[TOC]
思路框架
在描述统计中,正态分布的一组数据有两个最重要的特征,一个是如何集中的(均值$\mu$),另一个是如何离散的(方差$\sigma^2$)。据此可以划分出大部分数据存在的范围(95%的数据位于$(\mu-1.96\sigma,\mu+1.96\sigma)$的命中区间之内)。不同数据可以放在同一个参考系(标准分$z=\cfrac {x-\mu} \sigma$)中比较。
推论统计是通过部分数据(样本)的特征(样本统计量,样本均值$\bar x$或样本方差$s2$),来推测估计全体数据(正态总体)的特征(总体参数,总体均值$\mu$或总体方差$\sigma2$)。这个推测的可信程度(置信区间)是运用假设检验的方法来确认的,即能够让样本统计量的观测值进入命中区间的总体参数才能被接受。解满足命中区间($上界 \leq 公式 \leq 上界$)的不等式即可。
若估计$\mu$:
|条件|公式|分布
|--
|已知$\sigma^2$|$\cfrac {\bar x - \mu} {\cfrac \sigma {\sqrt n}}$|$\bar x$呈正态分布
|未知$\sigma^2$|$\cfrac {(\bar x - \mu) \sqrt {n-1}} s$|$\bar x$呈自由度$(n-1)$的t分布
若估计$\sigma^2$:
|条件|公式|分布
|--
|已知$\mu$|$\sum _{i=1} ^n (\cfrac {x_i-\mu} \sigma)2$|$\sigma2$呈自由度$n$的卡方分布
|未知$\mu$|$\cfrac {ns^2} {\sigma2}$|$s2$呈自由度$(n-1)$的卡方分布
通过绘制直方图,可以直观的反映出数据(样本统计量的观测值)与其出现的相对频数(概率)之间的关系,即置信区间(观测值的命中区间)与概率密度曲线下的面积(相对频数之和)之间的关系。越趋近于曲线中部的数据出现的概率越大,在曲线尾部的数据几乎不可能出现。以此可作为在假设检验中接受推论假设($|统计量|>临界值$,或$p<\alpha$)的依据。
均值、方差
统计量是指用一个数来概括一组数据的特征。样本的统计量对应于总体参数。
例:投一组硬币。每次投5枚就是5个样本,即观测这一组样本的数量(统计量)为5枚。一共投了4次,则总的观测数量(总体参数)为20枚。
均值$\mu$(算术平均值)是合计意义上的平均数。
$$\mu=\frac 1 n \sum_{i=1}^n x_i=\sum 组值 \times 相对频数$$
方差$\sigma^2$反映了数据的分散(波动)程度。
$$\sigma^2 = \frac 1 n \sum_{i=1}^n (x_i - \mu)^2=\sum (组值-\mu)^2 \times 相对频数$$
其中,$x_i - \mu$称为偏差,$\sigma$称为标准差,即方差的开平方。
例:制作频数分布表,并计算$\mu$、$\sigma^2$
|数据分组|组值|频数|相对频数|累积频数|累积相对频数
|--
|1,2,3|2|3|0.3|3|0.3
|4,5,5,5,6|5|5|0.5|8|0.8
|8,8|8|2|0.2|10|1.0
相对频数为各组频数占全体的比例。各组相对频数之和为1。
$$
\begin{split}
