author: Yong Zhang, Ph.D.
institution: Nanyang Technological University
email: yzhang067@e.ntu.edu.sg
license: MIT licensed. No commercial usage.
引子
本文简单介绍我发在IEEE Trans. on Cybernetics上的一篇论文,成果已不是最新,文章是2015年的工作,投稿周期较长导致最近才发表。此文不是推介,实乃当下正在找工作,需要对自己PhD期间做过的工作有个梳理。故,写与自己。
简介
就笔者所知,此文是第一次将multi-view learning和CNN结合到一起,新的model应用于抽取型文本摘要,在DUC的benchmark dataset上取得了state-of-art performance。在DUC2006数据集上,与literature里效果最好的方法相比,我们的model将Rouge-1, Rouge-2, 和Rouge-SU4三个metrics上的表现提高了1.28%,4.35%,和3.68%。我们工作的主要贡献如下:
- 首次利用multi-view learning的complementaty和concensus原则,提高CNN的学习能力,实验证明multi-view learning是CNN的一个可行方向。
- 利用pre-train word embedding matrix, 实现模型end-to-end可训练,不再需要feature engineering,模型易于使用。
- 首次提出sentence position embedding技术,提高文档摘要任务的准确率。
以下,笔者将从文档摘要,CNN,word embedding, multi-view learning几个方面做简单介绍。然后介绍文章提出的模型。
文档摘要
信息爆炸时代如何快速提取到有用信息非常重要,文档摘要作为信息提取领域的重要技术,长期以来一直备受关注,近年来随着机器学习的火热,越来越多的人尝试用机器学习来解决这一问题。文档摘要主要有两个分支:extractive summarization和abstractive summarization。前者直接提取文档活文集里的句子组合成最终的摘要,后者还需要做语法检查,语义重组等复杂处理。