认识DOM
文档对象模型DOM(Document Object Model)定义访问和处理HTML文档的标准方法。DOM 将HTML文档呈现为带有元素、属性和文本的树结构(节点树)。
先来看看下面代码:

将HTML代码分解为DOM节点层次图:
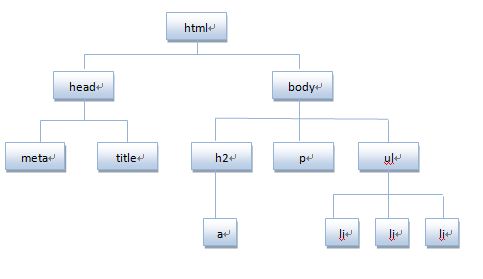
HTML文档可以说由节点构成的集合,DOM节点有:
-
元素节点:上图中
<html>、<body>、<p>等都是元素节点,即标签。 -
文本节点:向用户展示的内容,如
<li>...</li>中的JavaScript、DOM、CSS等文本。 -
属性节点:元素属性,如<a>标签的链接属性href="http://www.baidu.com"。
节点属性:

遍历节点树:

以上图ul为例,它的父级节点body,它的子节点3个li,它的兄弟结点h2、P。
DOM操作:
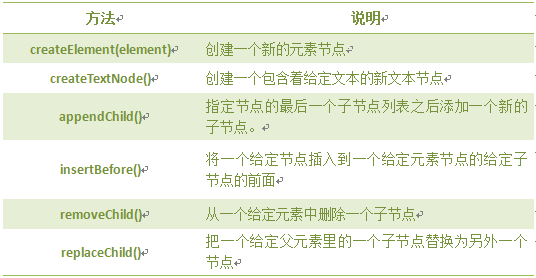
注意:前两个是document方法。
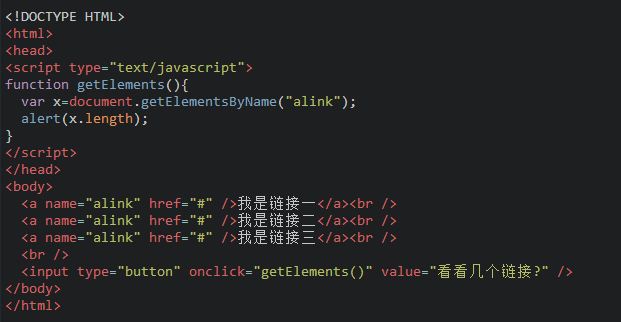
getElementsByName()方法
返回带有指定名称的节点对象的集合。
语法:
document.getElementsByName(name)
与getElementById() 方法不同的是,通过元素的 name 属性查询元素,而不是通过 id 属性。
注意:
-
因为文档中的 name 属性可能不唯一,所有 getElementsByName() 方法返回的是元素的数组,而不是一个元素。
-
和数组类似也有length属性,可以和访问数组一样的方法来访问,从0开始。
看看下面的代码:
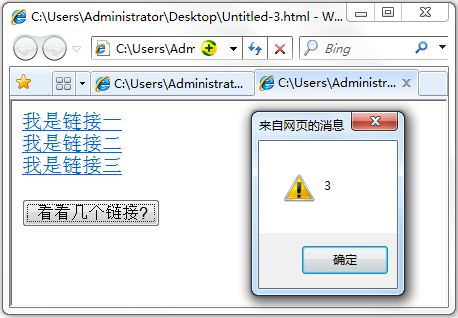
运行结果:
getElementsByTagName()方法
返回带有指定标签名的节点对象的集合。返回元素的顺序是它们在文档中的顺序。
语法:
getElementsByTagName(Tagname)
说明:
-
Tagname是标签的名称,如p、a、img等标签名。
-
和数组类似也有length属性,可以和访问数组一样的方法来访问,所以从0开始。
看看下面代码,通过getElementsByTagName()获取节点。
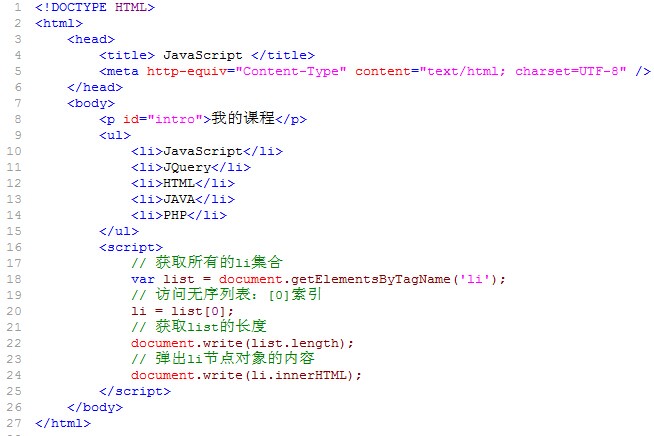
区别getElementByID,getElementsByName,getElementsByTagName
以人来举例说明,人有能标识身份的身份证,有姓名,有类别(大人、小孩、老人)等。
-
ID 是一个人的身份证号码,是唯一的。所以通过getElementById获取的是指定的一个人。
-
Name 是他的名字,可以重复。所以通过getElementsByName获取名字相同的人集合。
-
TagName可看似某类,getElementsByTagName获取相同类的人集合。如获取小孩这类人,getElementsByTagName("小孩")。
把上面的例子转换到HTML中,如下:
<input type="checkbox" name="hobby" id="hobby1"> 音乐
input标签就像人的类别。
name属性就像人的姓名。
id属性就像人的身份证。
方法总结如下:

