如果你有了一大堆数据,想找到异常的数据记录,异常检测就是解决这个问题的。
在工业数据中,异常意味着故障、不合格;
在账户数据中,异常意味着可能盗号、欺诈;
在财经数据中,异常意味着数据的真实性有问题。
0.引言
异常检测应用在工业检测、账户行为监测等领域。
问题特点:
- 样本比例高度不均衡,异常点总是极少数的;
- 异常样本子集一般不具备共性的特征,异常的方式各不相同,难以作为一个类别分类
- 高维数据中,并非所有的样本都会用到,需要特征选择;
- 由于样本高度不平衡,因此测试的指标往往用F1;
异常检测问题,往往更多使用无监督的算法建模,再结合标定的验证集用于切阈值。
异常检测的两类常用方法:
-
基于概率分布的方法
吴恩达机器学习课程,手动code -
Isolation Forest
周志华及其学生研究提出,已经有了sklearn实现。
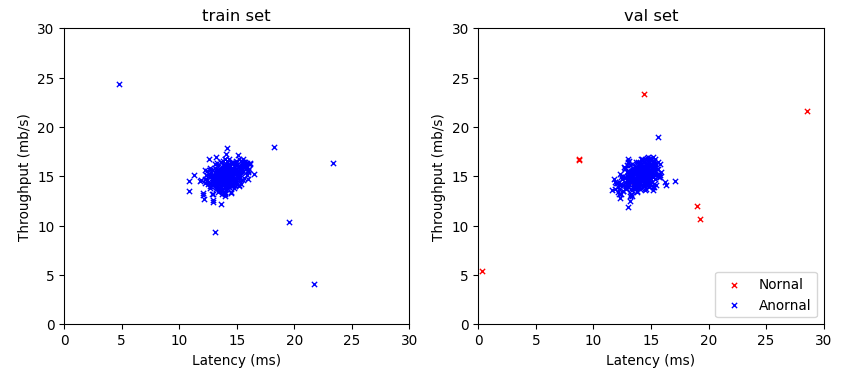
1.示例数据
数据集:电脑开机参数,包含两个特征
- 等待时间
- CPU吞吐量
训练集和验证集的图示如:
 image_1d5ijm9vc12eoq9s31217sf1spl9.png-28.6kB
image_1d5ijm9vc12eoq9s31217sf1spl9.png-28.6kB
2. 概率分布异常检测
算法概述
算法教程参见吴恩达-机器学习-异常检测。
基本的假定是:数据中的每个特征数值都符合正态分布,如果数据点在整体分布上的概率密度值极小,即极小概率出现,认为是异常值。
 image_1d5ik2kol1oaj14f21e8o11n0ppcm.png-207.2kB
image_1d5ik2kol1oaj14f21e8o11n0ppcm.png-207.2kB
概率分布方法对数据的要求:
- 特征为数值型变量,factor型变量难以用概率描述
- 特征数值符合正态分布
数据检验
正态性检验方法:stats.shapiro
- 原假设:数据符合正态分布
- 接受假设的条件:
- 统计量W接近1
- 显著性水平(p-value)大于0.05
从训练集假设检验的结果并不完全满足正态分布。
from scipy import stats # 用于数据的正态性检验
print('norm test of X[:,0]: ', stats.shapiro(X[:,0]))
print('norm test of X[:,1]: ', stats.shapiro(X[:,1]))
# output
norm test of X[:,0]: (0.818209171295166, 2.788045548629635e-18)
norm test of X[:,1]: (0.7949155569076538, 2.2437695460625395e-19)
算法应用
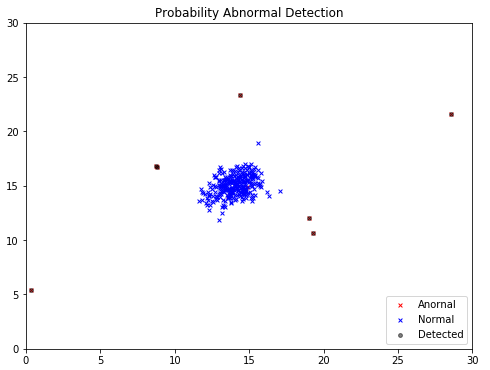
训练数据无label,在labeled验证集上,应用算法:
p_val = multivariate_gaussian(X_val, mu, sigma2) #根据训练集的mu sigma2 得到验证集样本的概率
epsilon_0, f1_0 = select_threshold(y_val, p_val) # 搜索选择合适的概率阈值
print('Best epsilon found using cross-validation: {:0.4e}'.format(epsilon_0))
print('Best F1 on Cross Validation Set: {:0.6f}'.format(f1_0))
# output
Best epsilon found using cross-validation: 8.9909e-05
Best F1 on Cross Validation Set: 0.875000
 image_1d5ikbpg42fe11o7e1b2d01shj13.png-17.7kB
image_1d5ikbpg42fe11o7e1b2d01shj13.png-17.7kB
数据集中的9个异常点,检测出了7个,另外2个未检出的点实际在数据集的中心位置,并不是典型的异常点。需要注意的是,仅当数据为2维时,才能方便的应用可视化方法。
3. Isolation Forrest
算法概述
周志华及其学生在2010年提出。
方法:对样本的所有特征2分叉,随机采样构建N棵Tree
假设:异常点非常稀有,一般很快会分配到叶子节点,路径短
结果:对样本在Tree中分配路径长度归一化,给出异常指数
以路径长度作为异常的度量,在sklearn中已经有成熟实现,模型简单,速度快,参数少。
输入数据的特征选择比较重要,少量关键的特征效果好。
算法应用
由于算法已经在sklearn中实现,可以直接加载使用.IsolationForest 支持并行计算,在数据集较大的时候很有优势。
from sklearn.ensemble import IsolationForest
# 需要调的参数主要是 树的棵树
isf = IsolationForest(n_estimators=10,
n_jobs=-1, # 使用全部cpu
verbose=2,
)
isf.fit(X) # 直接用无标签数据训练
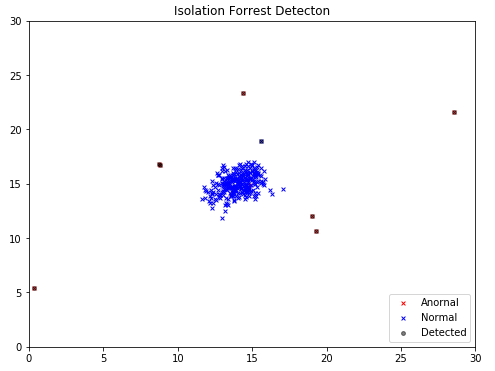
# 通过decision_function获取异常系数值,可以理解为异常概率,选择一个最好的阈值
y_val_prob = isf.decision_function(X_val)
epsilon_1, f1_1 = select_threshold(y_val, y_val_prob)
print('Best epsilon found using cross-validation: {:0.4e}'.format(epsilon_1))
print('Best F1 on Cross Validation Set: {:0.6f}'.format(f1_1))
# output
Best epsilon found using cross-validation: -6.2384e-02
Best F1 on Cross Validation Set: 0.823529
 image_1d5ikllotf4h1n4s1igu14021qn41g.png-17.5kB
image_1d5ikllotf4h1n4s1igu14021qn41g.png-17.5kB
由于数据集比较简单,IsolationForest检测性能与概率分布法是一致的。
由于IsolationForest对数据的格式(连续、离散)以及概率分布没有要求,可以预见这种算法的应用范围可能更广。




网友评论