文章作者:韩伟 — 腾讯游戏高级架构师, 版权归原作者所有,未经作者同意,请勿转载
文章来源:腾讯云技术社区——腾云阁:https://www.qcloud.com/community
原文链接:https://www.qcloud.com/community/article/165
任何的服务器的性能都是有极限的,面对海量的互联网访问需求,是不可能单靠一台服务器或者一个CPU来承担的。所以我们一般都会在运行时架构设计之初,就考虑如何能利用多个CPU、多台服务器来分担负载,这就是所谓分布的策略。分布式的服务器概念很简单,但是实现起来却比较复杂。因为我们写的程序,往往都是以一个CPU,一块内存为基础来设计的,所以要让多个程序同时运行,并且协调运作,这需要更多的底层工作。
首先出现能支持分布式概念的技术是多进程。在DOS时代,计算机在一个时间内只能运行一个程序,如果你想一边写程序,同时一边听mp3,都是不可能的。但是,在WIN95操作系统下,你就可以同时开多个窗口,背后就是同时在运行多个程序。在Unix和后来的Linux操作系统里面,都普遍支持了多进程的技术。所谓的多进程,就是操作系统可以同时运行我们编写的多个程序,每个程序运行的时候,都好像自己独占着CPU和内存一样。在计算机只有一个CPU的时候,实际上计算机会分时复用的运行多个进程,CPU在多个进程之间切换。但是如果这个计算机有多个CPU或者多个CPU核,则会真正的有几个进程同时运行。所以进程就好像一个操作系统提供的运行时“程序盒子”,可以用来在运行时,容纳任何我们想运行的程序。当我们掌握了操作系统的多进程技术后,我们就可以把服务器上的运行任务,分为多个部分,然后分别写到不同的程序里,利用上多CPU或者多核,甚至是多个服务器的CPU一起来承担负载。
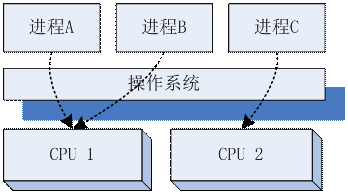
多进程利用多CPU
这种划分多个进程的架构,一般会有两种策略:一种是按功能来划分,比如负责网络处理的一个进程,负责数据库处理的一个进程,负责计算某个业务逻辑的一个进程。另外一种策略是每个进程都是同样的功能,只是分担不同的运算任务而已。使用第一种策略的系统,运行的时候,直接根据操作系统提供的诊断工具,就能直观的监测到每个功能模块的性能消耗,因为操作系统提供进程盒子的同时,也能提供对进程的全方位的监测,比如CPU占用、内存消耗、磁盘和网络I/O等等。但是这种策略的运维部署会稍微复杂一点,因为任何一个进程没有启动,或者和其他进程的通信地址没配置好,都可能导致整个系统无法运作;而第二种分布策略,由于每个进程都是一样的,这样的安装部署就非常简单,性能不够就多找几个机器,多启动几个进程就完成了,这就是所谓的平行扩展。
现在比较复杂的分布式系统,会结合这两种策略,也就是说系统既按一些功能划分出不同的具体功能进程,而这些进程又是可以平行扩展的。当然这样的系统在开发和运维上的复杂度,都是比单独使用“按功能划分”和“平行划分”要更高的。由于要管理大量的进程,传统的依靠配置文件来配置整个集群的做法,会显得越来越不实用:这些运行中的进程,可能和其他很多进程产生通信关系,当其中一个进程变更通信地址时,势必影响所有其他进程的配置。所以我们需要集中的管理所有进程的通信地址,当有变化的时候,只需要修改一个地方。在大量进程构建的集群中,我们还会碰到容灾和扩容的问题:当集群中某个服务器出现故障,可能会有一些进程消失;而当我们需要增加集群的承载能力时,我们又需要增加新的服务器以及进程。这些工作在长期运行的服务器系统中,会是比较常见的任务,如果整个分布系统有一个运行中的中心进程,能自动化的监测所有的进程状态,一旦有进程加入或者退出集群,都能即时的修改所有其他进程的配置,这就形成了一套动态的多进程管理系统。开源的ZooKeeper给我们提供了一个可以充当这种动态集群中心的实现方案。由于ZooKeeper本身是可以平行扩展的,所以它自己也是具备一定容灾能力的。现在越来越多的分布式系统都开始使用以ZooKeeper为集群中心的动态进程管理策略了。
