用了一段时间的pyspider,一直没有研究源码。这两天抽空看了看,稍微拿几个点出来研究一下,如果读到哪里不对的地方,请及时指出我好纠正,本文我也会在今后实际使用过程中不断修正。
本文会有错误!写本文的目的是我希望一边写文章,一边看源码。所以并不是看完源码之后的总结,请谨慎阅读。
主要参考文章:
导航栏:
[TOC]
目录结构
1. database
2. fetcher
3. libs
4. message_queue
5. processor
6. result
7. scheduler
8. webui
结构分析
PySpider主要由scheduler,fetcher,processor三大组件,webui提供前端页面,database和result提供持久层(数据层),lib常用工具类,message_queue消息传递层。
三大数据库表
projectdb: project项目管理,管理该项目的代码,状态,速率,上一次的更新时间等基础信息。
taskdb: 组件中互相传递信息的json,封装了所有需要传递给各个组件进行使用和调用的数据,用户的整个爬虫都会被翻译成一系列的task,在组件中进行传递,最后获得结果。
resultdb: 如果将数据存在本地数据库,则一般以resultdb存储
总体结构
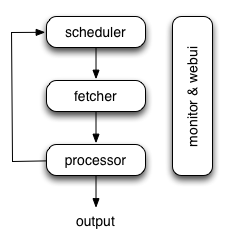 pyspider 主要流程图
pyspider 主要流程图
- 各个组件间使用消息队列连接,除了scheduler是单点组件,fetcher和processor都可以是多实例分布式部署的。scheduler负责整体的调度控制
- 任务由scheduler发起调度,fetcher抓取网页内容,processor执行预先编写(webui端)的python脚本,输出结果或产生新的提炼任务(发往scheduler),行程闭环
- 每个脚本可以灵活使用各种python库对页面进行解析,使用框架API控制下一步抓取动作,通过设置回调控制解析动作
三大组件介绍
scheduler
按照binux的介绍该组件有以下特点:
- 任务优先级
- 周期定时任务
- 流量控制
- 基于时间周期或前链标签(如更新时间)的重抓取调度
那么从源码的角度来看可以归为下面7个方法,由scheduler.py中的Scheduler类的run()方法进入run_once(),可看到下面7个方法:
def run_once(self):
'''comsume queues and feed tasks to fetcher, once'''
self._update_projects()
self._check_task_done()
self._check_request()
while self._check_cronjob():
pass
self._check_select()
self._check_delete()
self._try_dump_cnt()
这7个方法我还没完全过掉,先说我觉得正确的几个,希望之后您也可以帮我补充一下:
- [x] _update_projects() : 从projectdb中检查project,是否有过期,需不需要重爬
- [x] _check_task_done() : 从消息队列中取出消息(task)
- [ ] _check_request() :
- [ ] _check_cronjob() :
- [ ] _check_select() :
- [x] _check_delete() : 检查是否有需要删除的project,pyspider默认Status为STOP,且24小时之后自行删除
- [ ] _try_dump_cnt() :
fetcher
按照binux的介绍该组件有以下特点:
- dataurl支持,用于假抓取模拟传递
- method, header, cookies, proxy, etag, last_modified, timeout等等抓取调度控制
- 可以通过适配
类似phantomjs的webkit引擎支持渲染
fetcher中主要看 tornado_fetcher.py 和 phantomjs_fetcher.js 两个文件。
tornado_fetcher.py
-
HTTP请求
看名字就知道该.py文件和tornado有所关系,点开可以看到tornado_fetcher.py继承了tornado的两个类:
class MyCurlAsyncHTTPClient(CurlAsyncHTTPClient):
def free_size(self):
return len(self._free_list)
def size(self):
return len(self._curls) - self.free_size()
class MySimpleAsyncHTTPClient(SimpleAsyncHTTPClient):
def free_size(self):
return self.max_clients - self.size()
def size(self):
