(这是很早之前写的但内容没有太过时,发到这边补全一下...)
面向初学者介绍Python相关的一些工具,以及可能遇到的常见问题。
引言
在这里我假设你已经看完了一篇Python教程,基本熟悉了Python的结构和语法,在命令行下的Python互动环境中尝试过大部分Python的语句,觉得Python是个不错的语言准备继续下去。那么本篇文章会就Python实际运用中相关工具的选择,包括IDE,调试套件,第三方库管理工具这些进行介绍。另外还会对某些中文环境下容易遇到的问题,例如unicode编码解码的问题进行说明。本文主要是针对 Windows 环境下的 Python 开发进行说明。文章的目的是为了分享些我觉得很有用的经验和例子,若发现文中有疏漏之处请务必联系我。谢谢。
Python 语言介绍
Python 是一个近些年在开始流行起来的计算机编程语言。根据Python官网上的简介,Python主要特性包括跨平台,免费,简单且容易维护。就我个人理解来说,Python是一门适合大部分人的语言,因为各种类型的第三方库都有,所以像简单桌面程序,动态网站开发,图像处理,表格处理,甚至自动发帖机这些小应用在简单的学习后,不需要很深厚的编程经验的人应该都能自己做出来。
一些流行的Python教程有:
-
Dive into Python 面向有一定编程基础的同学。另外还有Dive into Python 3,针对Python3的教程。
-
Learn Python The Hard Way,书中主要是通过各种练习来进行学习,面向完全没有编程经验的同学。
-
Invent Your Own Computer Game With Python,让你一上手就做个游戏出来的教程,厉害吧。
-
The Python Tutorial,官方文档中的教程,正统而完整。
如果你还没有开始接触 Python ,或者觉得还不够熟悉,那么不妨找一份你觉得看得下去的教程开始学习吧。就我个人经验来说,Python 是我到目前为止觉得学的最划得来的一门语言,也是日常用的最多的一门,而事实上你并不需要了解完全了解 Python 就能在开始使用它。
Python 版本选择,其他发行版
Python 2 与 3
Python 2 和 3 系列的选择可能是比较让人烦躁的事情。其实区别很简单:Python 3.x 各个方面都更好,但语法与 Python 2.x 很大部分不兼容。Python 2.x 已经停止继续开发。但是目前很多第三方库仍然不支持 Python 3 , 文章后面介绍的很多工具,特别是科学计算的库仍然只支持 Python 2.x。
原来这里写的推荐版本是 2.6,现在的情况是 2.7 版本是 2.x 系列最后一个大版本号,以后只会有 2.7.x 的维护版本并不再会添加新功能。Python 3 现在已经足够成熟,很多常见的库都已经移植到 Python 3 上了。所以现在如果你是自己学 Python 那么上来直接 Python 3 没啥问题,但如果你是在工作的地方或者对科学计算有要求那么还是需要 Python 2.7 比较好。
这里我发现有一个比较靠谱的选择办法,就是看 Python(x,y) 带的 Python 版本。它现在还是在 2.7,这个版本基本上所有的第三方库都在支持。当哪一天 Python(x,y) 上到 Python 3 了那估计就是可以安心用 Python 3 的时候了。但按现在这个情况估计还得好几年吧。
发行版
目前在 Windows 下除了官方提供的安装版外,还有:
ActivePython ,这个与官方版本的区别在于提供了额外的库和文档,并且自动设置了PATH环境变量(后文会详细提到)
Python(x,y),这个是我一直用并且推荐给别人用的版本。从名字就能看出来这个发行版附带了科学计算方面的很多常用库,另外还有大量常用库比如用于桌面软件界面制作的 PyQt, 还有文档处理,exe文件生成等常用库。另外的还有大量的工具如IDE,制图制表工具,加强的互动shell之类。很多下文提到的软件在此发行版中都有附带。其他方面,Python(x, y)还附带了手工整理出的所有库的离线文档,每个小版本升级都提供单独的补丁。总的来说是很用心维护的一个发行版,十分建议安装这个版本。
Conda, 一个类似 Python(x, y) 的轻量级发行版。他支持的库稍微少一点但是常用的也基本包括了,它提供了一个额外的包裹管理命令还支持 Python 3.x,同时提供简洁版的 Miniconda 供自己手动选择库进行下载。