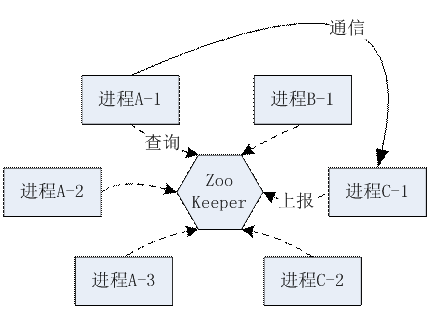
动态进程集群
在调用多进程服务的策略上,我们也会有一定的策略选择,其中最著名的策略有三个:一个是动态负载均衡策略;一个是读写分离策略;一个是一致性哈希策略。动态负载均衡策略,一般会搜集多个进程的服务状态,然后挑选一个负载最轻的进程来分发服务,这种策略对于比较同质化的进程是比较合适的。读写分离策略则是关注对持久化数据的性能,比如对数据库的操作,我们会提供一批进程专门用于提供读数据的服务,而另外一个(或多个)进程用于写数据的服务,这些写数据的进程都会每次写多份拷贝到“读服务进程”的数据区(可能就是单独的数据库),这样在对外提供服务的时候,就可以提供更多的硬件资源。一致性哈希策略是针对任何一个任务,看看这个任务所涉及读写的数据,是属于哪一片的,是否有某种可以缓存的特征,然后按这个数据的ID或者特征值,进行“一致性哈希”的计算,分担给对应的处理进程。这种进程调用策略,能非常的利用上进程内的缓存(如果存在),比如我们的一个在线游戏,由100个进程承担服务,那么我们就可以把游戏玩家的ID,作为一致性哈希的数据ID,作为进程调用的KEY,如果目标服务进程有缓存游戏玩家的数据,那么所有这个玩家的操作请求,都会被转到这个目标服务进程上,缓存的命中率大大提高。而使用“一致性哈希”,而不是其他哈希算法,或者取模算法,主要是考虑到,如果服务进程有一部分因故障消失,剩下的服务进程的缓存依然可以有效,而不会整个集群所有进程的缓存都失效。具体有兴趣的读者可以搜索“一致性哈希”一探究竟。
以多进程利用大量的服务器,以及服务器上的多个CPU核心,是一个非常有效的手段。但是使用多进程带来的额外的编程复杂度的问题。一般来说我们认为最好是每个CPU核心一个进程,这样能最好的利用硬件。如果同时运行的进程过多,操作系统会消耗很多CPU时间在不同进程的切换过程上。但是,我们早期所获得的很多API都是阻塞的,比如文件I/O,网络读写,数据库操作等。如果我们只用有限的进程来执行带这些阻塞操作的程序,那么CPU会大量被浪费,因为阻塞的API会让有限的这些进程停着等待结果。那么,如果我们希望能处理更多的任务,就必须要启动更多的进程,以便充分利用那些阻塞的时间,但是由于进程是操作系统提供的“盒子”,这个盒子比较大,切换耗费的时间也比较多,所以大量并行的进程反而会无谓的消耗服务器资源。加上进程之间的内存一般是隔离的,进程间如果要交换一些数据,往往需要使用一些操作系统提供的工具,比如网络socket,这些都会额外消耗服务器性能。因此,我们需要一种切换代价更少,通信方式更便捷,编程方法更简单的并行技术,这个时候,多线程技术出现了。
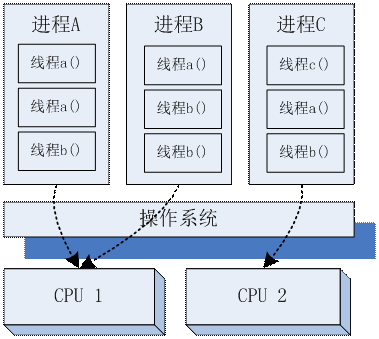
在进程盒子里面的线程盒子
多线程的特点是切换代价少,可以同时访问内存。我们可以在编程的时候,任意让某个函数放入新的线程去执行,这个函数的参数可以是任何的变量或指针。如果我们希望和这些运行时的线程通信,只要读、写这些指针指向的变量即可。在需要大量阻塞操作的时候,我们可以启动大量的线程,这样就能较好的利用CPU的空闲时间;线程的切换代价比进程低得多,所以我们能利用的CPU也会多很多。线程是一个比进程更小的“程序盒子”,他可以放入某一个函数调用,而不是一个完整的程序。一般来说,如果多个线程只是在一个进程里面运行,那其实是没有利用到多核CPU的并行好处的,仅仅是利用了单个空闲的CPU核心。但是,在JAVA和C#这类带虚拟机的语言中,多线程的实现底层,会根据具体的操作系统的任务调度单位(比如进程),尽量让线程也成为操作系统可以调度的单位,从而利用上多个CPU核心。比如Linux2.6之后,提供了NPTL的内核线程模型,JVM就提供了JAVA线程到NPTL内核线程的映射,从而利用上多核CPU。而Windows系统中,据说本身线程就是系统的最小调度单位,所以多线程也是利用上多核CPU的。所以我们在使用JAVA\C#编程的时候,多线程往往已经同时具备了多进程利用多核CPU、以及切换开销低的两个好处。
