本文为翻译文章,原文链接见文末
在第一部分中我们了解了许多基础知识,结束了语法的学习,我们可以进入下一个更有趣的部分:使用静态类型的优势和劣势
使用静态类型的优势
静态类型会给我们写代码提供很多好处。下面我们就来探讨一下。
优势一:你可以尽早发现bug和错误
静态类型检查允许我们在程序没有运行之前就可以确定我们所设定的确定性是否是对的。一旦有违反这些既定规则的行为,它能在运行之前就发现,而不是在运行时。
一个例子:假设我们有一个简单的方法,输入半径,计算面积:
const calculateArea = (radius) => 3.14 * radius * radius;
var area = calculateArea(3);
// 28.26
现在,如果你要给radius传一个非数值的值(例如‘im evil’)
var area = calculateArea('im evil');
// NaN
会返回一个NaN。如果其他某些功能要依赖这个方法,并且需要始终返回一个数值类型,那在这种返回结果下,就会导致一个bug甚至崩溃。不理想。。。
当我们使用了静态类型,我们就可以准确确认一个方法的输入与输出:
const calculateArea = (radius: number): number => 3.14 * radius * radius;
现在在试着给calculateArea方法传入一个非数值类型,这时候Flow就会显示如下信息:
calculateArea('Im evil');
^^^^^^^^^^^^^^^^^^^^^^^^^ function call
calculateArea('Im evil');
^^^^^^^^^ string. This type is incompatible with
const calculateArea = (radius: number): number => 3.14 * radius * radius;
^^^^^^ number
现在我们能确保这个方法只会接受有效的数值作为参数,并且返回一个有效的数值。
因为类型检查器会在你编码的时候就告诉你错误,所以这也就比你把代码交付到客户手中才发现一些错误要更方面(或者说付出更少的开发与维护成本)。
优势二:起到在线文档的功能
对我们和其他接触我们代码的人而言,类型就好像是一个文档。
通过我之前工作项目里一大段代码中的一个方法,我们可以看看具体是怎么用的:
function calculatePayoutDate(quote, amount, paymentMethod) {
let payoutDate;
/* business logic */
return payoutDate;
}
第一眼看到这个方法(即使是第二眼、第三眼……),我没法搞清楚要如何使用它。
quote参数是一个数值型么?还是一个boolean型?paymentMethod是一个对象么?还是仅仅就是一个代表着支付方式的字符串?这个方法会返回一个表示日期的字符串么?还是一个Date对象?
没有任何的提示……
这个时候我就只能各种看业务逻辑,在代码库里到处检索,直到我最终搞清楚了。但是,就为了要理解这简单的一个方法,费了九牛二虎之力。
如果是另一种情况,我们向下面这样来写:
function calculatePayoutDate(
quote: boolean,
amount: number,
paymentMethod: string): Date {
let payoutDate;
/* business logic */
return payoutDate;
}
这一下就让方法的输入参数和返回值的类型变得清晰了。这一场景展示了,我们如何用静态类型来表达方法的含义。通过这样做,我们可以很好得与其他开发者交流,什么是我们的方法所期望的,而什么值又是他们希望从方法中获取的。下一次他们使用到这个方法的时候,就不会产生疑问了。
当然,也有人会说,在方法上加上一段注释文档不也能解决同样的问题么:
/*
@function Determines the payout date for a purchase
@param {boolean} quote - Is this for a price quote?
