@[TOC](CCCCCold丶大数据之禅)
# ORCFile原理
**ORCFile是什么?**
ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式。
**ORCFile作用**
用于降低Hadoop数据存储空间和加速Hive查询速度。
**ORCFile演变史**
*TEXTFile -> 列式存储 -> RCFile ->ORCFile*
***本文会从最基本TEXTFile行式存储讲起,逐步加深对ORCFile存储原理的理解***
## TEXTFile
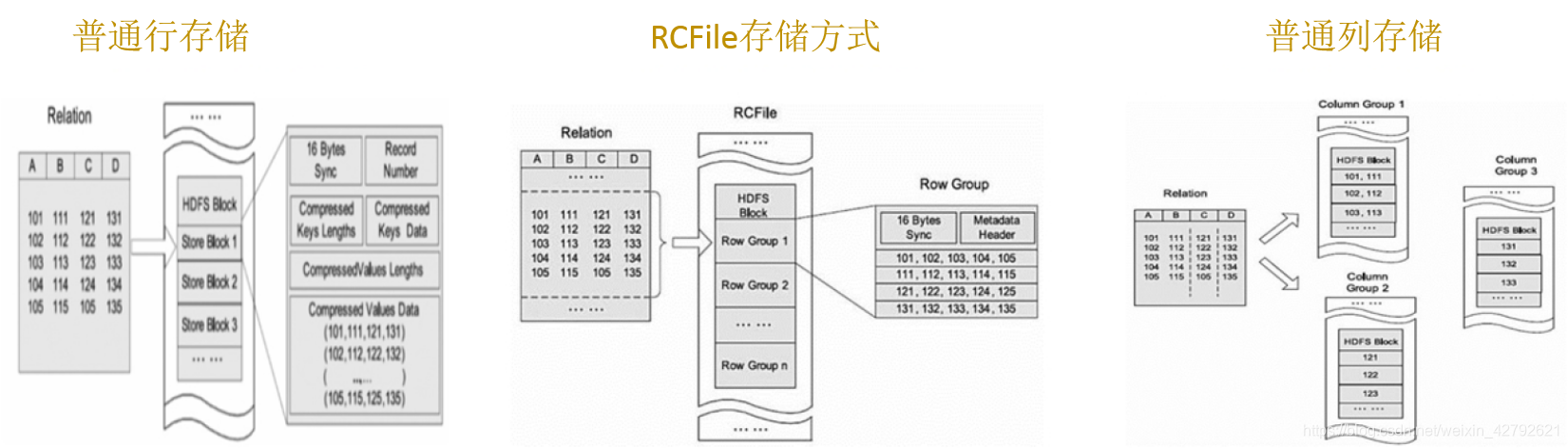
Hadoop默认文件存储格式,读取未压缩的TEXTFile文件不涉及到MapReduce
**存储方式:** 行式存储
**逻辑视图:**

我们想查询第二列第九行的数据,查询HQL为:
`SELECT col2 FROM table WHERE row = 'row_9';`
这条Hive SQL转换为相应的MapReduce程序执行时,虽然我们仅仅只需要查询该表的第2列数据即可得出结果,但因为我们使用的是TextFile存储格式,不得不读取整张数据表的数据参与计算。虽然我们可以使用一些压缩机制优化存储,减少读取的数据量,但效果通常不显著,而且毕竟读取了很多无用的数据(col1、col3)。
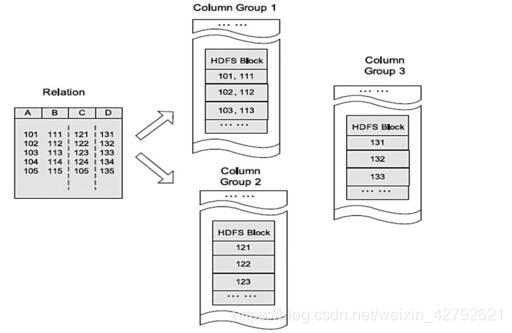
## 普通列式存储
**逻辑视图:**
**优点:**
查询某列时,只会扫描对应HDFS数据块
**缺点:**
有时候存在一个表的有些列不在同一个HDFS块上,所以在查询的时候,Hive重组列的过程会浪费很多IO开销。
## RCFile
RCFile全称Record Columnar File,列式记录文件,是一种类似于SequenceFile的键值对(Key/Value Pairs)数据文件。
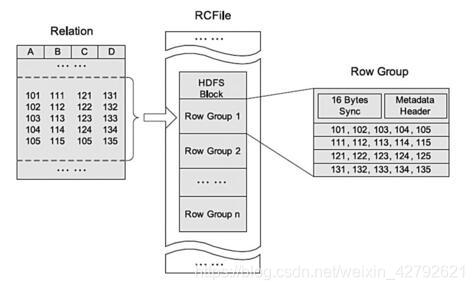
RCFile文件格式是FaceBook开源的一种Hive的文件存储格式,首先将表分为几个行组,对每个行组内的数据进行按列存储,每一列的数据都是分开存储,正是先**水平划分**,再**垂直划分**的理念。
关键词:Record、Columnar、Key、Value。
**1、水平划分**

经过水平划分之后的各个数据块称之为Row Split或Record。
**2、垂直划分**

每一个Row Split或Record再按照“列”进行垂直划分。
**3、列式存储**
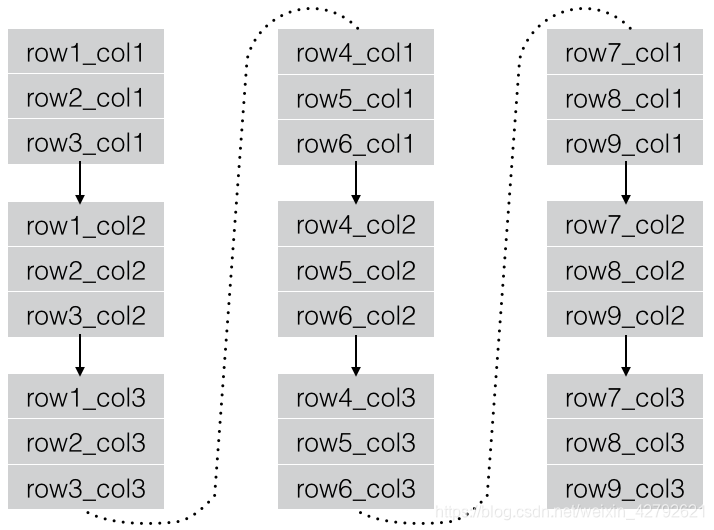