开发相关工具
首先,你需要一份文档
对于 Python 这样的语言,你觉得你学到什么时候算是完全掌握呢?你也许会想也许哪一天你记得大部分函数的名字很怎么用,不用打几行就 Google 搜一下的时候,就算学会了。这样的理解对了一半,等你熟悉 Python 以后你的却不应该常搜索;但前一半却不一定,我个人认为你并不需要记住庞大的标准库中的内容,很多时候你只要清楚要在哪里能找到相应的文档就行了。
Python 在这方面可以说是做的非常非常非常好。在真正着手开发之前,你应该在下载一份离线的文档。在这个页面(如果打不开的话试试这里,你懂的)下载一份 HTML 格式的,比如是 2.7.3 版那么对应的文档名字应该是 python-2.7.3-docs-html.zip。下好后把它在一个你喜欢的地方解压出来,打开其中的 index.html,这就是这个文档的主页。你可以看到他分为很多部分,包括语言的参考,标准库和其他很多方便的文档。
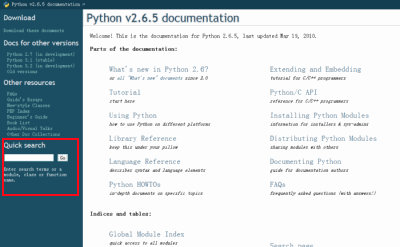 Python 文档
Python 文档
如果你一下不知道从哪里看起,这份文档还有一个非常棒的功能。看到左边的 Quick Search 栏,我在上图中也有标注起来。当你需要对某个函数或者标准库进行进一步了解的时候,你可以在这边来进行搜索。这里的搜索是火星科技驱动的离线状态下也能够使用的!比如输入 urllib.urlencode,你可以很方便的找到它对应的页面。基本有了这份文档,你可以避免掉很多疯狂搜索的情况。同样的,当你使用某个第三方库的时候,你最好也在他的站点上找找有没有一份离线文档,因为 Python 项目很多都有着很赞的文档。
开发环境的选择
如果你选择用 IDE 的话,现在的选择就非常多了,包括 PyCharm, Python Tools for Visual Studio。你也可以硬派一点用一个文本编辑器直接写。但我强烈建议不要使用 Python 发行版自带的那个 IDLE。开发者没有真的认为谁会仔细用那它,一直以来没有什么新功能,运行效率不行,而且会出诡异的问题(比如会报什么 socket 错误 )。希望你花些时间找个顺手的工具,只要不是 IDLE 就可以。
选择 PyDev 作为 IDE
Python 集成开发环境的选择好像一直以来也是一个很难抉择的问题。在尝试过很多个工具后我发现基于 Eclipse 的 PyDev 绝对是功能最为完整的一个 IDE 。除了断点调试之外,PyDev 的代码自动补全可能是现在这类 IDE 中最强力的。
如果你安装了 Python(x, y) 的话,PyDev 就已经在你的机器上了。如果没有的话请按照这篇文章来进行安装。
设置上有一些需要注意的地方。首先在打开 PyDev ,打开菜单中 Window -> Preferences,在弹出对话框中左边找到 PyDev -> Editor -> Code Completion。这里可以设置代码自动补全的相关信息。可以降低 Autocompletion delay 来更早的提示代码,并且将 Request completion on 系列尽可能勾上,让 PyDev尽可多的提示代码。
之后再找到 Interpreter Python 选项卡,这里可以设置所谓 Forced Buildins,可以强制引入某些第三方库从而完成代码补全。就我的经验来看大部分第三方库在这样设置后都能进行基本的补全。具体的做如图中,选择到对应的选项卡,点击 New,并输入你需要的模块名字即可。
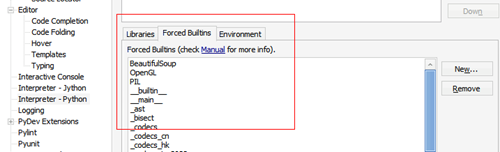 Forced Buldins设置
Forced Buldins设置
设置后总体效果绝对是同类IDE中比较好的:
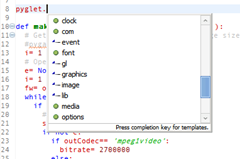 Eclipse 补全效果
Eclipse 补全效果
IPython 替代 Python Shell
在学习 Python 的时候应该都接触过 Python 的 Shell,能够输入 Python 语句并且立即返回结果。而 IPython就是一个豪华加强版的 Python Shell。如果你安装了 Python(x, y) 的话,那 IPython 已经在你的机器上了。如果没有的话那么请在这里下载 Windows Installer 进行安装。在安装这个之后还需要安装 pyreadline 让 IPython 开启高亮和自动补全功能。
