KNN算法
用NumPy库实现K-nearest neighbors回归或分类。
 knn
knn
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
简单的理解,我有一组数据,比如每个数据都是n维向量,那么我们可以在n维空间表示这个数据,这些数据都有对应的标签值,也就是我们感兴趣的预测变量。那么当我们接到一个新的数据的时候,我们可以计算这个新数据和我们已知的训练数据之间的距离,找出其中最近的k个数据,对这k个数据对应的标签值取平均值就是我们得出的预测值。简单粗暴,谁离我近,就认为谁能代表我,我就用你们的属性作为我的属性。具体的简单代码实现如下。
1. 数据
这里例子来自《集体智慧编程》给的葡萄酒的价格模型。葡萄酒的价格假设由酒的等级与储藏年代共同决定,给定rating与age之后,就能给出酒的价格。
def wineprice(rating,age):
"""
Input rating & age of wine and Output it's price.
Example:
------
input = [80.,20.] ===> output = 140.0
"""
peak_age = rating - 50 # year before peak year will be more expensive
price = rating/2.
if age > peak_age:
price = price*(5 -(age-peak_age))
else:
price = price*(5*((age+1)/peak_age))
if price < 0: price=0
return price
a = wineprice(80.,20.)
a
140.0
根据上述的价格模型,我们产生n=500瓶酒及价格,同时为价格随机加减了20%来体现随机性,同时增加预测的难度。注意基本数据都是numpy里的ndarray,为了便于向量化计算,同时又有强大的broadcast功能,计算首选。
def wineset(n=500):
"""
Input wineset size n and return feature array and target array.
Example:
------
n = 3
X = np.array([[80,20],[95,30],[100,15]])
y = np.array([140.0,163.6,80.0])
"""
X,y = [], []
for i in range(n):
rating = np.random.random()*50 + 50
age = np.random.random()*50
# get reference price
price = wineprice(rating,age)
# add some noise
price = price*(np.random.random()*0.4 + 0.8) #[0.8,1.2]
X.append([rating,age])
y.append(price)
return np.array(X), np.array(y)
X,y = wineset(500)
X[:3]
array([[ 88.89511317, 11.63751282],
[ 91.57171713, 39.76279923],
[ 98.38870877, 14.07015414]])
2. 相似度:欧氏距离
knn的名字叫K近邻,如何叫“近”,我们需要一个数学上的定义,最常见的是用欧式距离,二维三维的时候对应平面或空间距离。
算法实现里需要的是给定一个新的数据,需要计算其与训练数据组之间所有点之间的距离,注意是不同的维度,给定的新数据只是一个sample,而训练数据是n组,n个sample,计算的时候需要注意,不过numpy可以自动broadcat,可以很好地take care of it。
def euclidean(arr1,arr2):
"""
Input two array and output theie distance list.
Example:
------
arr1 = np.array([[3,20],[2,30],[2,15]])
arr2 = np.array([[2,20],[2,20],[2,20]]) # broadcasted, np.array([2,20]) and [2,20] also work.
d = np.array([1,20,5])
"""
ds = np.sum((arr1 - arr2)**2,axis=1)
return np.sqrt(ds)
arr1 = np.array([[3,20],[2,30],[2,15]])
arr2 = np.array([[2,20],[2,20],[2,20]])
euclidean(arr1,arr2)
array([ 1., 10., 5.])
提供一个简洁的接口,给定训练数据X和新sample v,然后返回排序好的距离,以及对应的index(我们要以此索引近邻们对应的标签值)。
def getdistance(X,v):
"""
Input train data set X and a sample, output the distance between each other with index.
Example:
------
X = np.array([[3,20],[2,30],[2,15]])
v = np.array([2,20]) # to be broadcasted
Output dlist = np.array([1,5,10]), index = np.array([0,2,1])
"""
dlist = euclidean(X,np.array(v))
index = np.argsort(dlist)
dlist.sort()
# dlist_with_index = np.stack((dlist,index),axis=1)
return dlist, index
dlist, index = getdistance(X,[80.,20.])
3. KNN算法
knn算法具体实现的时候很简单,调用前面的函数,计算出排序好的距离列表,然后对其前k项对应的标签值取均值即可。可以用该knn算法与实际的价格模型对比,发现精度还不错。
def knn(X,y,v,kn=3):
"""
Input train data and train target, output the average price of new sample.