后者提取到的摘要与人工摘要更加类似,但是技术性复杂,本文focus在extractive summarization。我们首先将文档或文集分割成句子,然后利用我们的模型对每个句子建模并打分,之后根据句子得分排序,取分数居前的句子组合成最终摘要。最后的摘要有字数上线或者句子数目上限。此处值得提到的是,对于文集摘要任务,来自不同文档的句子可能十分相同(任务是针对相同topic的文档提取摘要)而且同时得分很高,我们将剔除重复性句子。完整的流程如下图:
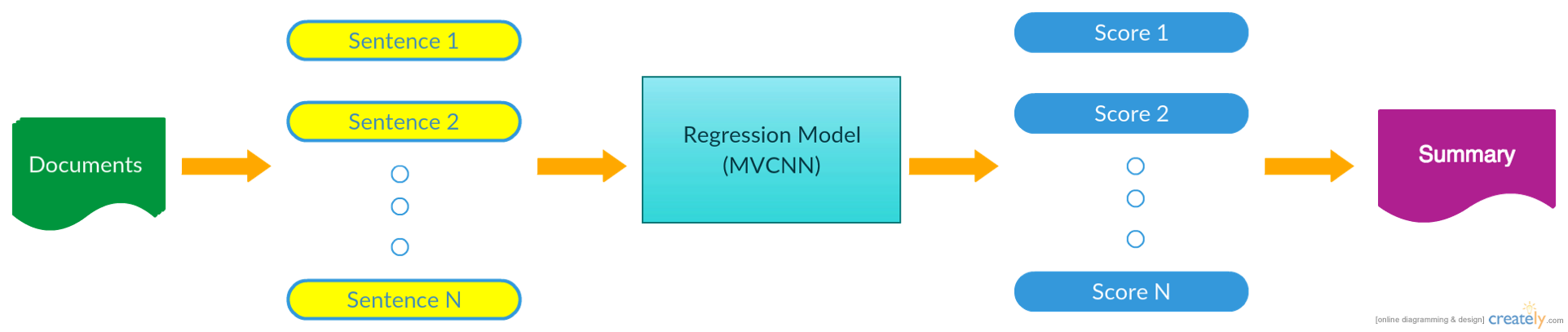 flowchart
flowchart
CNN
Convolutional Neural Network (CNN)可以说是近几年最火的算法之一了,凡做图像必用CNN,因为其良好的local representation的能力可以有效提取到图像的局部特征。最近CNN也被广泛应用到NLP领域,本证明学习能力依然出众。基本的CNN模型可以参见Stanford CS231n课程CNN for visual recogonition。本文使用的基本CNN结构包括两层convolution layer和一层max pooling layer。选择两层convolution layer的原因是相较于一层学习能力有较大幅度提升,而再增加层数效果提升并不明显却导致复杂度急剧上升。
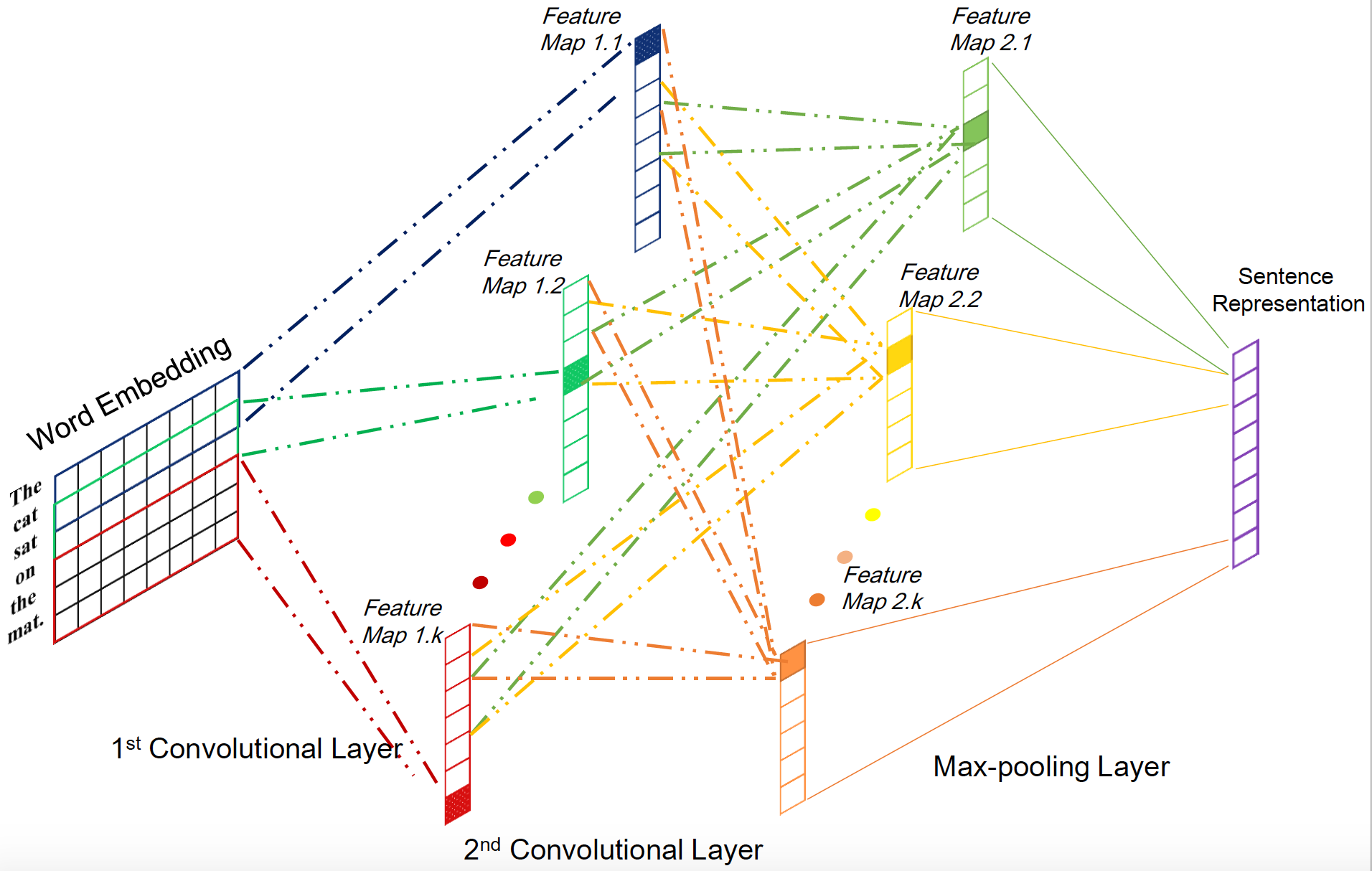 cnn_arch
cnn_arch
Word Embedding
词向量近年几乎已经为所有NLP任务使用,其将每个单词的向量表示映射到一个相对低维的空间,并且保存了词语的语义信息。下图将word embedding的空间降维到2-D平面方便可视化,我们可以发现具有类似语义的词在word embedding space里被聚集到了一起。更加有名的是,word embedding还提取到了词与词直接的关联,e.g., $vec(rance) - vec(Paris) = vec(China) - vec(Beijing)$。
 wordvec
wordvec
本文使用了pre-trained word2vec matrix作为词向量的初始化,然后在训练模型的时候通过SGD对词向量做更新,从而得到特定任务下的词向量,实验证明,利用在大语料Google News上训练的word embedding matrix做初始化可以显著提升预测能力。