之后你在命令行下需要 python 的时候改为输入 ipython 就能使用它了。开启 IPython 看看,首先感觉的不同应该是这个是有颜色的。我们来看看它提供的一些基础而实用的功能吧。首先是自动补全,一种是简单的关键字补全,另外一种是对象的方法和属性补全。作为例子,我们先引入 sys 模块,之后再输入 sys. (注意有个点),此时按下 tab 键,IPython 会列出所有 sys 模块下的方法和属性。因为是在互动模式下进行的,此时的 Python 语句实实在在的被执行了,所以对普通 object 的补全也是很完好的。
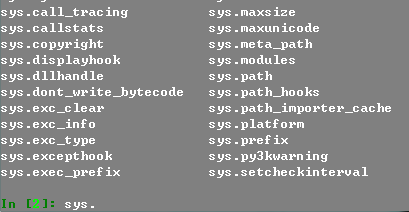 IPython
IPython
接着上面的例子,我们输入 sys?,这样会显示出 sys 模块的 docstring及相关信息。很多时候这个也是很方便的功能。
IPython 实用技巧
这里再介绍下 IPython 使用中的一些实用功能。在学习 Python 时你可能看到在循环或者函数返回时可以赋值给 _ 来表示忽略某个返回值。其实这只是一个常用的习惯。事实上 _ 是一个合法的变量名,而且在 Python shell 下 _ 总是被赋予之前最后一个输出的值。这里看个例子应该就能清楚:
>>> import string
>>> string.letters
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
>>> print _
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
举个实际的例子,比如你在调试时读文件的时候直接进行 f.read() ,你看了看发现输出结果很有意思,想要对它进行进一步处理,但发现读的时候忘记赋值了。以往你只能叹叹气重新开文件再读一次,现在你只要执行 result = _,把 _ 附到另外一个变量就可以了。
IPython 还有强大之处很大部分还体现在它的 magic function 中。它是指的在 IPython 环境下执行以 % 开头的一些命令来对 IPython 进行一些设定或者执行某些功能。在 IPython 中输入 %lsmagic 就能列出所有的 magic functions。在这里简单介绍下几个比较有意思的,你也可以自己通过查看文档来找找有哪些你特别用的到得。
-
之前看到能用
?来查询函数的文档,对于 magic function 也是如此。比如%run?。 -
!cd ..在命令前面加上!则它会被作为命令行命令执行,这样你就不用退出 IPython 来进行命令行操作。 -
%run foo.py在当前环境下直接执行foo.py,效果跟命令行下调用ipython foo.py相同。 -
%time foo.bar()跟timeit decorator作用相同,进行简单的 profile。 -
%hist能显示之前输入过的命令的历史,同时你可以用In[<linenumber>]来访问之前的命令。比如%exec In[10]就能执行列表中第十行。 -
%rep类似上面的_变量,但是是以字串的形式返回 -
最后,如果
%automagic是打开的状态的话,所有 magic function 不需要在前面加%就能正确调用。
在当前 IPython 版本中还有一个由于安全原因没有默认引入的 %autoreload,它的作用是在可以自动重新载入你调用的函数,以及其相关模块。接触过 django 的同学对这个应该比较熟悉,在 IPython 中的效果就是,当你在调试一个一直在反复改动的函数时,你可以开启这个功能保证每次调用都会重新读取最新的版本,让你在源码中的改动马上生效。在 IPython 中执行
import ipy_autoreload
%%autoreload 2
这样 IPython 会对所有的模块都进行 autoreload。你可以通过执行 %autoreload? 来查询它的文档来进行进一步设定。如果你希望 IPython 每次启动自动载入次功能,那么可以通过配置 ipythonrc (在 Windows 下可以在 C:\Users\<username>\_ipython\ipythonrc.ini 找到) 来进行相关设置。
