nodejs 模块机制
简单模块定义和使用
在Node.js中,定义一个模块十分方便。我们以计算圆形的面积和周长两个方法为例,来表现Node.js中模块的定义方式。
var PI = Math.PI;
exports.area = function (r) {
return PI * r * r;
};
exports.circumference = function (r) {
return 2 * PI * r;
};
将这个文件存为circle.js,然后新建一个app.js文件,并写入以下代码:
var circle = require('./circle.js');
console.log( 'The area of a circle of radius 4 is ' + circle.area(4));
可以看到模块调用也十分方便,只需要require需要调用的文件即可。
在require了这个文件之后,定义在exports对象上的方法便可以随意调用。Node.js将模块的定义和调用都封装得极其简单方便,从API对用户友好这一个角度来说,Node.js的模块机制是非常优秀的。
关于exports的内容,可以参考之前的文章 exports && module.exports
模块分类
核心模块
核心模块优先级仅次于缓存加载,因此无法加载一个和核心模块标识符相同的自定义模块。
路径形式的文件模块
以"."、".."开头和"/"开始的标识符,这里都被当作文件模块来处理。require()方法会将路径转为真实路径,并以真实路径作为索引,并将编译执行后的结果存放到缓存中。
自定义模块(特殊的文件模块)
自定义模块是指非核心模块,也不是路径形式的标识符。它是一种特殊的文件模块,可能是一个文件或者包的形式。
模块路径是Node在定位文件模块的具体文件时制定的查找策略,具体表现为一个路径组成的数组(module.paths)。这个路径由当前目录开始往上一直到根目录,Node会逐个尝试模块路径中的路径,直到找到目标文件未知,若到达根目录还是没有找到目标文件,则会抛出查找失败的异常。当前文件的目录越深,模块查找耗时越多。
模块载入策略
上文中说道,Node.js的模块分为两类,一类为原生(核心)模块,一类为文件模块。
原生模块在Node.js源代码编译的时候编译进了二进制执行文件,加载的速度最快。另一类文件模块是动态加载的,加载速度比原生模块慢。但是Node.js对原生模块和文件模块都进行了缓存,于是在第二次require时,是不会有重复开销的。由于通过命令行加载启动的文件几乎都为文件模块。我们从Node.js如何加载文件模块开始谈起。
我们从命令行启动上文的app.js文件。
node app.js
加载文件模块的工作,主要由原生模块module来实现和完成,该原生模块在启动时已经被加载,进程直接调用到runMain静态方法。
// bootstrap main module.
Module.runMain = function () {
// Load the main module--the command line argument.
Module._load(process.argv[1], null, true);
};
_load静态方法在分析文件名之后执行
var module = new Module(id, parent);
并根据文件路径缓存当前模块对象,该模块实例对象则根据文件名加载。
module.load(filename);
实际上在文件模块中,又分为3类模块。这三类文件模块以后缀来区分,Node.js会根据后缀名来决定加载方法。
- .js。通过fs模块同步读取js文件并编译执行。
- .node。通过C/C++进行编写的Addon。通过dlopen方法进行加载。
- .json。读取文件,调用JSON.parse解析加载。
这里我们将详细描述js后缀的编译过程。Node.js在编译js文件的过程中实际完成的步骤有对js文件内容进行头尾包装。以app.js为例,包装之后的app.js将会变成以下形式:
(function (exports, require, module, __filename, __dirname) {
var circle = require('./circle.js');
console.log('The area of a circle of radius 4 is ' + circle.area(4));
});
这段代码会通过vm原生模块的runInThisContext方法执行(类似eval,只是具有明确上下文,不污染全局),返回为一个具体的function对象。最后传入module对象的exports,require方法,module,__filename(文件名),__dirname(目录名)作为实参并执行。
这就是为什么require并没有定义在app.js文件中,但是这个方法却存在的原因。从Node.js的API文档中可以看到还有__filename、__dirname、module、exports几个没有定义但是却存在的变量。