X = X_train; y = y_train
k: number of neighbors
"""
dlist, index = getdistance(X,v)
avg = 0.0
for i in range(kn):
avg = avg + y[index[i]]
avg = avg / kn
return avg
knn(X,y,[95.0,5.0],kn=3)
32.043042600537092
wineprice(95.0,5.0)
31.666666666666664
4. 加权KNN
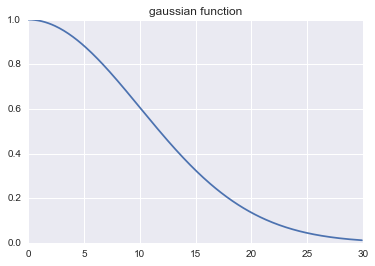
以上是KNN的基本算法,有一个问题就是该算法给所有的近邻分配相等的权重,这个还可以这样改进,就是给更近的邻居分配更大的权重(你离我更近,那我就认为你跟我更相似,就给你分配更大的权重),而较远的邻居的权重相应地减少,取其加权平均。需要一个能把距离转换为权重的函数,gaussian函数是一个比较普遍的选择,下图可以看到gaussian函数的衰减趋势。从下面的单例可以看出其效果要比knn算法的效果要好,不过只是单个例子,不具有说服力,后面给出更可信的评价。
def gaussian(dist,sigma=10.0):
"""Input a distance and return it's weight"""
weight = np.exp(-dist**2/(2*sigma**2))
return weight
x1 = np.arange(0,30,0.1)
y1 = gaussian(x1)
plt.title('gaussian function')
plt.plot(x1,y1);
def knn_weight(X,y,v,kn=3):
dlist, index = getdistance(X,v)
avg = 0.0
total_weight = 0
for i in range(kn):
weight = gaussian(dlist[i])
avg = avg + weight*y[index[i]]
total_weight = total_weight + weight
avg = avg/total_weight
return avg
knn_weight(X,y,[95.0,5.0],kn=3)
32.063929602836012
交叉验证
写一个函数,实现交叉验证功能,不能用sklearn库。
交叉验证(Cross-Validation): 有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法。于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证。 一开始的子集被称为训练集。而其它的子集则被称为验证集或测试集。常见交叉验证方法如下:
Holdout Method(保留)
- 方法:将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此Hold-OutMethod下分类器的性能指标.。Holdout Method相对于K-fold Cross Validation 又称Double cross-validation ,或相对K-CV称 2-fold cross-validation(2-CV)
- 优点:好处的处理简单,只需随机把原始数据分为两组即可
- 缺点:严格意义来说Holdout Method并不能算是CV,因为这种方法没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关系,所以这种方法得到的结果其实并不具有说服性.(主要原因是 训练集样本数太少,通常不足以代表母体样本的分布,导致 test 阶段辨识率容易出现明显落差。此外,2-CV 中一分为二的分子集方法的变异度大,往往无法达到「实验过程必须可以被复制」的要求。)
K-fold Cross Validation(k折叠)
- 方法:作为Holdout Methon的演进,将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标.K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2. 而K-CV 的实验共需要建立 k 个models,并计算 k 次 test sets 的平均辨识率。在实作上,k 要够大才能使各回合中的 训练样本数够多,一般而言 k=10 (作为一个经验参数)算是相当足够了。
- 优点:K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性.
- 缺点:K值选取上
Leave-One-Out Cross Validation(留一)
- 方法:如果设原始数据有N个样本,那么留一就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,所以留一会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标.
- 优点:相比于前面的K-CV,留一有两个明显的优点:
- a.每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
- b. 实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的.
- 缺点:计算成本高,因为需要建立的模型数量与原始数据样本数量相同,当原始数据样本数量相当多时,LOO-CV在实作上便有困难几乎就是不显示,除非每次训练分类器得到模型的速度很快,或是可以用并行化计算减少计算所需的时间。
Holdout method方法的想法很简单,给一个train_size,然后算法就会在指定的比例(train_size)处把数据分为两部分,然后返回。
# Holdout method
def my_train_test_split(X,y,train_size=0.95,shuffle=True):
"""
Input X,y, split them and out put X_train, X_test; y_train, y_test.