\mu & = \frac{\sum 组值\times频数} {数据总数} \
& = \sum 组值 \times \frac{频数} {数据总数} \
& = \sum 组值 \times 相对频数 \
& = 2\times0.3 + 5\times0.5 + 8\times0.2 \
& = 4.7
\end{split}
$$
$$
\begin{split}
\sigma^2 & = \sum (组值-\mu)^2 \times 相对频数 \
& = (2-4.7)^2 \times 0.3 + (5-4.7)^2 \times 0.5 + (8-4.7)^2 \times 0.2 \
& = 4.41
\end{split}
$$
以观测的数据为横轴,其相对频数为纵轴,画出直方图,可知:
- 数据在$\mu$周边分布,多次出现的数据对$\mu$影响较大
- 若直方图左右对称,对称轴在$\mu$上
$\mu$是从数据的分布中取出的代表数,可认为数据以$\mu$为基点,左右扩散。评价这种扩散、分散的标准就是$\sigma$。$\sigma$将$\mu$的离散方式进行平均化。此时无论是正方向,还是负方向的离散,都用正数进行评价,避免相互抵消的平均。
例:全班考试成绩$\mu=60$,某人成绩$x=85$。当$\sigma=20$时,这是一般的水平。当$\sigma=10$时,那就是优秀了。
$\mu$与$\sigma$有如下性质:
|统计量|$\mu$|$\sigma^2$|$\sigma$
|--
|加上常数$c$|$\mu+k$|$\sigma^2$|$\sigma$
|扩大常数$k$|$\mu \times k$|$\sigma^2 \times k^2$|$\sigma \times k$
全部数据经过标准分$z$处理可得,$\mu=0$,$\sigma=1$。相当于为不同数据之间的比较建立了统一的参考系。显然,$1\sigma$的数据比$2\sigma$的数据更具代表性。
$$z=\cfrac {x - \mu} \sigma$$
例:甲乙球员的命中率$\mu$分别 为70,40,$\sigma$分别为20,10。本次训练的命中率$x$分别为75,55。则$z$分别为$\cfrac {75-70} {20}=0.25<1$,$\cfrac {55-40} {10}=1.5>1$。故甲球员的命中率更稳定。
其它类型的平均值:
几何平均值$\bar x = \sqrt [n] {\prod {i=1} ^n x_i}$
均方根值$x{rms} = \sqrt {\cfrac 1 n \sum _{i=1} ^n x_i ^2}$
调和平均值$H=\cfrac n {\sum _{i=1} ^n \cfrac 1 x_i}$
加权平均值$\bar x = \cfrac {\sum _{i=1} ^n w_i x_i} {\sum _{i=1} ^n w_i}$
正态分布
制作直方图的过程,其实就是数数,确定观测值与频数的关系。将直方图中分组幅度无限缩小,得到$x$的正态分布图。这是由部分事实推论全体的归纳推论。
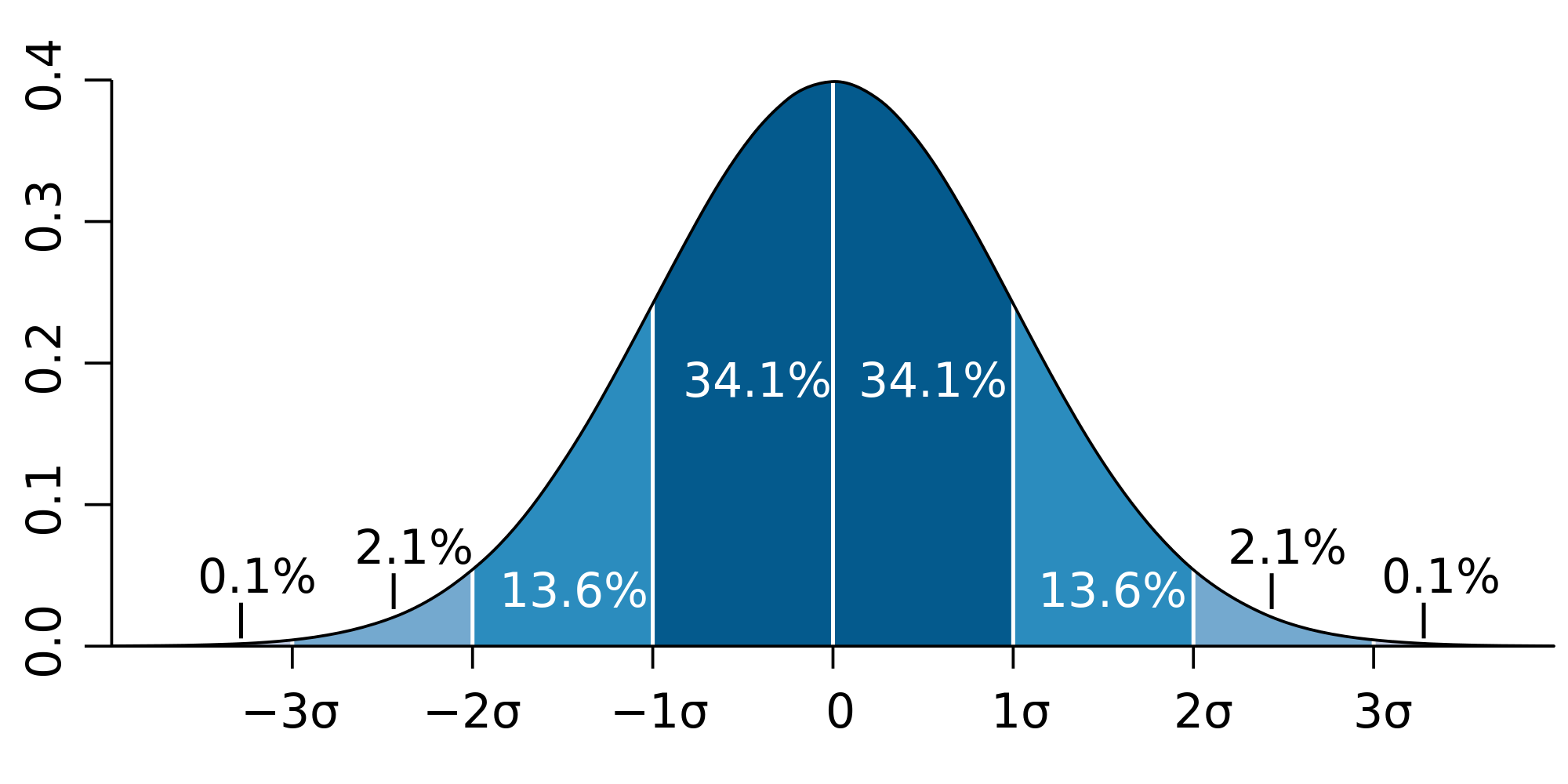