Multi-view Learning
Multiview learning is a paradigm designed for problems,
where data come from diverse sources or feature subsets, also
known as, multiple views. It employs one function to model
a particular view and jointly optimizes all the functions to
exploit the redundant views of the same input data and improve
the learning performance [1].
Multi-view Learning从多角度去提取相同输入数据的信息,这一点人工摘要提取十分类似。人工摘要提取的时候,会让多个summarizer对同一个文档或文集做出总结,每个summarizer的认识角度都是不同的,提取出来的最终结果也会不尽相同。我们利用multi-view learning来模仿多个summarizer,利用complementary and consensus原则使文本信息得到最有效的提取和表示。
Multi-view learning的主要技术包括Co-training,Multiple kernel learning algorithms,和Subspace learning-based approaches。本文中使用的multi-view leanring类似于Multiple kernel learning,同时兼顾co-training的属性。
Mutliview lerning成功的关键在于两条原则,即complementary and consensus principles. 前者旨在利用数据隐含的互补的信息,后者则目的在于最大化不同views上训练得到的learners的一致性。
Methodology
我们的新模型成功将multi-view learning引入经典CNN模型,利用two-level的complementary principle和consensus principle提高了经典CNN模型的学习能力。我们的模型的整体架构如下图:
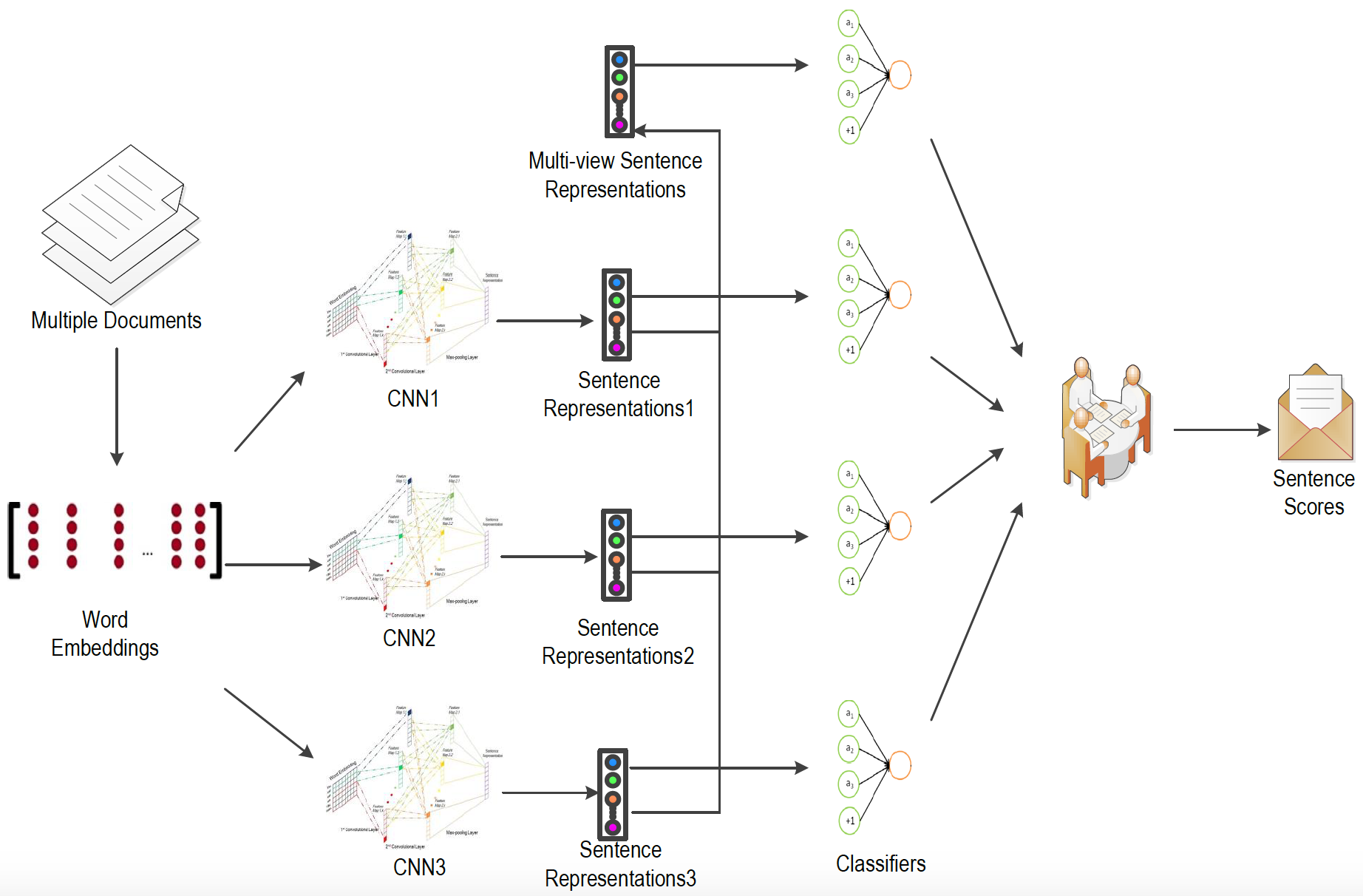 framework
framework
多个CNN(不同的filter window size, e.g., 3,5,7)被用于提取multiple views, 我们将每个CNN提取到的句子向量表示结合起来作为句子的最终表示,这个是intermediate stage的complementary principle。另一方面,我们也让每个CNN直接输出预测结果,然后将预测结果结合起来作为final stage的complementary principle。同时,我们也试图最大化各个CNN的预测结果的一致性,以满足consensus principle。
Complementary Principle
本文的multi-view learning类似于Multiple kernel learning,每一个CNN可以视作一个kernel,用以提取不同着眼点的信息。第一层complementary principle,也就是intermediate stage complementary对应上图的multi-view sentence representations, 可类比作不同的sumamrizers在相互交换意见后合作得到一个摘要。第二层complementary principle,也就是final stage complementary对应上图的圆桌图案,可类比作不同的summarizers在得到各自的摘要之后相互妥协以达成一致意见。我们的方法的解释性很高,同时我们也做出了一些理论证明。
Theorem 1: We denote the input as $\mathbf{x}$, real output as $y$ and the predicted output by a single CNN as $f(\mathbf{x})$. The multi-view CNN predicted output is weighted sum of the distinct CNNs' outputs. Then the expected mean squared error of the a single CNN is equal or greater than that of MV-CNN.