Example:
------
X = np.array([[0, 1],[2, 3],[4, 5],[6, 7],[8, 9]])
y = np.array([0, 1, 2, 3, 4])
Then
X_train = np.array([[4, 5],[0, 1],[6, 7]])
X_test = np.array([[2, 3],[8, 9]])
y_train = np.array([2, 0, 3])
y_test = np.array([1, 4])
"""
order = np.arange(len(y))
if shuffle:
order = np.random.permutation(order)
border = int(train_size*len(y))
X_train, X_test = X[:border], X[border:]
y_train, y_test = y[:border], y[border:]
return X_train, X_test, y_train, y_test
K folds算法是把数据分成k份,进行k此循环,每次不同的份分别来充当测试组数据。但是注意,该算法不直接操作数据,而是产生一个迭代器,返回训练和测试数据的索引。看docstring里的例子应该很清楚。
# k folds 产生一个迭代器
def my_KFold(n,n_folds=5,shuffe=False):
"""
K-Folds cross validation iterator.
Provides train/test indices to split data in train test sets. Split dataset
into k consecutive folds (without shuffling by default).
Each fold is then used a validation set once while the k - 1 remaining fold form the training set.
Example:
------
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
kf = KFold(4, n_folds=2)
for train_index, test_index in kf:
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
print("TRAIN:", train_index, "TEST:", test_index)
TRAIN: [2 3] TEST: [0 1]
TRAIN: [0 1] TEST: [2 3]
"""
idx = np.arange(n)
if shuffe:
idx = np.random.permutation(idx)
fold_sizes = (n // n_folds) * np.ones(n_folds, dtype=np.int) # folds have size n // n_folds
fold_sizes[:n % n_folds] += 1 # The first n % n_folds folds have size n // n_folds + 1
current = 0
for fold_size in fold_sizes:
start, stop = current, current + fold_size
train_index = list(np.concatenate((idx[:start], idx[stop:])))
test_index = list(idx[start:stop])
yield train_index, test_index
current = stop # move one step forward
X1 = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y1 = np.array([1, 2, 3, 4])
kf = my_KFold(4, n_folds=2)
for train_index, test_index in kf:
X_train, X_test = X1[train_index], X1[test_index]
y_train, y_test = y1[train_index], y1[test_index]
print("TRAIN:", train_index, "TEST:", test_index)
('TRAIN:', [2, 3], 'TEST:', [0, 1])
('TRAIN:', [0, 1], 'TEST:', [2, 3])
KNN算法交叉验证
万事俱备只欠东风,已经实现了KNN算法以及交叉验证功能,我们就可以利用交叉验证的思想为我们的算法选择合适的参数,这也是交叉验证主要目标之一。
评价算法
首先我们用一个函数评价算法,给定训练数据与测试数据,计算平均的计算误差,这是评价算法好坏的重要指标。
def test_algo(alg,X_train,X_test,y_train,y_test,kn=3):
error = 0.0
for i in range(len(y_test)):
guess = alg(X_train,y_train,X_test[i],kn=kn)
error += (y_test[i] - guess)**2
return error/len(y_test)
X_train,X_test,y_train,y_test = my_train_test_split(X,y,train_size=0.8)
test_algo(knn,X_train,X_test,y_train,y_test,kn=3)
783.80937472673656
交叉验证
得到平均误差,注意这里KFold 生成器的使用。
def my_cross_validate(alg,X,y,n_folds=100,kn=3):
error = 0.0
kf = my_KFold(len(y), n_folds=n_folds)
for train_index, test_index in kf:
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
error += test_algo(alg,X_train,X_test,y_train,y_test,kn=kn)
return error/n_folds
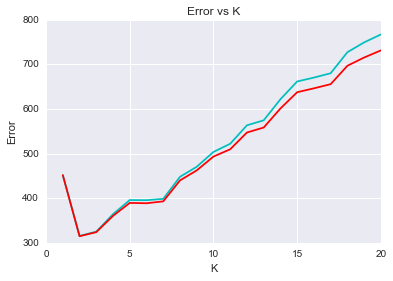
选最好的k值
从下图可以看出,模型表现随k值的变化呈现一个折现型,当为1时,表现较差;当取2,3的时候,模型表现还不错;但当k继续增加的时候,模型表现急剧下降。同时knn_weight算法要略优于knn算法,有一点点改进。
errors1, errors2 = [], []
for i in range(20):
error1 = my_cross_validate(knn,X,y,kn=i+1)
error2 = my_cross_validate(knn_weight,X,y,kn=i+1)
errors1.append(error1)
errors2.append(error2)
xs = np.arange(len(errors1)) + 1
plt.plot(xs,errors1,color='c')
plt.plot(xs,errors2,color='r')
plt.xlabel('K')
plt.ylabel('Error')
plt.title('Error vs K');












网友评论