最后还有一个很神奇的功能。如果你的程序是由命令行开始执行的,即在命令行下输入 python foo.py(大部分 Python 程序都是),那么你还可以利用 IPython 在你的程序任意地方进行断点调试!在你程序中任意地方,加入如下语句:
from IPython.Shell import IPShellEmbed
IPShellEmbed([])()
注意:最近 IPython 发布了 0.11 版本,各方面变化都非常大,API 也经过了重新设计。如果你使用的是 0.11 那么上面两行对应的是这样的:
from IPython import embed
embed()
再和平常一样运行你的程序,你会发现在程序运行到插入语句的地方时,会转到 IPython 环境下。你可以试试运行些指令,就会发现此刻 IPython 的环境就是在程序的那个位置。你可以逐个浏览当前状态下的各个变量,调用各种函数,输出你感兴趣的值来帮助调试。之后你可以照常退出 IPython,然后程序会继续运行下去,自然地你在当时 IPython 下执行的语句也会对程序接下来的运行造成影响。
这个方法我实在这里看到的。想象一下,这样做就像让高速运转的程序暂停下来,你再对运行中的程序进行检查和修改,之后再让他继续运行下去。这里举一个例子,比如编写网页 bot ,你在每取回一个页面后你都得看看它的内容,再尝试如何处理他获得下一个页面的地址。运用这个技巧,你可以在取回页面后让程序中断,再那里实验各种处理方法,在找到正确的处理方式后写回到你的代码中,再进行下一步。这种工作流程只有像 Python 这种动态语言才可以做到。
pip 管理第三方库
Python 的一大优势就是有极为大量的第三方库,包括各个方面的引用。然而安装第三方库对没有掌握方法的同学来说会变得很让人烦恼。事实上 Python 第三方库的安装和管理有着一个一个唯一正确的做法,这个做法要求你什么其他的都不用干,只要输入你要安装库的名字就可以了。
setuptools 也包在 Python(x, y) 当中。如果没有的话,要首先先安装 setuptools ,这个其实就是一个安装第三方库的软件。选择对应版本的 Windows Installer 进行下载和安装后,打开一个命令行窗口,输入:
easy_install pip
如果提示找不到程序,那么说明你当前没有设定好环境变量。安装官方提供的 Python 安装包的话肯定会有这个问题,而且很可能暂时不会修正,这就是牛逼程序员的倔强。具体做法是 右键我的电脑 - 属性 - 高级系统设置 - 环境变量 - 将 C:\python2*\Scripts 加入到 PATH 那一组当中。这样做的效果就是在任何地方的命令行下输入命令,那么系统会额外查找我们设定的那个目录中的内容。之后再执行上面的命令,装好了以后我们就要弃用 setuptools,转投 pip。要安装任何一个库,你只要找到他的名字(不需要版本号),用 pip 安装即可。譬如安装 django,那么输入如下命令即可:
pip install django
其实之前 easy_install 跟 pip 效用是类似的,都是在官方的第三方库索引 PyPI 查询信息并进行下载和安装。pip 的优势在于支持更高级的功能,譬如虚拟环境,安装失败不会残留破损的库,更重要的是 pip 还可以进行卸载。输入下面命令就能卸载一个之前由 pip 进行安装的库。继续上面的例子,现在要卸载 django:
pip uninstall django
这是 setuptools 所缺失的功能。需要额外说明的是大部分纯 Python 的库都能用这个方法在 Windows 下装上,但是需要编译 C 语言模块的一般都不太可能成功。遇到这种情况,在相应的库德站点上找找有没有对应的 Windows 安装包。
用 virtualenv 构建虚拟 Python 环境
如果你使用过 Python 做过 Web 开发,或者你有需求在本机上安装多个版本的 Python 来测试你的代码能否跑再 2.5, 2.6, 2.7 各个版本上,或者你的不同项目依赖于一个第三方库的不同版本;再或者,有时候你就是想要一个没有之前安装过的乱七八糟的库,一个干净的 Python 环境。这种时候 virtualenv 就能帮上你的忙。它能利用安装好的 Python ,在同一台机器上建立一个或多个互不相干的虚拟 Python 环境,且能随时切换。如果你看到这里还不觉得这个有什么用处,那不妨看下去留下点印象,等哪天你有这类需求的时候能找到这个简单实用的工具。
