kB
-
值得注意的是:当一个线程试图帮助另一个线程时,总是从任务队列的尾部拿数据,而线程试图执行自己的任务时,则是从头部开始拿。这是为了避免数据竞争。
2.ForkJoinPool 和 ForkJoinTask
- 先来看一下ForkJoinPool的一个重要的接口:
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task)
- 我们可以向ForkJoinPool线程池提交一个ForkJoinTask任务。
- 所谓ForkJoinTask任务就是支持fork()分解和join()等待的任务。
- ForkJoinTask有两个重要的子类:
- RecursiveAction:没有返回值的任务
- RecursiveTask:携带返回值的任务
- 下面通过一个计算数列求和的demo,来展示Fork&Join的使用:
public class Test {
public static class CountTask extends RecursiveTask<Long> {
private static final int THRESHOLD = 10000;
private long start;
private long end;
public CountTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long sum = 0;
boolean canCompute = (end - start) < THRESHOLD;
if (canCompute) {
for (long i = start; i <= end; i++) {
sum += i;
}
} else {
// 分成100个小任务
long step = (start + end) / 100;
ArrayList<CountTask> subTasks = new ArrayList<>();
long pos = start;
for (int i = 0; i < 100; i++) {
long lastOne = pos + step;
if (lastOne > end) {
lastOne = end;
}
CountTask subTask = new CountTask(pos, lastOne);
pos += step + 1;
subTasks.add(subTask);
subTask.fork();
}
for (CountTask t : subTasks) {
sum += t.join();
}
}
return sum;
}
}
public static void main(String[] args) throws Exception {
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Long> task = forkJoinPool.submit(new CountTask(0, 200000L));
try {
long result = task.get();
System.out.println("sum=" + result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
// 输出:
// sum=20000100000
- 上述代码在执行get()方法时,如果任务没有结束,那么主线程就会在get()方法上等待。
- 使用ForkJoin时要注意,如果任务的划分层次很深,一直得不到返回,那么可能出现两种情况:
- 系统内的线程数量越积越多,导致性能严重下降。
- 函数的调用层次变得很深,最终导致栈溢出。
- 此外,ForkJoin线程池使用一个无锁的栈来管理空闲线程。如果一个工作线程暂时取不到可用的任务,则可能会被挂起,挂起的线程将会被压入由线程池维护的栈中。待将来有任务可用时,再从栈中唤醒这些线程。
end











网友评论