注意:方法区分大小写
通过下面的例子(6个name="hobby"的复选项,两个按钮)来区分三种方法的不同:
<input type="checkbox" name="hobby" id="hobby1"> 音乐
<input type="checkbox" name="hobby" id="hobby2"> 登山
<input type="checkbox" name="hobby" id="hobby3"> 游泳
<input type="checkbox" name="hobby" id="hobby4"> 阅读
<input type="checkbox" name="hobby" id="hobby5"> 打球
<input type="checkbox" name="hobby" id="hobby6"> 跑步
<input type="button" value = "全选" id="button1">
<input type="button" value = "全不选" id="button1">
-
document.getElementsByTagName("input"),结果为获取所有标签为input的元素,共8个。
-
document.getElementsByName("hobby"),结果为获取属性name="hobby"的元素,共6个。
-
document.getElementById("hobby6"),结果为获取属性id="hobby6"的元素,只有一个,"跑步"这个复选项。
getAttribute()方法
通过元素节点的属性名称获取属性的值。
语法:
elementNode.getAttribute(name)
说明:
-
elementNode:使用getElementById()、getElementsByTagName()等方法,获取到的元素节点。
-
name:要想查询的元素节点的属性名字
看看下面的代码,获取h1标签的属性值:

运行结果:
h1标签的ID :alink
h1标签的title :getAttribute()获取标签的属值
setAttribute()方法
setAttribute() 方法增加一个指定名称和值的新属性,或者把一个现有的属性设定为指定的值。
语法:
elementNode.setAttribute(name,value)
说明:
1.name: 要设置的属性名。
2.value: 要设置的属性值。
注意:
1.把指定的属性设置为指定的值。如果不存在具有指定名称的属性,该方法将创建一个新属性。
2.类似于getAttribute()方法,setAttribute()方法只能通过元素节点对象调用的函数。
节点属性
在文档对象模型 (DOM) 中,每个节点都是一个对象。DOM 节点有三个重要的属性 :
-
nodeName : 节点的名称
-
nodeValue :节点的值
-
nodeType :节点的类型
一、nodeName 属性: 节点的名称,是只读的。
- 元素节点的 nodeName 与标签名相同
- 属性节点的 nodeName 是属性的名称
- 文本节点的 nodeName 永远是 #text
- 文档节点的 nodeName 永远是 #document
二、nodeValue 属性:节点的值
- 元素节点的 nodeValue 是 undefined 或 null
- 文本节点的 nodeValue 是文本自身
- 属性节点的 nodeValue 是属性的值
三、nodeType 属性: 节点的类型,是只读的。以下常用的几种结点类型:
元素类型 节点类型
元素 1
属性 2
文本 3
注释 8
文档 9
访问子结点childNodes
访问选定元素节点下的所有子节点的列表,返回的值可以看作是一个数组,他具有length属性。
语法:
elementNode.childNodes
注意:
如果选定的节点没有子节点,则该属性返回不包含节点的 NodeList。
我们来看看下面的代码:
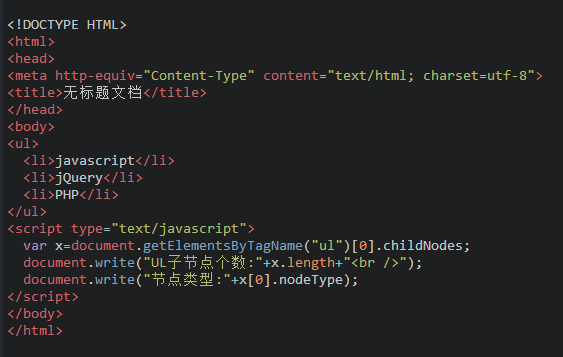
运行结果:
IE:
UL子节点个数:3
节点类型:1
其它浏览器:
UL子节点个数:7
节点类型:3
注意:
-
IE全系列、firefox、chrome、opera、safari兼容问题
-
节点之间的空白符,在firefox、chrome、opera、safari浏览器是文本节点,所以IE是3,其它浏览器是7,如下图所示:

如果把代码改成这样:
<ul><li>javascript</li><li>jQuery</li><li>PHP</li></ul>
运行结果:(IE和其它浏览器结果是一样的)
UL子节点个数:3
节点类型:1
访问子结点的第一和最后项
一、firstChild 属性返回‘childNodes’数组的第一个子节点。如果选定的节点没有子节点,则该属性返回 NULL。
语法:
node.firstChild
说明:与elementNode.childNodes[0]是同样的效果。
二、lastChild属性返回‘childNodes’数组的最后一个子节点。如果选定的节点没有子节点,则该属性返回 NULL。
语法:
node.lastChild
说明:与elementNode.childNodes[elementNode.childNodes.length-1]是同样的效果。
注意: 上一节中,我们知道Internet Explorer 会忽略节点之间生成的空白文本节点,而其它浏览器不会。我们可以通过检测节点类型,过滤子节点。
访问父节点parentNode
获取指定节点的父节点
语法:
elementNode.parentNode
注意:父节点只能有一个。
看看下面的例子,获取 P 节点的父节点,代码如下:
<div id="text">
<p id="con"> parentNode 获取指点节点的父节点</p>
</div>
<script type="text/javascript">
var mynode= document.getElementById("con");
document.write(mynode.parentNode.nodeName);
</script>
运行结果:
parentNode 获取指点节点的父节点
DIV
访问祖节点:
elementNode.parentNode.parentNode
看看下面的代码:
<div id="text">
<p>
parentNode
<span id="con"> 获取指点节点的父节点</span>
</p>
</div>
<script type="text/javascript">
var mynode= document.getElementById("con");
document.write(mynode.parentNode.parentNode.nodeName);
</script>
运行结果:
parentNode获取指点节点的父节点
DIV
注意: 浏览器兼容问题,chrome、firefox等浏览器标签之间的空白也算是一个文本节点。
访问兄弟节点
- nextSibling 属性可返回某个节点之后紧跟的节点(处于同一树层级中)。
语法:
nodeObject.nextSibling
说明:如果无此节点,则该属性返回 null。
- previousSibling 属性可返回某个节点之前紧跟的节点(处于同一树层级中)。
语法:
nodeObject.previousSibling
说明:如果无此节点,则该属性返回 null。
注意: 两个属性获取的是节点。Internet Explorer 会忽略节点间生成的空白文本节点(例如,换行符号),而其它浏览器不会忽略。
解决问题方法:
判断节点nodeType是否为1, 如是为元素节点,跳过。

运行结果:
LI = javascript
nextsibling: LI = jquery
插入节点appendChild()
在指定节点的最后一个子节点列表之后添加一个新的子节点。
语法:
appendChild(newnode)
参数:
newnode:指定追加的节点。
我们来看看,div标签内创建一个新的 P 标签,代码如下:

运行结果:
HTML
JavaScript
This is a new p
插入节点insertBefore()
nsertBefore() 方法可在已有的子节点前插入一个新的子节点。
语法:
insertBefore(newnode,node);
参数:
newnode: 要插入的新节点。
node: 指定此节点前插入节点。
我们在来看看下面代码,在指定节点前插入节点。
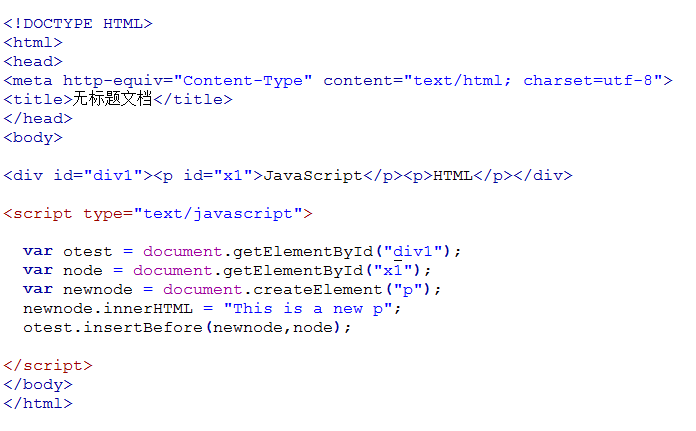
运行结果:
This is a new p
JavaScript
HTML
注意: otest.insertBefore(newnode,node); 也可以改为: otest.insertBefore(newnode,otest.childNodes[0]);
删除节点removeChild()
removeChild() 方法从子节点列表中删除某个节点。如删除成功,此方法可返回被删除的节点,如失败,则返回 NULL。
语法:
nodeObject.removeChild(node)
参数:
node :必需,指定需要删除的节点。
我们来看看下面代码,删除子点。

