SQLite3 可使用 sqlite3 模块与 Python 进行集成。sqlite3 模块是由 Gerhard Haring 编写的。它提供了一个与 PEP 249 描述的 DB-API 2.0 规范兼容的 SQL 接口。您不需要单独安装该模块,因为 Python 2.5.x 以上版本默认自带了该模块。SQLite - Python | 菜鸟教程**
所用数据集为奥斯卡金像奖数据(Academy Awards nominations),下载地址:Complete List of Oscar Nominees and Winners**
导入数据:
import pandas as pd
awards=pd.read_csv('./data/academy_awards.csv',encoding='ISO-8859-1')
print(awards.info())
print(awards.head())
# print(awards['Unnamed: 5'].value_counts()) 查看是否含有有价值的信息
# print(awards['Unnamed: 6'].value_counts())
# print(awards['Unnamed: 7'].value_counts())
# print(awards['Unnamed: 8'].value_counts()
数据信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10137 entries, 0 to 10136
Data columns (total 11 columns):
Year 10137 non-null object
Category 10137 non-null object
Nominee 10137 non-null object
Additional Info 9011 non-null object
Won? 10137 non-null object
Unnamed: 5 11 non-null object
Unnamed: 6 12 non-null object
Unnamed: 7 3 non-null object
Unnamed: 8 2 non-null object
Unnamed: 9 1 non-null object
Unnamed: 10 1 non-null objectdtypes: object(11)
memory usage: 871.2+ KB
- 数据清洗
通过结果可以看到,Year属性列为字符串型,格式比较乱。首先对'Year'属性进行格式化
#Clean 'Year' column then convert its datatype
awards['Year']=awards['Year'].str[0:4]
awards['Year']=awards['Year'].astype(int)
print(awards['Year'].dtype)
因为sqlite数据库中以integer代替boolean类型,所以我们需要将'Won?'列由boolean转换为integer:
#Clean 'Wons' column
nonominations['Won']=nominations['Won?'].map({'YES':1,'NO':0})
final_nominations=nominations.drop(['Won?','Unnamed: 5','Unnamed: 6','Unnamed: 7','Unnamed: 8','Unnamed: 9','Unnamed: 10'],axis=1)
print(final_nominations.head())
为方便操作,格式化完以后提取2000年以后的数据,且只提取奖项类别为award_categories中类别的数据行:
#Filter datasetlater_than_2000=awards[awards['Year']>2000]
award_categories=['Actor -- Leading Role','Actor -- Supporting Role','Actress -- Leading Role','Actress -- Supporting Role']
nominations=later_than_2000[later_than_2000['Category'].isin(award_categories)]
print(nominations[:10])
为了将Additional Info列存入数据库,可以将该列进行分割操作:
#Split 'Additional info' columnadditional_info_one=final_nominations['Additional Info'].str.rstrip("'}")
additional_info_two=additional_info_one.str.split("{'")
final_nominations['Movie']=additional_info_two.str[0]
final_nominations['Character']=additional_info_two.str[1]
final_nominations=final_nominations.drop('Additional Info',axis=1)
final_nominations.head()
- 使用sqlite3将DataFrame中的信息存入到sqlite中import
sqlite3 conn=sqlite3.connect('./data/nominations.db')
final_nominations.to_sql('nominations',conn,index=False)
result=conn.execute("pragma table_info(nominations);").fetchall()
print(result)
conn.close()
为了验证是否存储成功,可以在终端进行验证:
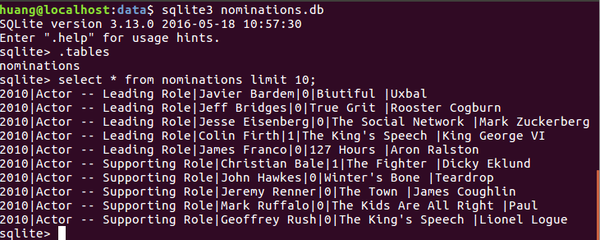













网友评论