由图可知,正态分布确定了观测值$x$、曲线位置$\mu$、曲线形状$\sigma$三者与相对频数$z$之间的关系:
$$
z = \cfrac {x-\mu} \sigma
$$
当$\mu=0$,$\sigma=1$时,称为标准正态分布。性质如下:
- 概率密度函数关于$\mu$对称
- $\mu$、中位数、众数,三者相等
- 曲线之下的面积(相对频数之和)恒等于1。$(\mu-1\sigma,\mu+1\sigma)$区间的面积0.6826(70%弱),$(\mu-2\sigma,\mu+2\sigma)$区间的面积0.9544(95%强),$(\mu-1.96\sigma,\mu+1.96\sigma)$区间的面积0.95
推广到一般正态分布,
- 当$\mu<0$时,曲线左移。当$\mu>0$时,曲线右移
- 当$\sigma2<1$时,曲线高且窄。当$\sigma2>1$时,曲线平且宽
- 通过$z$回归到标准正态分布
例:一次性投$n$枚硬币,正面的数量近似于$\mu=\cfrac n 2$,$\sigma=\cfrac {\sqrt n} 2$的正态分布。
利用正态分布的性质,在95%区间(正态曲线面积为0.95)上,以$-1.96 \leq \cfrac {x-\mu} \sigma \leq +1.96$为工具,有三种类型的应用:
- 已知$\mu$与$\sigma$,预测$x$的取值范围,即命中区间
- 已知$x$与$\sigma$,检验$\mu$的合理性,即假设检验
- 已知$x$与$\sigma$,估计$\mu$的取值范围,即置信区间
命中区间
预测命中区间,是在总体参数$\mu$与$\sigma$已知的情况下,针对未发生事件$x$的预测。
例:一次投$n=36$枚硬币,预测正面的数量$x$的范围。
由正态分布可知,$\mu=\cfrac n 2 =\cfrac {36} 2=18$,$\sigma= \cfrac {\sqrt n} 2 =\cfrac {\sqrt {36}} 2=3$。解不等式
$$
\begin{gather}
-1.96 \leq \cfrac {x-\mu} \sigma \leq +1.96 \
-1.96 \leq \cfrac {x-18} 3 \leq +1.96 \
12.12 \leq x \leq 23.88
\end{gather}
$$
结论为,一次投36枚硬币,有95%的可能性,正面数量在12到24枚。
假设检验
假设检验中,假设是指“关于总体的一个普遍性论断”,检验是指“看从样本得出的结论能否推论到总体”。假设检验的逻辑是,命题只能被证否而不能被证明。个案(样本)不足以证明命题(总体),但可以否定命题(总体)。
- 首先设置一个关于总体的假设,称为虚无假设$H_0$。然后设置$H_0$的否命题,称为备选假设$H_1$。如果证否了$H_0$,相当于证明了$H_1$。所以假设检验就是要试图证否$H_0$,或者说拒绝$H_0$(无法拒绝就只能接受)
- 由于抽样的原因,样本并不可能绝对地证否$H_0$。在个案中,小概率事件可以等同于不可能发生的事件。在此意义上,需要事先约定在一个错误概率(即显著水平$\alpha$)上去拒绝$H_0$(有$\alpha$的可能性推论错误)
例:若有$10$枚硬币正面,则一次投出的硬币数量$n=36$是否合理?