如下证明过程证明了complementary principle的有效性
 framework
framework
Concensus Principle
[2] 的作者证明两个独立假设的不一致性是每个假设的错误率的上限,用公式来将就是:
$$P(f_1 \neq f_2) \geq max(P(error(f_1)), P(error(f_2)))$$
因此提高两个假设之间的一致性可以减少各个假设的错误率。应用到我们的模型,降低各个CNN的不一致性有利于提高各个CNN的学习能力。假设各个CNN预测的sentence的分数为$f_i(\mathbf{x})$. 那么concensus principle可以表示为
$$min \sum_{\mathbf{x}}\sum_{i \neq j}(f_i(\mathbf{x})-f_j(\mathbf{x}))^2$$
损失函数
通常CNN模型的损失函数为
$$\mathbb{L} = -\sum_{\mathbf{x}}{yln(\mathbf{x})+(1-y)ln(1-\mathbf{x})}$$
$y$是每个句子的groud-true分数。由于我们的数据只有文档及其对应的人工摘要,并没有现成的句子分数,我们需要对数据进行预处理。我们将每个句子与其所在文档的摘要对比,使用文档摘要领域常用的performance metric, ROUGE来给每个句子打分。ROUGE通过统计人工摘要和自动摘要的重叠元素(n-gram), 词对,短语对等的数目来判断自动摘要的优劣。我们取用了最常用的$Rouge-1$和$Rouge-2$来获得group-true分数。Rouge分数的计算可以查看文章。
$$y={\alpha}R_1(\mathbf{x})+{(1-\alpha)}R_2(\mathbf{x})$$
我们的模型引入了complementary and concensus principles,所以需要对原始的损失函数做出改进
$$\mathbb{L} = -\sum_{\mathbf{x}}{yln(\sum_i u_if_i(\mathbf{x}))+(1-y)ln(1-\sum_i u_if_i(\mathbf{x}))} + \lambda \sum_{\mathbf{x}}\sum_{i \neq j}(f_i(\mathbf{x})-f_j(\mathbf{x}))^2$$
Sentence Selection
使用训练好的模型,我们可以给文档里的每一个句子打分,从而对句子排序。如果是单个文档,句子几乎不会重复,直接使用分数最高的句子作为最终的摘要是可行的。但是对于文集摘要任务,来自不同文档的句子可能十分相同(任务是针对相同topic的文档提取摘要)。如果重复性句子都得到了较高分数,他们都会被选进最终的摘要,这样摘要的可读性就变差了。而且由于摘要有字数限制,保留冗余信息,就必然减少有用信息。因此我们必须对排序后的句子加以选择。我们首先选择分数最高的句子放到摘要里,然后选择分数其次的句子,比较它和已经在摘要里的句子的相似性,如果相似性过高,这个句子就被剔除。再选择分数其次的句子,再做比较,以此类推。这里的相似性是比较句子表示向量的cosine similarity,当其小于一个阈值时,我们认定两个句子类似。
sentence position embedding
最后补充说明我们在文章中另一创新点sentence position embedding。
对于一个文档,句子所处的位置对于信息理解非常重要。例如,很多情况下,作者喜欢把重要信息或者概括性信息放在文章的开头或者结尾。在文档摘要的相关文献当中就有一个利用句子位置信息的方法,叫做LEAD。它使用每个文章的开头几个句子作为文章的摘要,也取得不错效果。为了利用好句子的位置信息,我们引入了sentence position embedding。为什么要引入sentence position embedding?