和其他第三方库一样,我们可以通过 pip 轻松安装:
pip install virtualenv
安装完成后你可以开启一个命令行窗口,输入 virtualenv 看看能不能找到这个脚本。如果有问题的话,请按照上面介绍过的步骤检查下是否设置好了 PATH。之后我们可以在一个方便的地方建立一个虚拟环境。建立 C:\envs\ 文件夹,命令行下 cd 到该文件夹中,输入:
virtualenv --no-site-packages --python=C:\Python26\python.exe envtest
之后应该会看到一个叫 envtest 的文件夹。这就是一个新建立的虚拟环境(virtual enviroment)。我们不妨先激活它来看看应该怎么用。命令行下执行 envtest\Scripts\activate.bat,这时是你会发现命令行变成这个样子:
(envtest) c:\>
提示符前面的 (envtest) 就是该环境已被激活的标志。这样你就可以在这个虚拟环境下进行工作了。执行 pip freeze ,你会发现... 你会发现什么都没有啊。执行 pip help,你可以看到 pip freeze 是输出当前 Python 环境下已经安装的所有第三方库。因为我们创建此环境时开启了选项 --no-site-packages,意思就是在创建此虚拟环境中不从系统 Python 中把已经安装了的库也安装到这里来,所以这里是一个干净的新 Python 环境。你可以在这里调用 pip 或者 easy_install 来安装各种你需要的库到这个环境中来,而不会影响到你系统中 Python 的情况,所以说它是一个虚拟的 Python 环境。
我们再回头看下 envtest 目录的结构,其下面的 Scripts 目录中有 python.exe pip.exe 这些程序,在虚拟环境已激活的情况下,你调用 python 或者 pip 都是调用的此目录中的程序。此时系统中的 python.exe 被 virtualenv 通过设置环境变量隐藏了起来。而 Lib 目录下就是存放各种新安装的库。
到这里你应该已经对 virtualenv 基本操作已经了解了,下面讲些使用上的注意事项:
-
调用
activate.bat开启虚拟环境,你也可以用同目录下的deactivate.bat来退出该虚拟环境。 -
建立虚拟环境时的参数
--python=C:\Python26\python.exe是用来指定你想使用 Python 程序位置,所以你可以建立多个虚拟环境来指向多个 Python 版本。另外你要注意的是如果你在系统上安装了多个版本的 Python, 你最先安装的一个版本会被当做主要版本,你在命令行下打python时,调用的就是最先安装的一个版本。其实这个是按照 PATH 中设定的路径位置来确定的,你最好把你需要主要使用的版本相关路径放在 PATH 环境变量中最前面。比如我的机器上,就是把C:\Python26和C:\Python26\Scripts作为 PATH 最前面两个。这样应该就能让保证你主要版本的正常使用。 -
当你在一个虚拟环境下工作时,假如你想在当前环境下来执行一个 Python 程序,这时你在命令行下必须执行
python foo.py,这样 foo.py 才会在你当前已经激活的 virtualenv 下执行。作为比较如果你直接执行foo.py那么它仍然时在系统环境下执行的。
另外,Linux 下可以使用 virtualenvwrapper 来进行方便的管理和切换各个环境,可惜的是这东西在 Windows 下用不了。但幸好有一个简单的脚本 envdotpy 来帮助你使用。把 env.py 放到 PATH 上的目录内,譬如 C:\Python26\Scripts 下。之后先打开里面的 DEFAULT_DIR_PATH 变量,把它改成你集中存放 virtualenv 的地方,在我们上面的例子中就可以把这行改为:
DEFAULT_DIR_PATH = "C:\\envs\\"
之后你就不需要专门 cd 到这个目录,而可以在任意路径上通过 env.py 来进行激活,切换,退出 virtualenv 了。例如执行: env.py envtest 就能激活 envtest 。执行 env.py -q 就能退出任意一个 virtualenv。
Winpdb 进行可视化调试