@param {boolean} amount - Purchase amount
@param {string} paymentMethod - Type of payment method used for this purchase
*/
function calculatePayoutDate(quote, amount, paymentMethod) {
let payoutDate;
/* .... Business logic .... */
return payoutDate;
};
这确实是个办法。但是这种方式会更冗长。除了冗长之外,由于可依赖性较低,同时缺乏结构化,因此像这样的代码注释会难以维护。一些开发者会写出不错的注释,而另一些人的注释可能含糊不清,甚至有些根本忘了写注释。
尤其是当你重构代码的时候,你很容易就会忘记去更新相应的注释。然而,类型声明有着定义好的语法和结构,不会随着时间推移而消失——它们是被写在代码里的。
优势三:减少了复杂的错误处理
类型可以帮助我们减少复杂的错误处理。让我们重新回去看一看calculateArea方法,看看它是怎么做到的:
const calculateAreas = (radii) => {
var areas = [];
for (let i = 0; i < radii.length; i++) {
areas[i] = PI * (radii[i] * radii[i]);
}
return areas;
};
这个方法是有效的,但是它不能正确处理无效的输入参数。如果你想要确保这个方法能够正确处理输入参数非有效数组的情况,你可能需要把它改成下面这个样子:
const calculateAreas = (radii) => {
// Handle undefined or null input
if (!radii) {
throw new Error("Argument is missing");
}
// Handle non-array inputs
if (!Array.isArray(radii)) {
throw new Error("Argument must be an array");
}
var areas = [];
for (var i = 0; i < radii.length; i++) {
if (typeof radii[i] !== "number") {
throw new Error("Array must contain valid numbers only");
} else {
areas[i] = 3.14 * (radii[i] * radii[i]);
}
}
return areas;
};
哈?就这点功能就要码这么多行。
但是有了静态类型,就变得简单了:
const calculateAreas = (radii: Array<number>): Array<number> => {
var areas = [];
for (var i = 0; i < radii.length; i++) {
areas[i] = 3.14 * (radii[i] * radii[i]);
}
return areas;
};
现在,这个方法实际上看起来就和最初的很类似,没有了令人视觉上混乱的错误处理。这还是很容易能看出它的优势的,对吧?
优势四:使你在重构时更有信心
我会通过一个趣事来解释这一点:我曾经的工作涉及一个非常大型的代码库,我们需要更新里面的User类的一个方法。特别的,我们需要将方法中的一个参数从string变为object。
我改了这个方法,但是当我提交更新的时候却感到手脚发凉——这个方法在代码库里有太多的地方调用了,以至于我不确定我是否已经修改了所有的实例。如果有些不在测试帮助文件里的深层调用被我遗留了怎么办呢?
唯一可以搞清楚这一点的方法就是,提交这份代码并且祈祷不会出现一些错误。
使用静态类型将会避免这种情况。这会保证,如果更新了方法,并且相应地更新了类型定义,那么类型检查器将会帮我去捕获我遗漏的错误。我所需要做的就是,浏览这些错误并修复它们。
优势五:将数据和行为分离
一个较少谈及的关于静态类型的优点是,它可以帮助我们进行数据和行为的分离。
让我们再来回顾一下包含静态类型的calculateAreas方法:
const calculateAreas = (radii: Array<number>): Array<number> => {
var areas = [];
for (var i = 0; i < radii.length; i++) {
areas[i] = 3.14 * (radii[i] * radii[i]);
}
return areas;
};
思考一下我们是如何来编写、设计这个方法的。由于我们声明了类型,我们必须先考虑我们打算要使用的数据类型,以便于我们可以大体定义好输入与输出的类型。
 image
image
这之后我们才会去填充具体的逻辑实现部分:
 image
image
这个能力恰恰表明了,数据和行为的分离是我们更明确我们的脑海中对方法的设想,同时也更准确地传达我们的意图,这种方式减轻了无关的思维负担,使我们对程序的思考更加纯粹与清晰。(译者:这应该是程序设计时对我们思维方式的一种提示、引导与规范)
优势六:帮助我们消除了一整类bug
作为JavaScript开发者,我们最常遇见的错误就是运行时的类型错误。
举个例子,应用程序最初是的状态被定义为:
var appState = {
isFetching: false,
messages: [],
};
假设接下来我们创建了一个用来获取messages数据的API。然后,我们的app有一个简单的组件会将messages(在state中定义的)作为属性来装载,并且显示未读数量和messages的列表:
import Message from './Message';
const MyComponent = ({ messages }) => {
return (
<div>
<h1> You have { messages.length } unread messages </h1>
{ messages.map(message => <Message message={ message } /> )}
</div>
);
};
如果这个获取messages数据的API失败了或是返回了undefined,在生产环境中这段程序就会出现一个类型错误:
TypeError: Cannot read property ‘length’ of undefined
……然后我们的程序就崩溃了。你就这么失去了你的客户。僵……
让我们看看类型检查在这有什么作用。首先是给应用的state添加类型。我会使用类型别名的功能,创建一个AppState类型,然后用它来定义state:
type AppState = {
isFetching: boolean,
messages: ?Array<string>
};
var appState: AppState = {
isFetching: false,
messages: null,
};
由于知道了获取messages的API并不可靠,因此在这里我给messages定义了一个为字符串数组的maybe类型。
最后同样的,我们在view层组件中获取messages,并将它渲染在组件中。
import Message from './Message';
const MyComponent = ({ messages }) => {
return (
