消息中间件在解决异步处理,模块间解耦和,和高流量场景的削峰,等情况下有着很广泛的应用 .
本文将跟大家一起讨论以下其中的异常场景,如题.
场景
在实际工作中,大家可能也都遇到过这样的需求 :
如 : 系统A中的某些重要的数据,想在每次数据变更的时候,将当前最新的数据备份下来,当然,这个备份的动作不能影响当前数据变更的进程.
也更不期望因为备份的操作,影响当前进程的性能.
分析
这是一个比较常见的,可以异步处理的需求,业务数据变更 和 数据备份 之间并没有强一致性的要求,大致的架构如下:
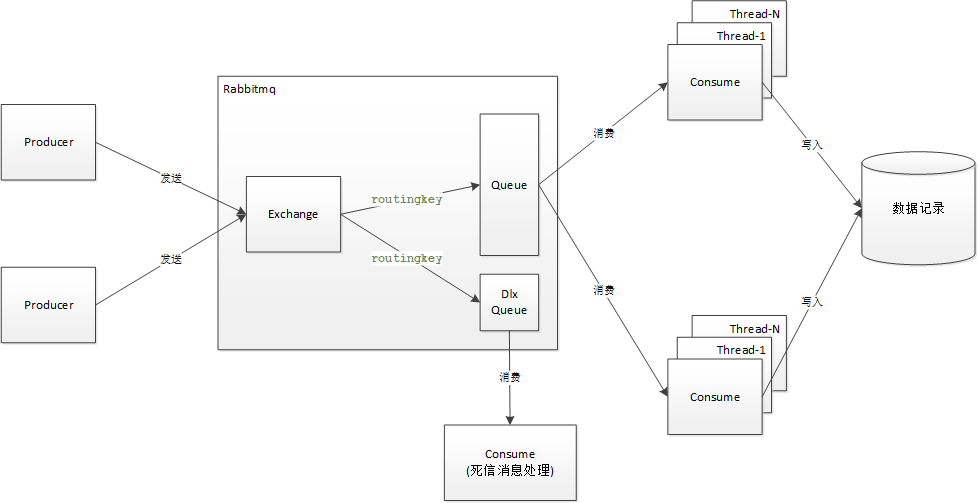 并发消费消息
并发消费消息
producer作为消息产生者,会通过指定的交换机(exchange)和路由键(routingkey),将消息传输到指定的队列(queue)中,通常producer也会有多个节点
consume作为消息的消费者,会依次从队列(queue)中拿到消息,进行业务处理,最终将数据写入数据库中,并且为了更快速的消费消息,consume通常会部署多个节点,并且每个节点中也会有多个线程同时消费消息
queue作为消息队列,保证了消息被消费的时序性,以及唯一性(一条消息只能被消费一次)
dlxQueue作为死信队列,当queue中的的消息无法被正常消费时,当重处理N次后,将会被放入死信队列,并有专门的consume来消费和处理,比如:通知相关人员进行人工干预,等.
问题
producer会源源不断的产生消息,有新的数据,也有更新老的数据,
而consume则是拿到消息,做insert或者update的操作.
但是由于consume是多线程并发消费消息的,那么就会出现当前线程拿到的消息并非最新版本的消息,如果这个时候进行了update操作的话,很有可能会覆盖掉已经是最新版本的数据了
如 : 当前数据库里的数据为1,业务操作先是将1改为了2,然后马上的又将2改为了3,这两个操作时间非常接近,几乎是同时,然后产生的消息也几乎同时的进入了消息中间件,
但是在queue里依然有先后,2在前3在后(queue机制保证),那么这个时候,consume来消费了,由于consume是多线程的,所以,2和3会被分配到两条线程中同时被处理
这时,如果2的这条线程先结束,3的这条线程后结束,那么则数据正常,最终数据被更新成3
但是,如果3的这条线程先结束了,2的这条线程是后结束的,那么,最新的数据就会被老数据覆盖掉
这种情况显然是不满足需求记录当前最新的数据的,
并且这种情况很容易发生,虽然queue里保证了消息的先后,以及唯一性,但是消息被consume在线程中消费确实同时处理的
脏读的问题
通常以上这种情况,网络上的一些解决方案,都是在数据中加入版本(version)的概念来解决,本文也是(上文提及的1,2,3,其实就是版本的概念).