第一步:构建假设
$H_0$:$n=36$,硬币总量为36枚
$H_1$:$n \neq 36$,硬币总量不是36枚
第二步:设置检验显著水平
$\alpha = 0.05$(即双侧位于$(\mu -1.96\sigma , \mu +1.96\sigma)$之外的曲线面积,$1-\alpha$为95%置信水平)。从正态图上看,$\cfrac \alpha 2$对应的坐标称为临界值。观测值$x$对应的面积称为统计量$p$值。
第三步:计算统计量进行检验判断
由正态分布可知,$\mu=\cfrac n 2 =\cfrac {36} 2=18$,$\sigma=\cfrac {\sqrt n} 2 =\cfrac {\sqrt {36}} 2=3$。因$观测值x=10 < 18=\mu$,故样本位于$\mu$的左侧。
一种方法是比较观测值与临界值。
由$左侧临界值=\mu - 1.96\sigma = 18 - 1.96 \times 3=12.12$可知,$观测值x=10 < 12.12=临界值$。
另一种方法是比较$p$与$\alpha$。
由$\cfrac {x-\mu} \sigma = \cfrac {10- 18} 3 = -2.67$,查正态分布表或公式函数计算可知对应面积为$0.9962$。在左侧,$p =1 - 0.9962 = 0.0038 < 0.025 = \cfrac {0.05} 2 = \cfrac \alpha 2$。
第四步:得出结论
如果要拒绝$H_0$,即在$H_0$出现了小概率事件(不太可能发生的事件),满足以下条件之一即可:
- 比较观测值与临界值,若样本位临界值范围之外
- 比较$p$与$\alpha$,若$p<\alpha$(双侧),或$p < \cfrac \alpha 2$(单侧)
结论为,一次投36枚硬币出现10枚正面,属于小概率事件(0.38%的可能性,不太可能发生),故硬币数量不合理。这个结论有5%的可能性出错。
置信区间
区间估计是指,在样本已知的情况下,推测未知真实值的总体参数的取值范围。以一定固定结构概率性出现的是样本观测值,而总体参数真实值是确切的,只是不知道是多少,但会有一定的概率落在样本的取值范围内。置信区间表达了对出现的观测值的可信程度(即总体参数会落在样本命中区间的概率的可信程度)。从针对总体参数的假设检验可知,在排除了$\alpha$的错误概率后,剩下的$1-\alpha$就是观测值出现概率的可信程度。$1-\alpha$对应的区间就是置信区间。
从正态分布图上看,全部观测值$x$中,有95%出现在$(\mu-1.96\sigma,\mu+1.96\sigma)$之内。总体参数$\mu$也落在这个区间内的可信程度有95%。称之为,由95%的样本观测值$x$构造的总体参数$\mu$的置信区间。
例:若有$10$枚硬币正面,则一次投出的硬币数量$n$有多少?