RCFile以Record为单位进行存储。
Record存储数据时,首先存储该Record内第一列的全部数据、然后存储该Record内第二列的全部数据、…、依次将各列数据存储完毕,然后继续下一个Record的存储。
Record实际由Key、Value两部分组成,其中Key保存着Record的元数据,如列数、每列数据的长度、每列数据中各个列值的长度等;Value保存着Record各列的数据。实际上Record Key相当于Record的索引,利用它可以轻松的实现Record内部读取/过滤某些列的操作。
**在数据上:**
**RCFile将每一行,存储为一列,将一列存储为一行**,因为当表很大,我们的字段很多的时候,我们往往只需要取出固定的一列就可以。
而且RCFile将“行式”存储变为“列式”存储,相似的数据以更高的可能性被聚集在一起,压缩效果更好。
**在存储结构上:**
RCFile首先对表进行行划分,分成多个行组。一个行组主要包括:16字节的HDFS同步块信息,主要是为了区分一个HDFS块上的相邻行组;元数据的头部信息主要包括该行组内的存储的行数、列的字段信息等等;
RCFile由于相同的列都是在一个HDFS块上,所以相对列存储而言会节省很多资源。
**在存储空间上:**
RCFile采用游程编码,相同的数据不会重复存储,很大程度上节约了存储空间,尤其是字段中包含大量重复数据的时候。
**懒加载:**
数据存储到表中都是压缩的数据,Hive读取数据的时候会对其进行解压缩,但是会针对特定的查询跳过不需要的列,这样也就省去了无用的列解压缩。
`SELECT col2 FROM table WHERE col3 > 1';`
针对行组来说,会对一个行组的col3列进行解压缩,如果当前列中有col3 > 1的值,然后才去解压缩col2。若当前行组中不存在col3 > 1的列,那就不用解压缩col2,从而跳过整个行组。
**RCFile逻辑视图:**
## ORCFile
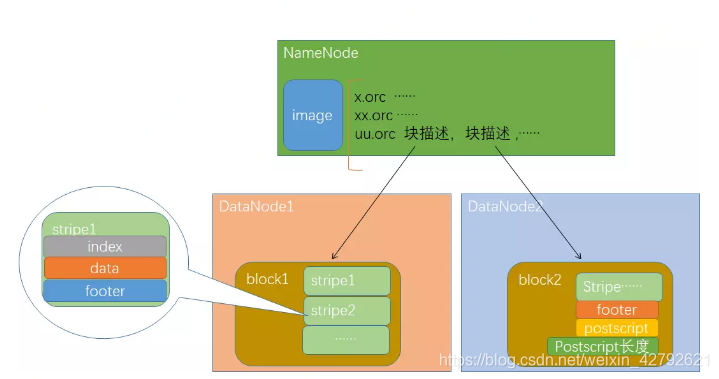
ORC (Optimized Record Columnar)是RC File 的改进(优化),主要在压缩编码、查询性能上进行了升级。在ORC格式的hive表中,记录首先会被横向的切分为多个stripes,然后在每一个stripe内数据以列为单位进行存储,所有列的内容都保存在同一个文件中。
**相对于RCFile,ORCFile有如下几点好处:**
1. 每个task只生成一个文件,减轻hdfs压力
2. 存列类型,支持datetime, decimal和负责类型(struct, list, map, and union)