__filename``和__dirname在查找文件路径的过程中分析得到后传入的。module变量是这个模块对象自身,exports是在module的构造函数中初始化的一个空对象({},而不是null)。
在这个主文件中,可以通过require方法去引入其余的模块。而其实这个require方法实际调用的就是load方法。
load方法在载入、编译、缓存了module后,返回module的exports对象。这就是circle.js文件中只有定义在exports对象上的方法才能被外部调用的原因。
以上所描述的模块载入机制均定义在lib/module.js中。
require 方法中的文件查找策略
尽管require方法极其简单,但是内部的加载却是十分复杂的,其加载优先级也各自不同。
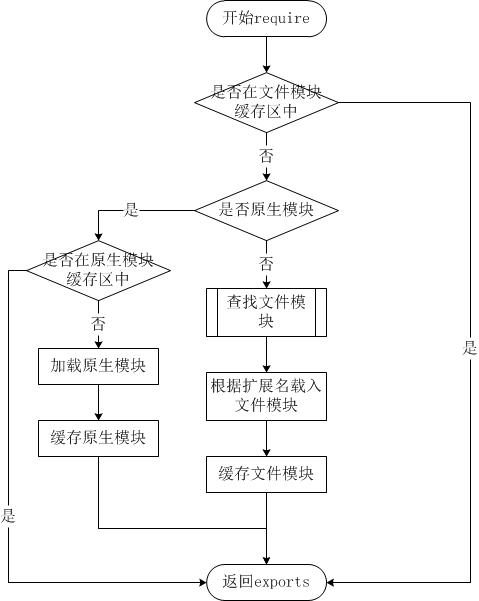 image1.jpg-29.2kB
image1.jpg-29.2kB
从文件加载
当文件模块缓存中不存在,而且不是原生模块的时候,Node.js会解析require方法传入的参数,并从文件系统中加载实际的文件,加载过程中的包装和编译细节在前一节中已经介绍过,这里我们将详细描述查找文件模块的过程,其中,也有一些细节值得知晓。
require方法接受以下几种参数的传递:
- http、fs、path等,原生模块。
- ./mod或../mod,相对路径的文件模块。
- /pathtomodule/mod,绝对路径的文件模块。
- mod,非原生模块的文件模块。
在进入路径查找之前有必要描述一下module path这个Node.js中的概念。对于每一个被加载的文件模块,创建这个模块对象的时候,这个模块便会有一个paths属性,其值根据当前文件的路径计算得到。我们创建modulepath.js这样一个文件,其内容为:
console.log(module.paths);
我们将其放到任意一个目录中执行node modulepath.js命令,将得到以下的输出结果(mac的演示结果)。
[ '/Users/beifeng/Desktop/test_node/node_modules',
'/Users/beifeng/Desktop/node_modules',
'/Users/beifeng/node_modules',
'/Users/node_modules',
'/node_modules' ]
可以看出module path的生成规则为:从当前文件目录开始查找
node_modules目录;然后依次进入父目录,查找父目录下的node_modules目录;依次迭代,直到根目录下的node_modules目录。
文件模块查找流程
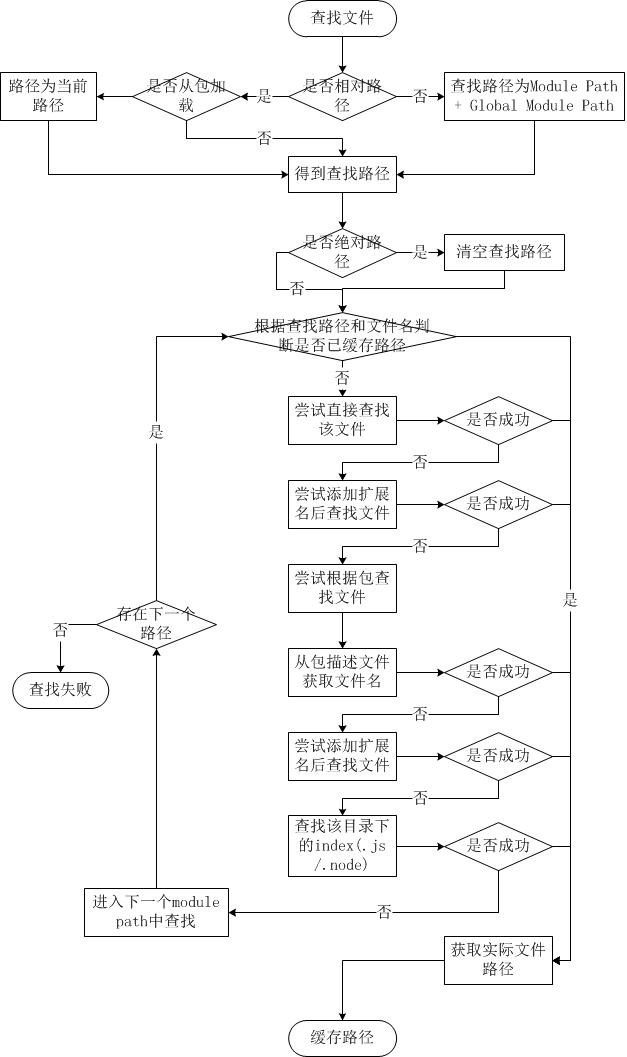 image2.jpg-69.9kB
image2.jpg-69.9kB
简而言之,如果require绝对路径的文件,查找时不会去遍历每一个node_modules目录,其速度最快。其余流程如下:
1.从module paths数组中取出第一个目录作为查找基准。
2.直接从目录中查找该文件,如果存在,则结束查找。如果不存在,则进行下一条查找
3.尝试添加.js、.json、.node后缀后查找,如果存在文件,则结束查找。如果不存在,则进行下一条。
4.尝试将require的参数作为一个包来进行查找,读取目录下的package.json文件,取得main参数指定的文件。
5.尝试查找该文件,如果存在,则结束查找。如果不存在,则进行第3条查找。
6.如果继续失败,则取出module path数组中的下一个目录作为基准查找,循环第1至5个步骤。
7.如果继续失败,循环第1至6个步骤,直到module paths中的最后一个值。
8.如果仍然失败,则抛出异常。
整个查找过程十分类似原型链的查找和作用域的查找。所幸Node.js对路径查找实现了缓存机制,否则由于每次判断路径都是同步阻塞式进行,会导致严重的性能消耗。
CommonJS规范
JavaScript缺少包结构。CommonJS致力于改变这种现状,于是定义了包的结构规范(http://wiki.commonjs.org/wiki/Packages/1.0 )。
CommonJS(http://www.commonjs.org)规范的出现,其目标是为了构建JavaScript在包括Web服务器,桌面,命令行工具,及浏览器方面的生态系统。
一个符合CommonJS规范的包应该是如下这种结构:
- 一个package.json文件应该存在于包顶级目录下
- 二进制文件应该包含在bin目录下。
- JavaScript代码应该包含在lib目录下。
- 文档应该在doc目录下。
- 单元测试应该在test目录下。
由上文的require的查找过程可以知道,Node.js在没有找到目标文件时,会将当前目录当作一个包来尝试加载,所以在package.json文件中最重要的一个字段就是main。而实际上,这一处是Node.js的扩展,标准定义中并不包含此字段,对于require,只需要main属性即可。
引用文章
-
深入浅出Nodejs






网友评论