由正态分布可知,$\mu=\cfrac n 2$,$\sigma=\cfrac {\sqrt n} 2$,观测值$x=10$。$\mu$的95%置信区间满足:
$$
\begin{gather}
-1.96 \leq \cfrac {x-\mu} \sigma \leq +1.96 \
-1.96 \leq \cfrac {10 - \cfrac n 2} {\cfrac {\sqrt n} 2} \leq +1.96 \
12.95 \leq n \leq 30.89
\end{gather}
$$
结论为,有10枚硬币正面,则有95%的把握说,一次投出的硬币数量在13到30枚之间。
大数法则、中心极限定理
推论统计的目标是,从总体数据抽样出来的样本数据中,对总体的数据特征进行推测。如果不假设总体的分布,可以采用非参数统计。如果假设总体为正态分布,则可以采用大样本估计。
从制作直方图的过程中,抽取一组样本(分组),取其组值(样本均值$\bar x$),可以观察到:
- 相对频数反映了总体数据的构成情况。换言之,样本的观测值$x$的分布是受总体的数据特征制约的
- 从$\bar x$的渐近趋势上看,当抽样数量越多,$\bar x$接近总体均值$\mu$的可能性越高。这就是大数法则
- 从$\bar x$的数据分布上看,当抽样数量越多,$\bar x$分布越近似于正态分布。这就是中心极限定理
由此推论:正态总体取$n$个样本均值$\bar x$的分布仍为正态分布。
例:投一组硬币正面的数量,身高,股票价格等现象,均表现为正态分布。
从正态图形上,比较样本观测值$x$,与样本均值$\bar x$的分布:
|分布(直方图横轴上的观测值)|均值|标准差|形状
|--
|$x$|$\mu$|$\sigma$|平且宽
|$\bar x$|$\mu$|$\cfrac \sigma {\sqrt n}$|高且窄
由正态分布性质可知,对于均值为μ、标准差为σ的一个正态总体的n个样本均值$\bar x$来说,其95%预测命中区间为:
$$-1.96 \leq \cfrac {\bar x - \mu} {\cfrac \sigma {\sqrt n}} \leq +1.96$$
例:若正态总体的$\mu=200$,$\sigma=10$时,样本数量$n$分别为1,4,16,预测95%命中区间,分别为(180.4 , 219.6),(190.2 , 209.8),(195.1 , 204.9)。可见观测数据越多,预测区间越狭窄,预测精度越高。
正态总体,已知总体方差,估计总体均值
由样本均值$\bar x$的正态分布性质,可推测总体参数$\mu$的置信区间。实施假设检验,能够让样本均值$\bar x$进入预测命中区间的总体均值$\mu$,才能被授受。这个区间就是总体均值$\mu$的置信区间。
例:一批产品的重量允许有平均10克的浮动,从中抽取25个样品,其样品的平均重量80克。则这些产品的平均重量$\mu$有多少克?
由样本均值正态分布可知,$n=25$,$\sigma=10$,$\bar x=80$。$\mu$的95%置信区间满足:
$$
\begin{gather}
-1.96 \leq \cfrac {\bar x - \mu} {\cfrac \sigma {\sqrt n}} \leq +1.96 \
-1.96 \leq \cfrac {80 - \mu} {\cfrac {10} {\sqrt {25}}} \leq +1.96 \
76.08 \leq \mu \leq 83.92
\end{gather}
$$
结论为,这批产品平均重量在76.08至83.92克之间的可信度为95%。
正态总体,已知总体均值,估计总体方差——卡方分布
在一般正态总体中抽取$n$个样本,将方差公式中的$\sum _{i=1} ^n (x_i - \mu)^2$这一部分,使用$\cfrac {x_i - \mu} \sigma$标准化。计算统计量$\chi^2=\sum _{i=1} ^n (\cfrac {x_i - \mu} \sigma)^2$的值,作为直方图的横轴观测数据,得到正态总体的总体方差的自由度$n$的卡方分布。
卡方分布的图形呈过山车形:
- 由于平方和形式,曲线位于第一象限,故不是正态分布
- 卡方分布由正态分布构造,不同的自由度,就是不同的曲线
- 0附近的相对频数较大,曲线从左到右下落
- 随着自由度增加,远离0的相对频数增高,曲线的高度向右变低,近似于正态分布
例:正态总体的$\mu=80$,抽取76、85、83三个样本。求$\sigma^2$的置信区间。
查表可知,自由度3的卡方分布,左侧$\cfrac \alpha 2 = 0.975$以上面积为0.2157,右侧$\cfrac \alpha 2 = 0.025$以上面积为9.3484。根据假设检验,能够使卡方值在95%命中区间的$\sigma^2$才能被接受:
$$
\begin{gather}
0.2157 \leq \sum _{i=1} ^n (\cfrac {x_i-\mu} \sigma)^2 \leq 9.3484 \
0.2157 \leq \cfrac {(76-80)^2 + (85-80)^2 + (83-80)^2} {\sigma^2} \leq 9.3484 \
5.34 \leq \sigma^2 \leq 231.80
\end{gather}
$$
正态总体,未知总体均值,估计总体方差
在一般正态总体中抽取$n$个样本,在方差公式中使用样本均值$\bar x$,然后加入总体方差$\sigma^2$参与变换,可得样本方差:
$$s^2 = \frac 1 n \sum_{i=1}^n (x_i - \bar x)^2=\cfrac {\sigma^2} n \sum _{i=1} ^n (\cfrac {x_i-\bar x} \sigma)^2$$
可证明,统计量$\chi^2=\sum _{i=1} ^n (\cfrac {x_i-\bar x} \sigma)^2= \cfrac {ns^2} {\sigma^2}$为正态总体的样本方差的自由度$(n-1)$的卡方分布。
例:取一批零件的5个样品,重量分别为76,85,82,80,77克,则这批零件重量的平均浮动范围是多少?