3. 文件中保存轻量级索引【跳过不需的row group,seek到指定的row】
4. 根据列类型进行压缩【整数类型:run-length encoding,string类型:dictionary encoding】
5. 不同的recordReader并发读同一文件
6. split时,无需扫描标记
7. 可以限制读写占用的内存
8. 使用pb存放元数据,支持添加和移除列
9. ORCFile stripe默认的大小是250MB,相对于RCFile默认的行组大小是4MB,所以比RCFile更高效
**相较于行式存储优点:**
1. 查询的时候不需要扫描全部的数据,而只需要读取每次查询涉及的列,这样可以将**I/O消耗降低N倍**,另外可以保存每一列的统计信息(min、max、sum等),实现部分的**谓词下推**。
2. 由于每一列的成员都是同构的,可以针对不同的数据类型使用更高效的数据压缩算法,进一步**减小I/O**。
3. 由于每一列的成员的同构性,可以使用更加适合CPU pipeline的编码方式,**减小CPU的缓存失效**。
**逻辑视图:**
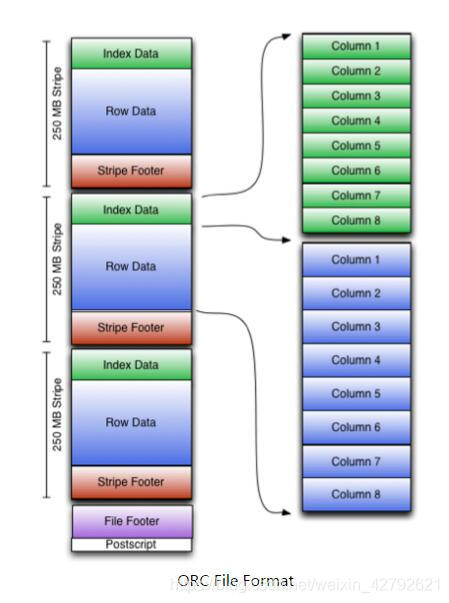
**逻辑视图划分:**
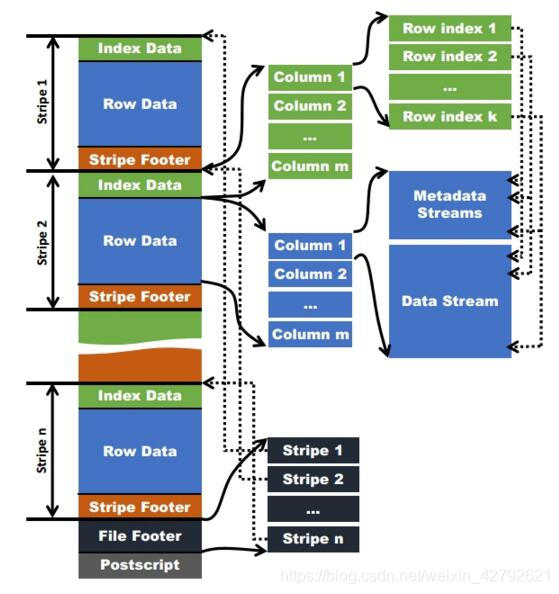
**物理视图划分:**
> Postscripts:中存储该表的行数,压缩参数,压缩大小,列等信息
Stripe Footer:中包含该stripe的统计结果,包括Max,Min,count等信息
FileFooter中:包含该表的统计结果,以及各个Stripe的位置信息
IndexData:中保存了该stripe上数据的位置信息,总行数等信息
RowData:以stream的形式保存了数据的具体信息
新版本的Hive中提供了更详细的查看ORC文件信息的工具 orcfiledump。
执行命令:`./hive –orcfiledump -j -p /hivedata/warehouse2/lxw1234_orc1/000000_0`
(⊙o⊙)… 我在Hive2.0版本无法使用该命令,有兴趣自己尝试,会以JSON形式返回ORC表的元数据

**ORCFile在存储上的必杀器,必考题:**
1. ORCFile引入字典编码,最后存储的数据便是字典中的值,每个字典值得长度以及字段在字典中的位置。
2. ORCFile扩展了RCFile的压缩,Run-length(游程编码),压缩重复数据。
3. ORCFile引入Bit编码,对所有字段都采用Bit编码来判断该列是否为null,如果为null则Bit值存为0,否则存为1,对于为null的字段在实际编码的时候不需要存储,也就是说字段若为null,是不占用存储空间的。