return len(self.active)
查看 tornado.httpclient - 异步HTTP客户端 文档后,很清楚的看到pyspider异步特性就是借助了tornado里的httpclient客户端。
class Fetcher(object):
还从以Fetcher类中的run方法为入口看,发现会不断从inqueue队列中取task,进行fetch;
fetch默认为异步,那么抓取的核心方法就是async_fetch(self, task, callback=None);
fetch几点步骤和内容,还没弄懂的内容我没打勾:
- [x] 从task中获得url
- [x] callback默认为None
- [x] fetch判断是否使用异步(默认全部使用)
- [x] 判断url类型,其实就是判断是否使用phantomjs(ps:这边的startwith=data没懂)判断是否是js, splash。若都不是,则为普通的HTTP请求
- [x] http_fetch可以看到就是处理cookie,重定向,robots.txt等一系列的方法
- [ ] 获得result结果后,最后写了一句raise gen.Return(result) 引发的异常退出(这块没懂),只看到tornado.gen模块是一个基于python generator实现的异步编程接口
phantomjs_fetcher.js
先附上phantomjs WebServer部分的官方文档
- [x] 使用WebServer方式,监听端口(默认为127.0.0.1:9999)
- [x] 使用POST方式(拒绝GET)提交给Phantomjs监听的端口
webPage是PhantomJS的核心模块,可以通过下面方式获得一个webPage模块的实例:
var webPage = require('webpage')
var page = webPage.create()
再介绍phantomjs_fetcher.js中几个核心的方法:
- [x] onLoadFinished : 监听页面是否加载完成
- [x] onResourceRequested : 当页面去请求一个资源时,会触发onResourceRequested()方法的回调函数。回调函数接受两个参数,第一个参数requestData是这个HTTP请求的元数据对象,包括以下属性:
* id: 所请求资源的id号,这个应该是phantomjs给标识的
* method: 所使用的HTTP方法(GET/POST/PUT/DELETE等)
* url: 所请求资源的URL
* time: 包含请求该资源时间的一个Date对象。
* headers: 该请求的http请求头中的信息数组。
- [x] onResourceReceived : onResourceReceived属性用于指定一个回调函数,当网页收到所请求的资源时,就会执行该回调函数。回调函数只有一个参数,就是所请求资源的服务器发来的HTTP response的元数据对象,包括以下字段:
* id: 所请求的资源编号,此编号phantomjs标识。
* url: 所请求的资源的URL
* time: 包含HTTP回应时间的Date对象
* headers: 响应的HTTP头信息数组
* bodySize: 解压缩后的收到的内容大小
* contentType: 接到的内容种类
* redirectURL: 重定向URL(如果有的话)
* stage: 对于多数据块的HTTP回应,头一个数据块为start,最后一个数据块为end
* status: HTTP状态码,成功时为200
* statusText: HTTP状态信息,比如OK
最后通过调用page.open发送请求给Phantomjs
通过make_result方法返回response
processor
按照binux的介绍该组件有以下特点:
- 内置的PyQuery,以jQuery解析页面
- 在脚本中完全控制调度抓取的各项参数
- 可以向后链传递信息
- 异常捕获
我还没具体看,简单的看了一眼先得出以下结论:
- [x] 去取来自fetcher的task,调用task中process变量的callback函数(python脚本,存在projectdb中)
- [x] 将合适的数据输出到result
- [x] 有其他后续任务则重新放入消息队列并返回到scheduler中。
其他组件
webui
前端页面是用Flask框架搭建的Web页面,具有以下功能:
- web 的可视化任务监控
- web 脚本编写,单步调试
- 异常捕获、log捕获、print捕获等
message_queues
因为暂时就用到了Redis,所以介绍一下源码中用到的Redis方法,其他的可见Redi官方文档
- [x] loop key : 移除并返回列表key的头元素
- [x] rpush key value : 将一个或多个value值插入到表key的表尾
- [x] llen key : 返回列表key的长度










网友评论