如果你使用的 PyDev 的话那么用其自带的断点调试应该就可以了。Winpdb则是为用其他简单编辑器进行 Python 开发的用户提供一个熟悉的调试环境。Winpdb不出意料的也在 Python(x, y)当中。所以如果装上 Python(x, y) 你可以不断发掘里面附带的优秀工具。使用方法很简单,假设程序名为 foo.py,那么在命令行中输入:
winpdb foo.py
之后会弹出窗口,也就是一个大家都熟悉的 debug 图形界面。需要注意的是这里需要点击想要设置断点的行,点击 F9 设置断点,然后该行底色会变为红色,如下图所示。
 Winpdb
Winpdb
编码问题
作为中文用户,初学 Python 最容易碰到的问题估计就是编码问题了。明明英文的都可以用到中文的时候就要出问题,而且出错信息难以理解,想要解决问题又不知道从何开始。幸运的是编码问题通过预防性的措施是很好避免的。下面从几个方面来讲讲 Python 中处理中文及 Unicode 容易碰到的问题。
Unicode 编码基础
这里非常简单的讲一下编码知识,此部分表述可能不太准确,如果你对 Unicode 更为了解的话请联系我帮忙纠正。
你可以想象 Unicode 是一个很大的表,里面有着世界上所有的文字的个体,如英文中的字母,中文的汉字。事实上 Unicode 标准中每一个字都有一个唯一对应的编号,好比说 '中'字 对应十六进制 0x4E2D,而字母 'a' 对应的是十六进制 0x0061。这个编号是由 Unicode Consortium 这个组织来确定的。 如果说用这个编码来对应字符来用于表示字符,理论上是可以的,这样的话就是每一个数字编号能对应一个字符。
而实际情况中,不是每篇文章都用得到世界上所有的字符。譬如一篇英文文章就只有英文字母加上一些符号,用 Unicode 来进行存储的话每个字符要浪费太多的空间。所以就有各种类型的编码产生。编码我们这里可以理解就是将一部分的 Unicode (比如说所有的中文,或者所有的日文)字符,以某种方式确定另外一个符号来代表他。中文常用编码有 UTF8 和 GBK,仍然以 '中'字 为例, UTF8 编码将对应 '中'字 的 Unicode 编号 0x4E2D 拆成三个的编号的组合,[0xE4, 0xB8, 0xAD],只有这几个连在一起的时候才会被作为一个 '中'字 显示出来;作为对比,GBK 编码将 '中'字 对应的 Unicode 编号 0x4E2D 编码成为两个编号的组合 [0xD6, 0xD0],在 GBK 编码环境下只有这两个编号一起时,才会显示为 '中'字。
上面的例子中,如果把 UTF8 编码后的 [0xE4, 0xB8, 0xAD] 放到 GBK 环境下来显示会怎样?这几个编号跟 '中'字 在 GBK 下的编码 [0xD6, 0xD0],不同,则显然不会显示为 '中'字。这三个字符会跟排在其前后的字符一起,按照 GBK 的编码规则找有没有对应的字符。结果有可能显示出一个毫不相关的字符,有时候为符号或者干脆不显示,这种情况就算产生了乱码。
Python 2.x 中的 String 与 Unicode
在 Python 2.x 中是有两种字串符相关类型的,分别为 String 和 Unicode,两者提供的接口非常类似,有时候又能自动转换,蛮容易误导人的。在 Python 3 中 这两个类型分别用 Bytes 和 String 替代了。这个名字更能说明两者的本质:Python 2.x 中的 String 中存储的是没有编码信息的字节序列,也就是说 String 中存储的是已经编码过后的序列,但他并不知道自身是用的哪种编码。相反的 Unicode 中存储的是记载了编码的字串信息,其中存储的就是相应字符的 Unicode 编号。在这里用程序来说明,我们建立一个简单的脚本名字为 encoding.py,代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
strs = "这是中文"
unis = "这也是中文".decode("utf8")
print strs[0:2]
print unis[0:2].encode('gbk')
print len(strs)
print len(unis)
前面两行后面会解释到,就是限定运行环境以及该脚本文件的编码格式。此脚本在这里可以下载,如果你要自己写的话请务必确保脚本的编码是 utf8 而不是别的。在 Windows 下的运行结果在这里,我觉得正好能说明问题:
C:\SHARED\Dev\scripts>encoding.py
杩
这也
12
5
这里需要说明,我们的程序是 UTF8 编码,主要意义是该程序中的所有直接写出来的字串符(用"", ''括起来的字串符)是运用 UTF8 格式编码的;然而 Windows 下的命令行是 GBK 环境。这里 strs 是一个 String。事实上在 Python 2.x 中直接写在程序中的字串符,其类型都是 String(这里不考虑 string literal)。我们先直接输出 strs[0:2],得到的是一个乱码字符(这个字符只是碰巧凑成是一个字)。如上面说的,String 中存储的是没有编码信息的字串序列,这里就是将strs中前两个编号取出并尝试显示。由于命令行环境为 GBK 编码,这里对应的字碰巧凑成了一个字,但是跟原本的字没有任何关系。
unis 是由一个 String 调用 decode() 方法得到,这正是在 Python 2.x 中取得 Unicode 的最基本的方式。由于 String 并不知道它本身是由什么编码格式来进行的编码,这里是我们的责任来确定他原来是用哪种编码方式进行编码。我们知道代码中的编码格式是 UTF8,所以我们可以用调用 String 的 decode() 方法来进行反编码,也就是解码, 把字串符从某种编码后的格式转换为其唯一对应的 Unicode 编号。unis 为解码获得的结果,其在 Python 2.x 中对应类型就是 Unicode,其中存储的就是 每个字符对应的 Unicode 编号。
我们尝试输出 unis 的前两个字符,在这里我们调用了 Unicode 的 encode() 方法。这就是编码的过程。我们知道 Windows 命令行下的编码是 GBK,只有采用 GBK 编码的字符才能正确显示。所以在这里我们通过调用 Unicode 的 encode() 方法,将 unis 中存储的 Unicode 编号 按照 GBK 的规则来进行编码,并输出到屏幕上。这里我们看到这里正确的显示了 unis 中的前两个字符。要注意的是在命令行中直接 print Unicode 的话 Python 会自动根据当前环境进行编码后再显示,但这样掩盖了两者的区别。建议总是手动调用 encode 和 decode 方法,这样自己也会清楚一些。
后面两者长度的差别也是佐证我们之前的例子。strs 中存储的是 UTF8 编码后的编号序列,上面看到一个中文字符在 UTF8 编码后变成三个连续的,所以 strs 长度为 3x4 = 12。你可以想象 strs 中存放的并不是中文,而是一系列没有意义的比特序列;而 unis 中存储的是对应的中文的 Unicode 编码。我们知道每一个字符对应一个编号,所以五个字对应五个编号,长度为 5。
避免,和解决编码产生的问题
了解了 Python Unicode 编码解码的这些概念后,我们来看看如何尽量的避免遇到让人烦心的编码问题。
首先如果你的代码中有中文,那么一定要务必声明代码的编码格式。根据 PEP-0263 中的介绍,在程序的最开始加上以下两行注释就能确定编码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
其中 utf-8 就是指定的编码格式。事实上你应该总是使用 UTF8 作为你 Python 程序的编码格式,因为未来的 Python 3 所有文件都将默认以 UTF8 编码。另外除了声明,你必须确定你用来编辑 Python 程序的编辑器是不是真的以 UTF8 编码来存储文件。
之后就是养成关于编码解码的好习惯。当你的程序有 String 作为输入时,应该尽早的将其转换为 Unicode,再在程序中进行处理。再输出的时候,也要尽可能玩,直到最后输出的时刻才将 Unicode 编码为所需编码格式的 String 进行输出。同样的你必须保持你程序内部所有参与运算的字串都是 Unicode 格式。很多著名的 Python 库例如 django 就是采用的这种方式,效果也蛮好。千万不要依赖 Python 自己进行两者之间的转换,也不要将 String 和 Unicode 放在一起运算,这些行为一方面十分容易引起错误,另一方面在 Python 3 中已经无法再现。