通常网络上的描述是,在update的时候,根据数据库中的最新版本号,如果当前消息的版本号小于数据库最新的版本号,则放弃更新,大于,则更新
这一段逻辑很简单,但是也很容易产生误解,最大的问题在于获得最新版本号,在多线程环境下,数据库的脏读也是蛮严重的,脏读的存在,导致你查询出来的数据并非是最新的数据
如 : 上面的一个场景,数据库中最新的版本号是1,有版本号2和3两个消息是即将要消费的,按照上面的逻辑,处理程序应该先查数据库,拿到当前最新的版本.
这个时候,两条线程查询到的结果有可能都是1,这时2>1,并且3>1,两条线程依然都会执行,同样的 :
如果2的这条线程先结束,3的这条线程后结束,那么则数据正常,最终数据被更新成3
如果3的这条线程先结束了,2的这条线程是后结束的,那么,最新的数据就会被老数据覆盖掉
同样达到想要的效果
如何保证入库的数据是最新的?
其实要实现很简单,首先,要知道,对于同一行数据,sql的执行也是有先后顺序的,其实到底更新为2的sql语句先执行,还是更新为3的sql语句先执行,并不重要
重要的是,将判断版本号的语句放入更新条件中进行判断.
例子 : 同样是上面的场景,数据库中的版本为1,这时2和3同时更新,谁先结束,谁也不知道,也无法控制(其实有办法,但是损失性能,当前场景需要的是高效)
但是我们可以在条件中加入"version < 2"这样的条件
SQL语句样例 :
UPDATE TEST_MSG
SET
VERSION = #{version},
DATA = #{data},
LAST_UPDATE_DATE = #{lastUpdatedDate}
WHERE BUSINESS_KEY = #{businessKey} AND VERSION < #{version}
这样的话,无论那条线程先结束,都不会影响最终的结果
如果,2先结束,3线程的条件为2 < 3,条件成立,数据将会被更新为3
如果,3先结束,2线程的条件为3 < 2,条件不成立,数据则不会更新(由于是在sql执行过程中判断,所以这里不存在脏读的情况)
这样就能满足记录当前最新的数据的需求了
实现 (springboot使用rabbitmq的例子)
spring.rabbitmq.host=itkk.org
spring.rabbitmq.port=5672
spring.rabbitmq.username=dev_udf-sample
spring.rabbitmq.password=1qazxsw2
spring.rabbitmq.virtual-host=/dev_udf-sample
spring.rabbitmq.template.retry.enabled=true
spring.rabbitmq.listener.simple.retry.enabled=true
spring.rabbitmq.listener.simple.concurrency=5
spring.rabbitmq.listener.simple.max-concurrency=10
以上配置文件配置了rabbitmq的连接,也指定了消费者监听器的并发数量(5)和最大并发数量(10),并且开启了重试,重试失败的消息会被流转到死信队里里
@Configuration
public class UdfServiceADemoConfig {
public static final String EXCHANGE_ADEMO_TEST1 = "exchange.ademo.test1";
public static final String QUEUE_ADEMO_TEST1_CONSUME1 = "queue.ademo.test1.consume1";
public static final String ROUTINGKEY_ADEMO_TEST1_TESTMSG = "routingkey.ademo.test1.testmsg";
@Bean
public DirectExchange exchangeAdemoTest1() {
return new DirectExchange(EXCHANGE_ADEMO_TEST1, true, true);
}
@Bean
public Queue queueAdemoTest1Consume1() {
return new Queue(QUEUE_ADEMO_TEST1_CONSUME1, true, false, true);
}
@Bean
public Binding queueAdemoTest1Consume1Binding() {
return new Binding(QUEUE_ADEMO_TEST1_CONSUME1,
Binding.DestinationType.QUEUE, EXCHANGE_ADEMO_TEST1,
ROUTINGKEY_ADEMO_TEST1_TESTMSG, null);
}
}
exchangeAdemoTest1方法定义了一个交换机,并且是自动删除的
queueAdemoTest1Consume1定义了一个消费者队列,也是自动删除的
queueAdemoTest1Consume1Binding将上面定义的交换机和消费者绑定起来,并设定了路由键(routingkey)
public class TestMsg implements Serializable {
/**
* 描述 : id
*/
private static final long serialVersionUID = 1L;
/**
* msgId
*/
private String msgId = UUID.randomUUID().toString();
/**
* businessKey
*/
private String businessKey;
/**
* version
*/
private long version;
/**
* data
*/
private String data;
/**
* lastUpdatedDate
*/
private Date lastUpdatedDate;
}
以上定义了消息的格式,主要的字段就是businessKey和version,分别用来确定唯一的业务数据和版本的判断
@Autowired
private AmqpTemplate amqpTemplate;
@Scheduled(fixedRate = SCHEDULED_FIXEDRATE)
public void send1() {
this.send();
}
public void send2() {
.....