样品$\bar x=\cfrac {\sum _{i=1} ^n x_i} n=\cfrac {76+85+82+80+77} 5=80$克。
样品$s^2=\cfrac 1 n \sum _{i=1} ^n (x_i - \bar x)^2 = \cfrac {(76-80)^2 + (85-80)2+(82-80)2 + (80-80)^2 + (77-80)^2} 5 = 10.8$克。
查卡方分布表可知,自由度$(n-1)=5-1=4$的卡方分布的95%命中区间满足:
$$
\begin{gather}
0.4844 \leq \cfrac {ns^2} {\sigma^2} \leq 11.1433 \
0.4844 \leq \cfrac {5 \times 10.8} {\sigma^2} \leq 11.1433 \
2.2 \leq \sigma \leq 10.6
\end{gather}
$$
结论为,这批零件重量平均浮动在2.2到10.6克之间,可信度为95%。
正态总体,未知总体方差,估计总体均值——t分布
在正态总体抽取的$n$个样本中,样本均值$\bar x$服从正态分布,样本方差$s^2$服从卡方分布,可以推导出统计量:
$$
t=\cfrac {标准正态分布 \times \sqrt {自由度 - 1}} {\sqrt {卡方分布}} = \cfrac {\cfrac {\bar x - \mu} {\cfrac \sigma {\sqrt n}} \cdot \sqrt {n-1}} {\sqrt {\cfrac {ns^2} {\sigma^2}}} = \cfrac {(\bar x - \mu) \sqrt {n-1}} s
$$
称为正态总体的样本均值$\bar x$的自由度$(n-1)$的t分布。
t分布是以0为中心,左右对称的一簇曲线。与正态曲线相比更缓和(即山顶略低,山脚略高),其形态变化与自由度$(n-1)$有关。自由度越小,曲线越低平;自由度越大,曲线越接近标准正态分布曲线。这说明,当$n$并不是足够大(小样本)的时候,t分布和标准正态分布的偏差不能被忽略。
例:取一批零件的6个样品,重量分别为76,85,82,83,76,78克,则这批零件平均重量是多少?
样品$\bar x=\cfrac {\sum _{i=1} ^n x_i} n=\cfrac {76+85+82+83+76+78} 6=80$克。
样品$s=\sqrt {\cfrac 1 n \sum _{i=1} ^n (x_i - \bar x)^2} = \sqrt {\cfrac {(76-80)^2 + (85-80)2+(82-80)2 + (83-80)^2 + (76-80)^2 + (78-80)^2} 6} = 3.51$克。
查t分布表可知,自由度$(n-1)=6-1=5$的t分布的95%命中区间满足:
$$
\begin{gather}
-2.571 \leq \cfrac {(\bar x - \mu) \sqrt {n-1}} s \leq +2.571 \ -2.571 \leq \cfrac {(80 - \mu) \sqrt {6-1}} {3.51} \leq +2.571 \
75.964 \leq \mu \leq 80.036
\end{gather}
$$
结论为,这批零件平均重量在75.964到80.036克之间,可信度为95%。
本书信息
书名:你一定爱读的极简统计学:再精简下去,就不是统计学了
著者:小岛宽之
译者:孔霈
ISBN:978-7-5168-0451-3




网友评论