句子的位置信息可以用简单的自然数来表示,我们在意的是句子所在大概位置,所以可以按照下面的公式来表示句子位置信息。$S_{1:3}$表示文章中的前三句,$S_{-3:-1}$表示后三句,其他位置的句子统一用$2$来表示。这样的表示方法比较粗糙,但是也非常的简单,我们模型的最重要的一个目的就在于减少人工的feature engineering,所以我们使用了最简单而且直观的方法。
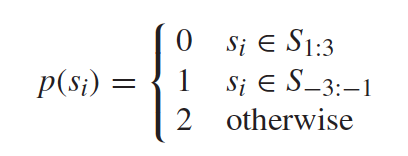 framework
framework
句子位置信息可以与CNN提取到的句子语义信息结合,一起作为顶层分类器(这里就是softmax classifier)的输入。CNN提取到的句子语义信息以vector的形式表现,在我们的model里这个vector的长度为300。如果我们只是用自然数和这个语义向量连接,句子位置信息很有可能被语义向量所淹没,因此我们借助embedding的思想将自然数映射到高纬度的空间。事实上,word embedding本身也是讲interger表示映射为dense vector表示的过程。此处,我们的sentence position embedding的维度定为了100,并且初始化为随机的,它也会在训练model的过程中被更新。
Experiment Results
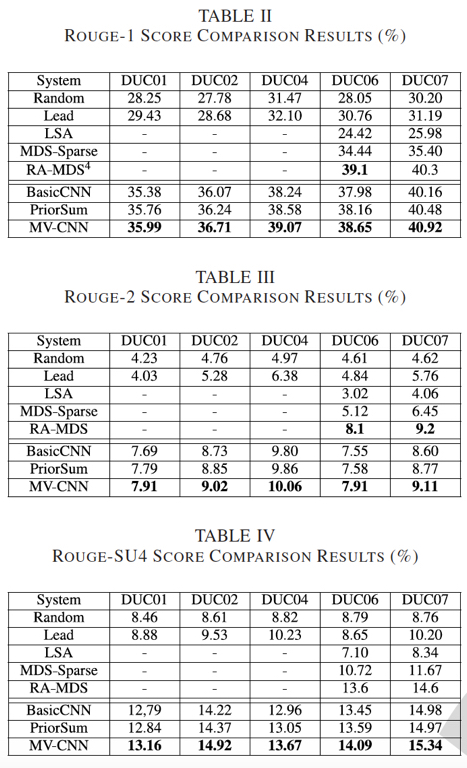
我们在DUC的五个dataset上检验了我们model的有效性,并与state-of-art的方法做了对比,结果如下图。我们在所有dataset上都取得了最优的结果[1]
 comparison
comparison
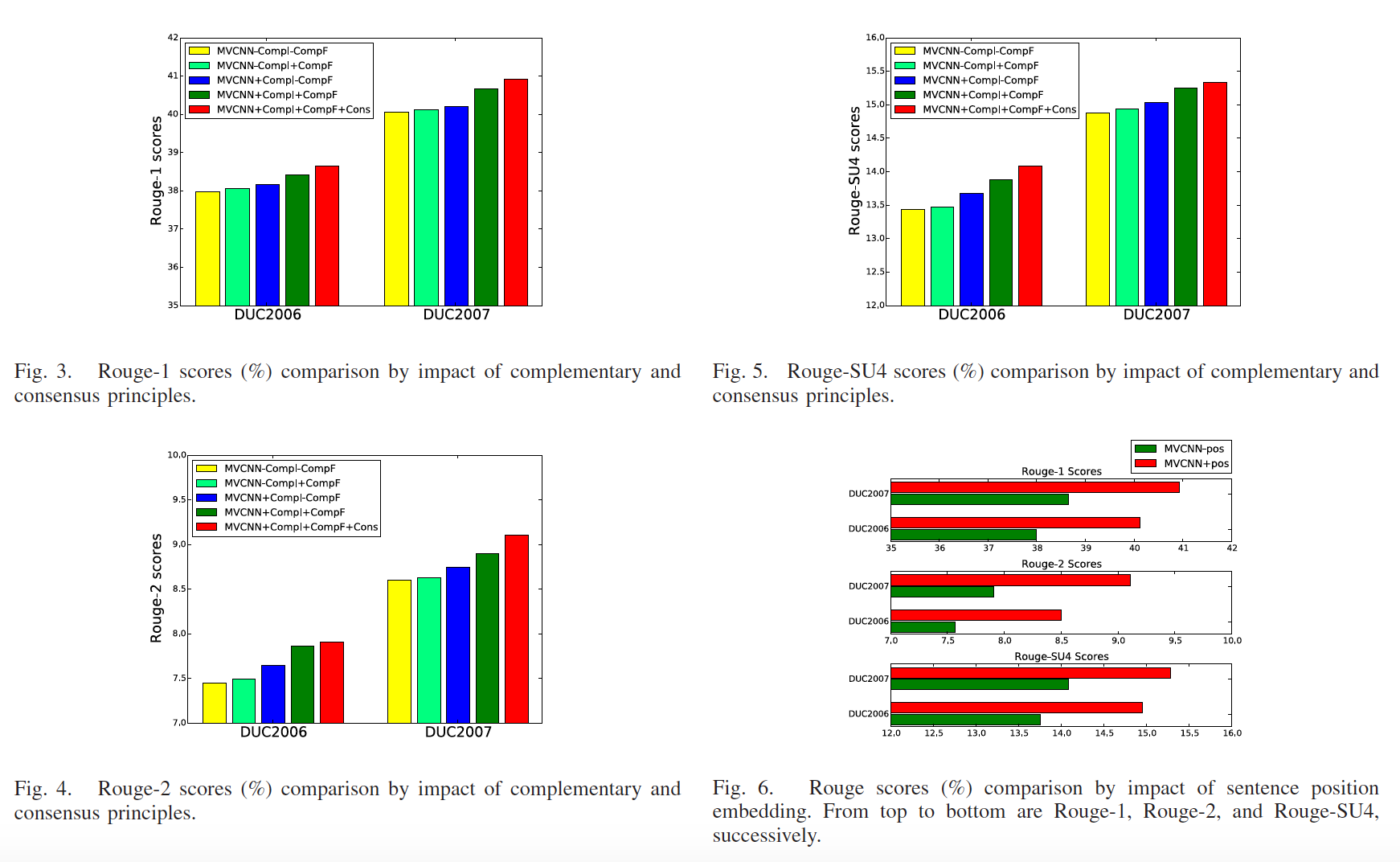
另外我们也验证了complementary和concensus principles的有效性, 从图3--5, 我们可以看到同时使用two-level compelmentary principle和concensus principle有助于提高学习能力。句子位置信息的重要性由图6中的结果证明。
 principle
principle
如果偶然间有读者看到此文,欢迎讨论。如需引用,参考以下。
@ARTICLE{7756666,\
author={Y. Zhang and M. J. Er and R. Zhao and M. Pratama},\
journal={IEEE Transactions on Cybernetics},
title={Multiview Convolutional Neural Networks for Multidocument Extractive Summarization},
year={2016},
volume={PP},
number={99},
pages={1-13},
keywords={Computational modeling;Computer vision;Data mining;Feature extraction;Machine learning;Neural networks;Semantics;Convolutional neural networks (CNNs);deep learning;multidocument summarization (MDS);multiview learning;word embedding},
doi={10.1109/TCYB.2016.2628402},
ISSN={2168-2267},
month={},}
Reference
[1] C. Xu, D. Tao, and C. Xu, “A survey on multi-view learning,” Neural
Comput. Appl., vol. 23, nos. 7–8, pp. 2031–2038, 2013.
[2] S. Dasgupta, M. L. Littman, and D. McAllester, “PAC generalization
bounds for co-training,” in Proc. Adv. Neural Inf. Process. Syst., vol. 1.
Vancouver, BC, Canada, pp. 375–382, 2001.
-
RA-MDS是DUC2006和DUC2007数据集上表现最佳的系统,它使用了更多的输入信息。这里它只是作为一个参考并不加入比较。 ↩












网友评论