}
/**
* send
*/
private void send() {
final int numA = 1000;
int a = (int) (Math.random() * numA);
long b = (long) (Math.random() * numA);
TestMsg testMsg = new TestMsg();
testMsg.setBusinessKey(Integer.toString(a));
testMsg.setVersion(b);
testMsg.setData(UUID.randomUUID().toString());
testMsg.setLastUpdatedDate(new Date());
amqpTemplate.convertAndSend(UdfServiceADemoConfig.EXCHANGE_ADEMO_TEST1,
UdfServiceADemoConfig.ROUTINGKEY_ADEMO_TEST1_TESTMSG, testMsg);
}
以上定义了用于做测试的消息发送方,使用计划任务,定期的向交换机中写入数据,可以定义多个计划任务,增加同一时间消息产生的数量
@RabbitListener(queues = UdfServiceADemoConfig.QUEUE_ADEMO_TEST1_CONSUME1)
public void consume1(TestMsg testMsg) {
if (testMsgRespository.count(testMsg.getBusinessKey()) > 0) {
int row = testMsgRespository.update(testMsg);
log.info("update row = {}", row);
} else {
try {
int row = testMsgRespository.insert(testMsg);
log.info("insert row = {}", row);
} catch (Exception e) {
//进行异常判断,确定是主键冲突错误
int row = testMsgRespository.update(testMsg);
log.info("update row = {}", row);
}
}
try {
final long time = 5L;
Thread.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
以上定义了消息消费的方法,此方法是多线程执行的,大概逻辑是,先count数据库,判断数据是否存在,如果存在,则update数据,如果不存在,则insert数据
但是count也有可能存在脏读的情况,所以insert操作有可能会因为主键重复而失败,这时,会捕获到异常,通过异常判断,确定是主键冲突错误后(样例代码中省略了),在进行update操作
这里的update操作,则是上文提到的采用"version < #{updateVersion}"的方法进行更新,保证了将最新的数据更新到数据库中
最后的线程休眠,是为了模拟处理时间,以便造成更多的并发情况
int count(@Param("businessKey") String businessKey);
int insert(TestMsg testMsg);
int update(TestMsg testMsg);
<select id="count" resultType="int">
SELECT COUNT(*)
FROM TEST_MSG
WHERE BUSINESS_KEY = #{businessKey}
</select>
<insert id="insert">
INSERT INTO TEST_MSG
(
BUSINESS_KEY,
VERSION,
DATA,
LAST_UPDATE_DATE
)
VALUES
(
#{businessKey},
#{version},
#{data},
#{lastUpdatedDate}
)
</insert>
<update id="update">
UPDATE TEST_MSG
SET
VERSION = #{version},
DATA = #{data},
LAST_UPDATE_DATE = #{lastUpdatedDate}
WHERE BUSINESS_KEY = #{businessKey} AND VERSION <![CDATA[ < ]]> #{version}
</update>
以上为相关的sqlmap定义以及mapper接口的定义
CREATE TABLE TEST_MSG
(
BUSINESS_KEY VARCHAR(100) NOT NULL
PRIMARY KEY,
VERSION BIGINT NOT NULL,
DATA VARCHAR(100) NOT NULL,
LAST_UPDATE_DATE DATETIME NOT NULL
)
COMMENT 'TEST_MSG';
以上为表结构的定义
结束
这样,启动应用,观察数据库表更新情况,会发现,数据的版本只会有增长的,不会存在降低的
那么,我们这实现了本文中开头提到的需求了.
并且也了解了在springboot中如何使用rabbitmq发送和消费消息了.
关于本文内容 , 欢迎大家的意见跟建议
代码仓库 (博客配套代码)
想获得最快更新,请关注公众号
 想获得最快更新,请关注公众号
想获得最快更新,请关注公众号








网友评论