**采用ORC格式存储数据,空值一定用NULL存储,不要存''(空字符串)**
东扯西扯了一大堆,从TEXTFile到ORCFile,整个串下来详细讲解了ORC存储原理,下面引用几个报告,比较一下ORCFile相对传统文件格式有点
**不同文件格式逻辑视图比较:**
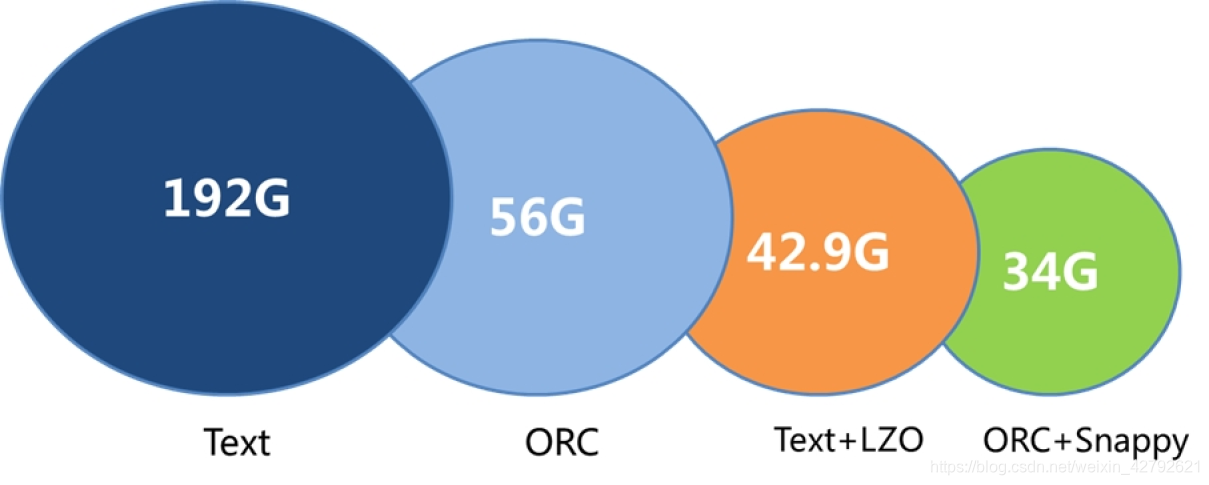
**ORCFile存储优势(引用报告):**
**查询优势(引用报告):**
***在查询方面,ORC+Snappy 相比Text+LZO 查询效率可提升70%左右,针对宽表的查询,查询字段越少,其查询效率越高。***
**ORC标准建表语句:**
```
create external table app_jdw_jmart_zbinfo_test_test(
capacity_all float comment '数据总容量',
deal_data_dt float comment '日处理数据量',
add_data_dt float comment '日新增数据量',
add_job_dt float comment '日运行job数',
machine_num int comment '平台总机器数',
corejob_avgtime string comment '核心任务平均运行时长')
PARTITIONED BY ( week_nm string,dt string )
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' (列分隔符)
NULL DEFINED AS "" (空值展示为"")
STORED AS ORC (存储格式为ORC,不可少)
LOCATION '*************' (指定表的location)
tblproperties ('orc.compress'='SNAPPY'); (ORC压缩格式为SNAPPY)
```
**参考:**
https://blog.csdn.net/u011596455/article/details/76648571
https://blog.csdn.net/u014307117/article/details/52381383
https://www.cnblogs.com/ITtangtang/p/7677912.html
http://lxw1234.com/archives/2016/04/630.htm
***人生苦短,我用Python,CCCCCold的大数据之禅***











网友评论