运行结果:
HTML
删除节点的内容: javascript
注意: 把删除的子节点赋值给 x,这个子节点不在DOM树中,但是还存在内存中,可通过 x 操作。
如果要完全删除对象,给 x 赋 null 值,代码如下:

替换元素节点replaceChild()
replaceChild 实现子节点(对象)的替换。返回被替换对象的引用。
语法:
node.replaceChild (newnode,oldnew )
参数:
newnode : 必需,用于替换 oldnew 的对象。
oldnew : 必需,被 newnode 替换的对象。
我们来看看下面的代码:

效果: 将文档中的 Java 改为 JavaScript。
注意:
-
当 oldnode 被替换时,所有与之相关的属性内容都将被移除。
-
newnode 必须先被建立。
创建元素节点createElement
createElement()方法可创建元素节点。此方法可返回一个 Element 对象。
语法:
document.createElement(tagName)
参数:
tagName:字符串值,这个字符串用来指明创建元素的类型。
注意:要与appendChild() 或 insertBefore()方法联合使用,将元素显示在页面中。
我们来创建一个按钮,代码如下:
<script type="text/javascript">
var body = document.body;
var input = document.createElement("input");
input.type = "button";
input.value = "创建一个按钮";
body.appendChild(input);
</script>
效果:在HTML文档中,创建一个按钮。
我们也可以使用setAttribute来设置属性,代码如下:
<script type="text/javascript">
var body= document.body;
var btn = document.createElement("input");
btn.setAttribute("type", "text");
btn.setAttribute("name", "q");
btn.setAttribute("value", "使用setAttribute");
btn.setAttribute("onclick", "javascript:alert('This is a text!');");
body.appendChild(btn);
</script>
效果:在HTML文档中,创建一个文本框,使用setAttribute设置属性值。 当点击这个文本框时,会弹出对话框“This is a text!”。
创建文本节点createTextNode
createTextNode() 方法创建新的文本节点,返回新创建的 Text 节点。
语法:
document.createTextNode(data)
参数:
data : 字符串值,可规定此节点的文本。
我们来创建一个<div>元素并向其中添加一条消息,代码如下:
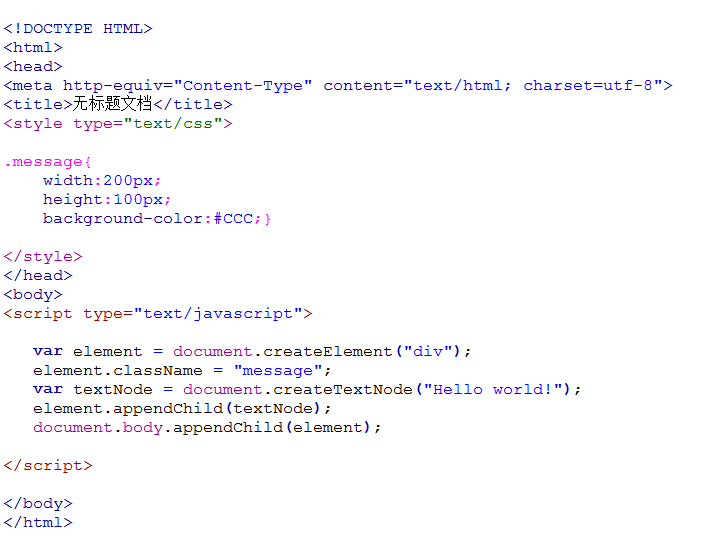
运行结果:
浏览器窗口可视区域大小
获得浏览器窗口的尺寸(浏览器的视口,不包括工具栏和滚动条)的方法:
一、对于IE9+、Chrome、Firefox、Opera 以及 Safari:
• window.innerHeight - 浏览器窗口的内部高度
• window.innerWidth - 浏览器窗口的内部宽度
