基本概念
写在前面的几个问题
了解一个分布式系统好坏,可以从下面几个问题入手
- scale out水平扩展如何实现?
- 数据一致性如果保证?
- 高可用性如何实现?
- 异地多活,异地容灾如何实现?
- 分布式事物,分布式锁?
什么是集中式?什么是分布式?
集中式系统用一句话概括就是:一个主机带多个终端。终端没有数据处理能力,仅负责数据的录入和输出。目前银行等企业应用的多是集中式系统。
分布式系统是一个硬件或软件组件分布在不同的网络计算机上,每个节点都有一定的处理能力,彼此之间仅仅通过消息传递进行通信和协调的系统。
分布式工程实践难点
分布式系统降低了成本,提高了系统的带宽和容错性,但是带来了新的问题:就是工程实践的复杂性,它面临的较多问题:
- 消息传递异步无序(asynchronous):现实网络不是一个可靠的信道,存在消息延时、丢失,节点间消息传递做不到同步有序(synchronous)
- 节点宕机(fail-stop): 节点持续宕机,不会恢复
- 节点宕机恢复(fail-recover): 节点宕机一段时间后恢复,在分布式系统中最常见
- 网络分化(network partition): 网络链路出现问题,将N个节点隔离成多个部分
- 拜占庭将军问题(byzantine failure):节点或宕机或逻辑失败,甚至不按套路出牌抛出干扰决议的信息
我: 老王,今晚7点老地方,搓够48圈不见不散! ……
(第二天凌晨3点) 隔壁老王: 没问题! // 消息延迟
我: ......我: 小张,今晚7点老地方,搓够48圈不见不散!
小张: No ……
(两小时后……)
小张: No problem! // 宕机节点恢复
我: ......我: 老李,今晚7点老地方,搓够48圈不见不散!
老李: 必须的,大保健走起! // 拜占庭将军
(这是要打麻将呢?还是要大保健?还是一边打麻将一边大保健……)
CAP理论
CAP是Consistency、Availablity和Partition-tolerance的缩写。分别是指:
- 一致性(Consistency):每次都能保证数据的同步,是最新数据;
- 可用性(Availablity):每个请求都能接受到一个响应,无论响应成功或失败;
- 分区容忍性(Partition-torlerance):当节点间出现网络分区,照样可以提供服务。
CAP理论指出:CAP三者只能取其二,不可兼得。
可用性是必须要
一致性问题算法
- 两段式提交(2PC)
满足强一致性,实际举列
 Paste_Image.png
Paste_Image.png
经典列子:
1、牧师分别问新郎和新娘:你是否愿意……不管生老病死……
2、当新郎和新娘都回答愿意后(锁定一生的资源),牧师就会说:我宣布你们……(事务提交)
- 三段式提交(3PC)
 Paste_Image.png
Paste_Image.png
- Paxos协议
简单说来,Paxos的目的是让整个集群的结点对某个值的变更达成一致。Paxos算法基本上来说是个民主选举的算法——大多数的决定会成个整个集群的统一决定。任何一个点都可以提出要修改某个数据的提案,是否通过这个提案取决于这个集群中是否有超过半数的结点同意(所以Paxos算法需要集群中的结点是单数)。
数据分布算法
分布式系统如何拆解输入数据,把数据分布到各个节点,下面列出几种常见算法
- 哈希算法:这个很好理解,不做过多解释,扩展性不好;
- 按数据范围分布: 按照数据的特征值来划分不同的服务器
- 按数据量分布: 把数据划分为若干block,平均分配,但是需要管理较多元数据
- 一致性哈希:扩展性好但是节点较少时候容易造成数据倾斜
工程实践中常用算法是按数据量和一致性哈希结合
Google三架马车
1、分布式存储GFS ,google 有非常庞大的数据,几台甚至几百台大型服务器都无法存下,所以干脆采用廉价PC,保存在成千上万台上,这样节省了资源,但是由此也带来了很多问题,细想一下,把数据存储在很多机器上会带来什么问题?
首先我要知道我的文件存到了哪个PC上,一个PC坏了是不是我的数据就丢了?所以要进行备份,具体怎么备份,这个应该可以配置,比如某个数据要有几个备份,从而请求备份的时候要做负载均衡;修改某台PC的数据其它上面的数据也要跟着修改,否则数据就不一致了啊?
.......带着这些问题,想想google会怎么解决这些问题?对,他们就是GFS,GFS对开发者是完全透明的,我们对数据的删除,修改,等操作,是透明的,我们创建一个文件完全不必去考虑我们创建的文件放在哪儿了,对GFS帮忙做了,架构如下:
 Paste_Image.png
Paste_Image.png
2、BigTable说白了就是一个key/value 用惯了key/value的数据结构,比如一个hashMap (key,value) ,bigTable只不过是用(行,列,时间t)作为key,t一般用来保存数据的版本号;
 Paste_Image.png
Paste_Image.png
BigTable 提供针对行数据的事务操作,底层存储为GFS,直白点BigTable就是在GFS上的一个应用而已,类比windows的文件系统,sqlServer数据库系统就是建立在windows文件系统之上的,不同之处BigTable是个分布式的海量存储系统;关键点:子表,介绍到此为止,省略了太多的细节,深入点的话去看论文;
判断某个主键是否在某个子表时:用到算法Bloom Filter http://blog.csdn.net/jiaomeng/article/details/1495500
这种算法的特点:有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)。在增加了错误率这个因素之后,Bloom Filter通过允许少量的错误来节省大量的存储空间。
备注:GFS、BigTable 实时性应该不会很好
Paxos协议:http://zh.wikipedia.org/wiki/Paxos%E7%AE%97%E6%B3%95
3、数据都存储好了,接下来要进行计算了,map/reduce模型,负责将一个大任务,分配成许多小任务,然后分配到众多机器上去执行;底层怎么实现对开发者应该是透明的;我们需要注意的是如何将大任务进行map,如何进行reduce (即:如何将一个任务分配到许多机器上去执行,遵循什么原则)
工程实践
Hadoop
分布式系统起源于Google的分布式论文,但是其没有开源,由Apache公司工程实现了Google的论文。并且开源,迅速壮大。主要由下面子系统组成:
HBase -> Google Big Table
MapReduce
HDFS -> GFS
Zookeeper -> Chubby
系统架构
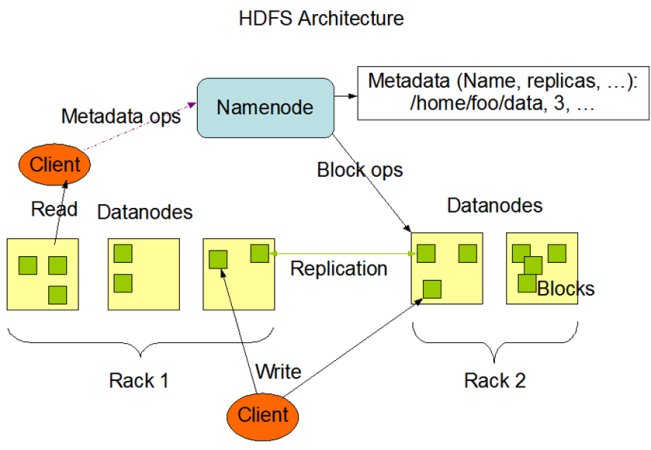 此处输入图片的描述
此处输入图片的描述











网友评论