<div>
<h1> You have { messages.length } unread messages </h1>
{ messages.map(message => <Message message={ message } /> )}
</div>
);
};
Flow会帮我们捕获并将错误告知我们:
<h1> You have {messages.length} unread messages </h1>
^^^^^^ property `length`. Property cannot be accessed on possibly null value
<h1> You have {messages.length} unread messages </h1>
^^^^^^^^ null
<h1> You have {messages.length} unread messages </h1>
^^^^^^ property `length`. Property cannot be accessed on possibly undefined value
<h1> You have {messages.length} unread messages </h1>
^^^^^^^^ undefined
{ messages.map(message => <Message message={ message } /> )}
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ call of method `map`. Method cannot be called on possibly null value
{ messages.map(message => <Message message={ message } /> )}
^^^^^^^^ null
{ messages.map(message => <Message message={ message } /> )}
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ call of method `map`. Method cannot be called on possibly undefined value
{ messages.map(message => <Message message={ message } /> )}
^^^^^^^^ undefined
Wow!
由于我们将messages定义为maybe类型,因此messages可以是null或者undefined。但在没有进行空检查的情况下,我们仍然不能在它上面进行一些操作(像是.length或.map)。因为如果messages的值是null或者undefined的话,而我们又在它上面进行了相关操作,程序同样会报一个类型错误。
因此我们回头去更新一下view层的代码:
const MyComponent = ({ messages, isFetching }: AppState) => {
if (isFetching) {
return <div> Loading... </div>
} else if (messages === null || messages === undefined) {
return <div> Failed to load messages. Try again. </div>
} else {
return (
<div>
<h1> You have { messages.length } unread messages </h1>
{ messages.map(message => <Message message={ message } /> )}
</div>
);
}
};
现在Flow知道我们已经对null或者undefined的情况进行了处理,因此类型检查器不会报任何错误。当然,运行时的类型错误也就不会再来烦你啦。
优势七:减少单元测试的数量
在之前的部分我们已经知道了,静态类型是如何通过确保输入与输出的类型来帮助消除复杂的错误处理。因此,它也可以帮助我们减少单元测试的数量。
例如,在包含了错误处理的动态类型方法calculateAreas中:
const calculateAreas = (radii) => {
// Handle undefined or null input
if (!radii) {
throw new Error("Argument is missing");
}
// Handle non-array inputs
if (!Array.isArray(radii)) {
throw new Error("Argument must be an array");
}
var areas = [];
for (var i = 0; i < radii.length; i++) {
if (typeof radii[i] !== "number") {
throw new Error("Array must contain valid numbers only");
} else {
areas[i] = 3.14 * (radii[i] * radii[i]);
}
}
return areas;
};
如果你是一个勤劳的程序员,为了确保输入参数在程序中处理正确,也许你会想对输入参数的有效性添加测试:
it('should not work - case 1', () => {
expect(() => calculateAreas([null, 1.2])).to.throw(Error);
});
it('should not work - case 2', () => {
expect(() => calculateAreas(undefined).to.throw(Error);
});
it('should not work - case 2', () => {
expect(() => calculateAreas('hello')).to.throw(Error);
});
等等一系列测试。此外,我们很可能会忘了添加一下边缘用例的测试,而恰好我们的用户发现了它。
由于这些测试是基于我们所有想到的用例,因此就存在一些很容易被忽略的。
在另一方面,当我们需要去定义一些类型:
const calculateAreas = (radii: Array<number>): Array<number> => {
var areas = [];
for (var i = 0; i < radii.length; i++) {
areas[i] = 3.14 * (radii[i] * radii[i]);
}
return areas;
};
不仅仅是确保了代码实际运行的结果和我们的意图一致,也使得它们不容易被我们漏掉。不同于以经验为主的测试,类型检查是通用的。
这个场景的意思是:在逻辑测试中,测试是很不错的;而在数据类型的测试中,类型检查则较好。将两者结合可以起到一加一大于二的效果。
优势八:提供了领域建模(domain modeling)工具
关于类型检查,我最喜欢的一个应用场景是领域建模。领域模型是,一个同时包括了数据和基于该数据的行为的该领域的概念模型。
A domain model is a conceptual model of a domain that includes both the data and behavior on that data.