二、对于 Internet Explorer 8、7、6、5:
• document.documentElement.clientHeight表示HTML文档所在窗口的当前高度。
• document.documentElement.clientWidth表示HTML文档所在窗口的当前宽度。
或者
Document对象的body属性对应HTML文档的<body>标签
• document.body.clientHeight
• document.body.clientWidth
在不同浏览器都实用的 JavaScript 方案:
var w= document.documentElement.clientWidth
|| document.body.clientWidth;
var h= document.documentElement.clientHeight
|| document.body.clientHeight;
网页尺寸scrollHeight
scrollHeight和scrollWidth,获取网页内容高度和宽度。
一、针对IE、Opera:
scrollHeight 是网页内容实际高度,可以小于 clientHeight。
二、针对NS、FF:
scrollHeight 是网页内容高度,不过最小值是 clientHeight。也就是说网页内容实际高度小于 clientHeight 时,scrollHeight 返回 clientHeight 。
三、浏览器兼容性
var w=document.documentElement.scrollWidth
|| document.body.scrollWidth;
var h=document.documentElement.scrollHeight
|| document.body.scrollHeight;
注意:区分大小写
scrollHeight和scrollWidth还可获取Dom元素中内容实际占用的高度和宽度。
网页尺寸offsetHeight
offsetHeight和offsetWidth,获取网页内容高度和宽度(包括滚动条等边线,会随窗口的显示大小改变)。
一、值
offsetHeight = clientHeight + 滚动条 + 边框。
二、浏览器兼容性
var w= document.documentElement.offsetWidth
|| document.body.offsetWidth;
var h= document.documentElement.offsetHeight
|| document.body.offsetHeight;
网页卷去的距离与偏移量
我们先来看看下面的图:
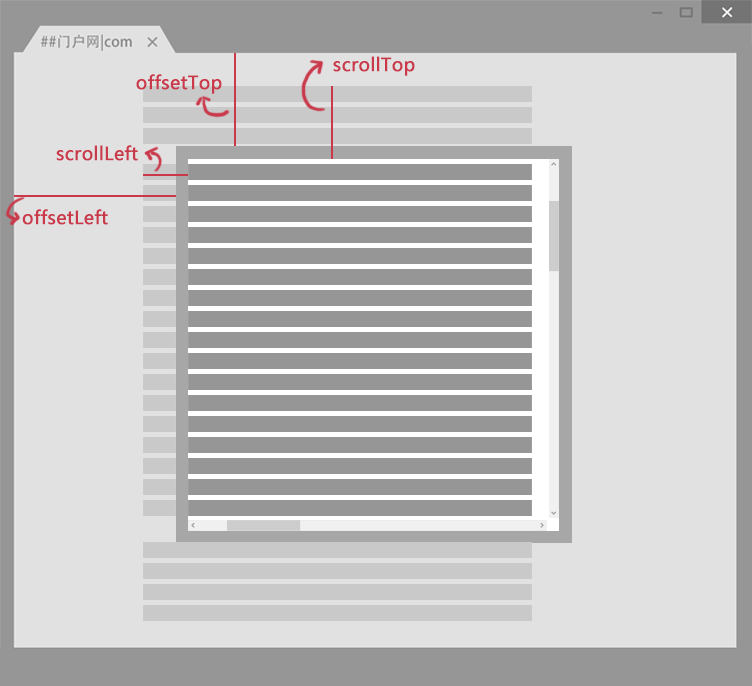
scrollLeft:设置或获取位于给定对象左边界与窗口中目前可见内容的最左端之间的距离 ,即左边灰色的内容。
scrollTop:设置或获取位于对象最顶端与窗口中可见内容的最顶端之间的距离 ,即上边灰色的内容。
offsetLeft:获取指定对象相对于版面或由 offsetParent 属性指定的父坐标的计算左侧位置 。
offsetTop:获取指定对象相对于版面或由 offsetParent 属性指定的父坐标的计算顶端位置 。
注意:
1. 区分大小写
2. offsetParent:布局中设置postion属性(Relative、Absolute、fixed)的父容器,从最近的父节点开始,一层层向上找,直到HTML的body。
 我的公众号二维码
我的公众号二维码











网友评论