早期的一些网络聊天室服务,结合了多线程和多进程使用的例子。一开始程序会启动多个广播聊天的进程,每个进程都代表一个房间;每个用户连接到聊天室,就为他启动一个线程,这个线程会阻塞的读取用户的输入流。这种模型在使用阻塞API的环境下,非常简单,但也非常有效。
当我们在广泛使用多线程的时候,我们发现,尽管多线程有很多优点,但是依然会有明显的两个缺点:一个内存占用比较大且不太可控;第二个是多个线程对于用一个数据使用时,需要考虑复杂的“锁”问题。由于多线程是基于对一个函数调用的并行运行,这个函数里面可能会调用很多个子函数,每调用一层子函数,就会要在栈上占用新的内存,大量线程同时在运行的时候,就会同时存在大量的栈,这些栈加在一起,可能会形成很大的内存占用。并且,我们编写服务器端程序,往往希望资源占用尽量可控,而不是动态变化太大,因为你不知道什么时候会因为内存用完而当机,在多线程的程序中,由于程序运行的内容导致栈的伸缩幅度可能很大,有可能超出我们预期的内存占用,导致服务的故障。而对于内存的“锁”问题,一直是多线程中复杂的课题,很多多线程工具库,都推出了大量的“无锁”容器,或者“线程安全”的容器,并且还大量设计了很多协调线程运作的类库。但是这些复杂的工具,无疑都是证明了多线程对于内存使用上的问题。

同时排多条队就是并行
由于多线程还是有一定的缺点,所以很多程序员想到了一个釜底抽薪的方法:使用多线程往往是因为阻塞式API的存在,比如一个read()操作会一直停止当前线程,那么我们能不能让这些操作变成不阻塞呢?——selector/epoll就是Linux退出的非阻塞式API。如果我们使用了非阻塞的操作函数,那么我们也无需用多线程来并发的等待阻塞结果。我们只需要用一个线程,循环的检查操作的状态,如果有结果就处理,无结果就继续循环。这种程序的结果往往会有一个大的死循环,称为主循环。在主循环体内,程序员可以安排每个操作事件、每个逻辑状态的处理逻辑。这样CPU既无需在多线程间切换,也无需处理复杂的并行数据锁的问题——因为只有一个线程在运行。这种就是被称为“并发”的方案。

服务员兼了点菜、上菜就是并发
实际上计算机底层早就有使用并发的策略,我们知道计算机对于外部设备(比如磁盘、网卡、显卡、声卡、键盘、鼠标),都使用了一种叫“中断”的技术,早期的电脑使用者可能还被要求配置IRQ号。这个中断技术的特点,就是CPU不会阻塞的一直停在等待外部设备数据的状态,而是外部数据准备好后,给CPU发一个“中断信号”,让CPU转去处理这些数据。非阻塞的编程实际上也是类似这种行为,CPU不会一直阻塞的等待某些I/O的API调用,而是先处理其他逻辑,然后每次主循环去主动检查一下这些I/O操作的状态。
多线程和异步的例子,最著名就是Web服务器领域的Apache和Nginx的模型。Apache是多进程/多线程模型的,它会在启动的时候启动一批进程,作为进程池,当用户请求到来的时候,从进程池中分配处理进程给具体的用户请求,这样可以节省多进程/线程的创建和销毁开销,但是如果同时有大量的请求过来,还是需要消耗比较高的进程/线程切换。而Nginx则是采用epoll技术,这种非阻塞的做法,可以让一个进程同时处理大量的并发请求,而无需反复切换。对于大量的用户访问场景下,apache会存在大量的进程,而nginx则可以仅用有限的进程(比如按CPU核心数来启动),这样就会比apache节省了不少“进程切换”的消耗,所以其并发性能会更好。
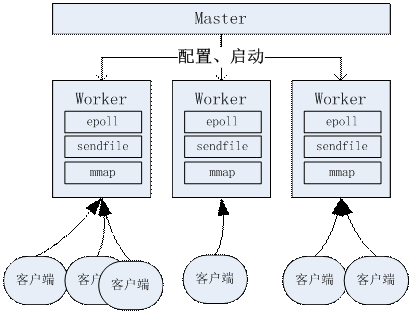
Nginx的固定多进程,一个进程异步处理多个客户端
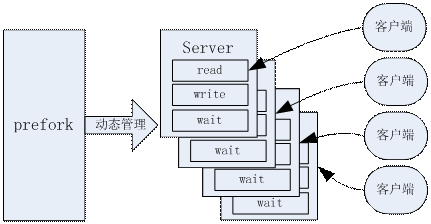
Apache的多态多进程,一个进程处理一个客户
在现代服务器端软件中,nginx这种模型的运维管理会更简单,性能消耗也会稍微更小一点,所以成为最流行的进程架构。但是这种好处,会付出一些另外的代价:非阻塞代码在编程的复杂度变大。












网友评论