理解如何使用类型来进行领域建模的最好的方法就是看一个例子。
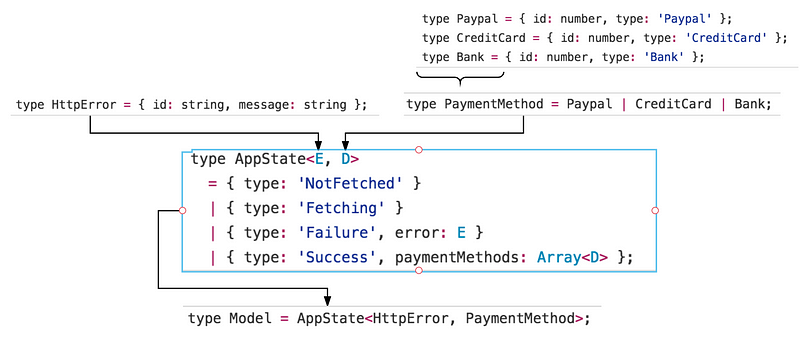
假设现在有一个应用,用户在这个平台上有一种或多种购买商品的支付方式。现在Paypal、信用卡和银行账户这三种方式是可供选择的。
我们首先给这三种支付方式创建相应的类型别名:
type Paypal = { id: number, type: 'Paypal' };
type CreditCard = { id: number, type: 'CreditCard' };
type Bank = { id: number, type: 'Bank' };
现在我们可以用这三种情况和或运算符来定义我们的PaymentMethod类型:
type PaymentMethod = Paypal | CreditCard | Bank;
这样足够了么?好吧,我们知道,当我们使用支付方法时,我们需要请求一个API,并且,根据我们所处的不同的请求阶段,我们的app的状态也是不同的。因此,会有四种可能的状态:
- 我们已经获取到了支付方法
- 我们正在获取支付方法
- 我们成功获取了支付方法
- 我们尝试去获取了支付方法但是出现了错误
但是我们上面这个简单的paymentMethods类型的模型并没有覆盖所有的场景。而是假设paymentMethods是始终存在的。
有什么办法能给我们的应用状态建一个模型,使它居且仅居这四个状态之一么?让我们来看一下:
type AppState<E, D>
= { type: 'NotFetched' }
| { type: 'Fetching' }
| { type: 'Failure', error: E }
| { type: 'Success', paymentMethods: Array<D> };
我们使用了“|”或运算符来定义我们的应用状态是上面描述的这四种中的一种。注意我是怎么使用type属性来确定app的状态是四个中的哪一个的。使用这种方式,我们就可以分析确定什么时候我们获取到了支付方法,而是什么时候没有。
你还会注意到,我给应用状态传入的泛型E和D。类型D代表了用户的支付方法(之前定义的PaymentMethod)。我们没有定义类型E,这会是我们的错误类型(error type)。下面我们可以这么做:
type HttpError = { id: string, message: string };
总得来说,现在我们的应用状态的标识是AppState<E, D>——E是HttpError类型,D是PaymentMethod支付方式。并且AppState有四个可能(且只有这四种)的状态:NotFetched、Fetching、Failure和Success。
 image
image
我发现这种领域建模的类型对我们思考user interfaces的构建而不是特定的业务逻辑很有帮助。业务规则告诉我们,我们的应用只会是这些状态中的一个。这使得我们可以明确地构建应用的状态,并且保证其只会是预先定义的状态中的一种。当我们构建了这样一个模型(例如一个view层组件),很明显,我们需要去处理所有这四种可能的状态。
更进一步地,这段代码变得很清晰(self-documenting),你可以根据这些可能的场景立即搞清楚应用状态的结构。
使用静态类型的劣势
正如生活与编程中的其他东西,静态类型检查也有着它的利弊取舍。
重要的一点是,我们学习并理解静态类型,这样就可以对何时静态类型是有意义的与何时它们并没那么有价值的问题有一个明智的判断。
下面就是一些相关的思考:
劣势1:需要预先学习静态类型相关知识
对初学者来说,JavaScript真的是一门不错的语言,原因之一就是在写代码之前你不需要去了解完整的类型系统。
当我最开始学习Elm(一门静态类型语言),类型相关的问题经常会出现,我总是会写出一些类型定义相关的编译错误。
有效的学习一门语言的类型系统可以说和学习语言本身一样都是一场硬仗。因此,静态类型使得Elm的学习曲线比JavaScript要陡峭。
尤其是对于一些初学者,学习语法本身就是一件高负荷的事情了。在去混杂着学习类型会搞垮他们。
劣势2:代码的冗长会让你头疼
静态类型经常会让代码看起来更冗长和杂乱。
例如,我们要替换下面这段代码:
async function amountExceedsPurchaseLimit(amount, getPurchaseLimit){
var limit = await getPurchaseLimit();
return limit > amount;
}
我们需要这么写:
async function amountExceedsPurchaseLimit(
amount: number,
getPurchaseLimit: () => Promise<number>
): Promise<boolean> {
var limit = await getPurchaseLimit();
return limit > amount;
}
在譬如,替换下面这段:
var user = {
id: 123456,
name: 'Preethi',
city: 'San Francisco',
};
需要写成:
type User = {
id: number,
name: string,
city: string,
};
var user: User = {
id: 123456,
name: 'Preethi',
city: 'San Francisco',
};
显然,我们添加了一些额外的代码。但是,有几个观点并不认为这是不好的。
首先,正如我们之前所提到的,静态类型帮助我们消除了一整类测试。一些开发者会认为这是一个很合理的这两方面的权衡。
其次,正如之前看到的,静态类型有的时候可以消除复杂的错误处理,反而可以较大的减少代码的杂乱性。
很难说静态类型是否真的让代码变得冗长了,但我们可以在实际工作中保留对这个问题的思考。
劣势3:需要花时间去掌握类型
学会怎么最好地在程序里定义类型需要花很多时间来进行实践。而且,建立一个良好的意识——何时使用静态类型、何时使用动态类型,也需要认真的思考和丰富的实践经验。
例如,我们可能采取的一种方式是,对关键的业务逻辑使用类型,而对临时性的、不重要的逻辑部分使用动态类型来降低不必要的复杂度。
这还是很难区分的,尤其是当开发者对类型使用的经验较少时。
劣势4:静态类型可能会延缓一些开发速度
正如前文提到的,当我学习Elm时,学习使用类型给我带来了些小阻碍,尤其是当我需要加一些或改一些代码时。经常出现编译错误让我心烦意乱,很难感觉到自己的进步。
有人认为,静态类型检查在绝大多数情况下,可能会导致程序员精力不集中,而我们知道,集中精神是写出好代码的关键。
不仅仅如此,静态类型检查器也不总是完美的。有时候你知道自己需要怎么做而类型检查器反而成为了绊脚石。
我相信还有一些其他需要取舍的地方,但上面这几条是对我来说很重要的。
下一部分,最终的结论
在最后一部分,通过讨论使用静态类型是否有意义,进行总结。
原文:Why use static types in JavaScript? The Advantages and Disadvantages)




网友评论