虽说确定 String 的编码格式是程序员的责任,但有时候你真的不知道有些字串符到底是什么编码的。这里有一个神奇 chardet 能够帮助你。以下是摘自其页面上的例子,很好了说明了它的作用:读入任意一串字符,猜测其编码格式,并且给出猜测的确信度。
>>> import urllib
>>> urlread = lambda url: urllib.urlopen(url).read()
>>> import chardet
>>> chardet.detect(urlread("http://google.cn/"))
{'encoding': 'GB2312', 'confidence': 0.99}
>>> chardet.detect(urlread("http://yahoo.co.jp/"))
{'encoding': 'EUC-JP', 'confidence': 0.99}
>>> chardet.detect(urlread("http://amazon.co.jp/"))
{'encoding': 'SHIFT_JIS', 'confidence': 1}
>>> chardet.detect(urlread("http://pravda.ru/"))
{'encoding': 'windows-1251', 'confidence': 0.9355}
如果 confidence 非常低的话或者 chardet 直接报错,多半是字串经过多次错误编码解码,要从别的地方找办法解决问题。
在处理包含汉字的文本文件时,一个很常见的问题就是有时候会碰到带有 UTF BOM 的文件。这个简单讲就是文件头几个字节是用来表示文件是大端还是小端表示。在实际中用的很少,而且会带来很头疼的问题。有时候你确定你有一个文件是 UTF8 编码的,但读进来头几个字节就出错,那么十有八九就是这个的问题。Python 在读取文件时仍然是所有字节顺序读进来,不会透明的处理这个东西。所以要么你可以用编辑器来把文件另存为无 BOM 的,要么在 Python 中做处理。在标准库中有 codec 里面提供了相关功能:
import codecs
s = f.read(3)
if s == codecs.BOM_UTF8:
print "BOM detected"
这样可以简单检测 BOM 是否存在,剩下的部分就要你自己发挥了。
如果上面的介绍还不能让你理解 Unicode 的概念,这里还有几篇关于这个问题的文章:
-
Unicode In Python, Completely Demystified 特别针对 Python 下的 Unicode 处理进行详细的讲解。
其他
除了上面几个重要的问题之外,剩下的资源。
Vim Python开发 相关资源
事实上我现在自己是在用 Vim 写 Python,感觉也蛮不错。以下是相关资源。
-
UltimateVimPythonSetup
比较新的一个专门针对 Python 的 Vim 配置文件。 -
Vim as Python IDE
只要搜 Python 和 Vim 就一定会找到这一篇文章。 -
vimcolorschemetest
所有的Vim 配色方案都在集结在这里。 -
Python 相关 Vim 插件
pythoncomplete.vim
按上面的介绍配置一下,在自动输入的时候按Ctrl-X, Ctrl-O就有很强力的自动补全了。
python.vim
加强语法的高亮。
pyflakes.vim
很棒的语法检查,分析你的语法看避免低级错误。注意这个在Vim7.2下才有用,
如果是7.1则一点效果都没有...
其他相关资源
-
用Python做科学计算
这个把Python(x,y)里面所有的模块基本上都讲了一遍,我觉得外国人肯定都希望这个有个英文版的。 -
PyMOTW
这个名字看起来像个Python库(其实它还真的是一个...),但他总体来说其实是一份文档,
"Python每周一个模块"。作者持续几年每周介绍一个Python标准库中的库。你可以把他看做是一个Python标准库文档的一个很棒的补充,当你看标准库中的介绍看的云里雾里的时候,不妨来这边找找相应的介绍。因为这里的例子给的很全,而且基本上你用的到的偏门的库这里都有介绍哦。另外一个好消息是PyMOTW有一份很棒中文翻译版。 -
reddit.com/r/python 和
python.org planet
Python 相关的文章和资源。就我个人经历来说,每次都能在这里看到很多有用的东西。














网友评论