前言
从这一章开始我们将要开始认识一个稍显枯燥但是非常重要的概念 - 数据库锁。由于针对不同的存储引擎的数据库锁的实现是不相同的,而现代大型项目基本都选择了 innoDB 作为存储引擎,所以本章节只探讨 innoDB 数据库锁的内容。
innoDB 的数据库锁与事务特性息息相关。所以在探讨开始之前,先来回顾一下 innoDB 的事务特性,会有助于理解后续的内容。
系列文章回顾
SQL 常用优化手段总结 - 分析 SQL 语句的一般步骤
SQL 常用优化手段总结 - 索引的应用
SQL 常用优化手段总结 - 索引的使用误区
SQL 常用优化手段总结 - 小技巧
SQL 常用优化手段总结 - 认识数据库锁
事务以及 ACID 属性
- 原子性
- 一致性
- 隔离性
- 持久性
得益于 innoDB 完整的事务特性支持,我们才能够在 mysql 上轻松的构建出各种各样健壮的业务系统。与此同时,事务也加大了处理成本,带来了并发问题。事务所带来的并发问题主要有以下这几点:
- 更新丢失:两个并行操作,后进行的操作覆盖掉了先进行操作的操作结果,被称作更新丢失。
- 脏读:一个事务在提交之前,在事务过程中修改的数据,被其他事务读取到了。
- 不可重复读:一个事务在提交之前,在事务过程中读取以前的数据却发现数据发生了改变。
- 幻读:一个事务按照相同的条件重新读取以前检索过的数据时,却发现了其他事务插入的新数据。
对于上面这几点,通用的解决思路是更新丢失通过应用程序完全避免。而其他的问题点则通过调整数据库事务隔离级别来解决。事务的隔离机制的实现手段之一就是利用锁。
排他锁与共享锁
MyIsam 实现了表锁。表锁可以针对数据库表加锁,在锁的灵活性上不如行锁。表锁分为两种锁:读锁与写锁。
innoDB 存储引擎实现了行锁与表锁(意向锁)。行锁可以以行为单位对数据集进行锁定。行锁也分为两种锁:分别是共享锁与排他锁。
- 共享锁:允许一个事务读取一行,阻止其他事务获得相同数据集的排他锁。但允许其他事务获取共享锁。
- 排他锁:允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享与排他锁。但是可以对获取了排他锁的数据集进行单纯的查询访问。
InnoDB 除了拥有有两种锁以外,还拥有两种不同的加锁方式。对于 Update、Delete、insert 语句,InnoDB 会自动给涉及的数据集隐式的加上排他锁。对于 select 语句 InnoDB 不会加任何锁。
而除了隐式的加锁手段以外,还可以通过显式的方式获取共享锁或者排他锁。
- 共享锁:
sql select * from table where ... lock in share mode - 排他锁:
sql select * from table where ... for update
仔细阅读上面的一段话。假设你足够细心,可能已经察觉到死锁的隐患了。多个线程持有某个数据集的共享锁,再尝试获取排他锁时会发生什么情况?
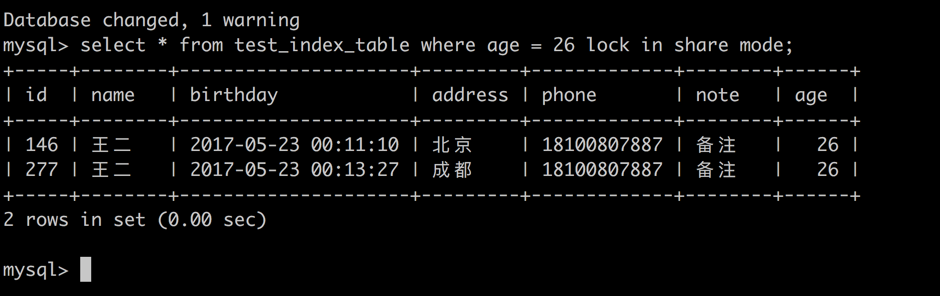
session 1 -> 针对 age = 26 的记录加共享锁
CREATE TABLE `test_index_table` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
`birthday` datetime DEFAULT NULL,
`address` varchar(45) DEFAULT NULL,
`phone` varchar(45) DEFAULT NULL,
`note` varchar(45) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `NAME_ADDRESS` (`name`,`address`) USING BTREE,
KEY `AGE` (`age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=283 DEFAULT CHARSET=utf8
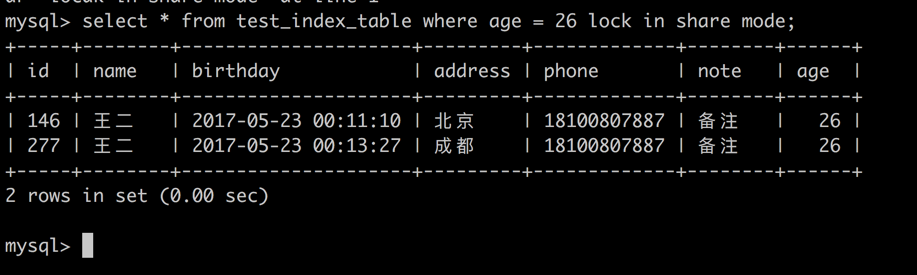
select * from test_index_table where age = 26 lock in share mode;
 image_1bjc51gaf1douqq81uqgg2h3fi2n.png-100.6kB
image_1bjc51gaf1douqq81uqgg2h3fi2n.png-100.6kB
session 2 -> 针对 age = 26 的记录加共享锁
 image_1bjc54stv177b1jg41i72171mo7534.png-95.3kB
image_1bjc54stv177b1jg41i72171mo7534.png-95.3kB
session 1 -> 针对 age = 26 的记录获取排他锁
由于当前数据集已经被 session 2 获取到了共享锁,无法再获取排他锁,操作阻塞。(道理很简单,文件被读取的时候不允许写入)
 image_1bjc56gu81pji1c1a1cuv1elmtgt3h.png-25.9kB
image_1bjc56gu81pji1c1a1cuv1elmtgt3h.png-25.9kB
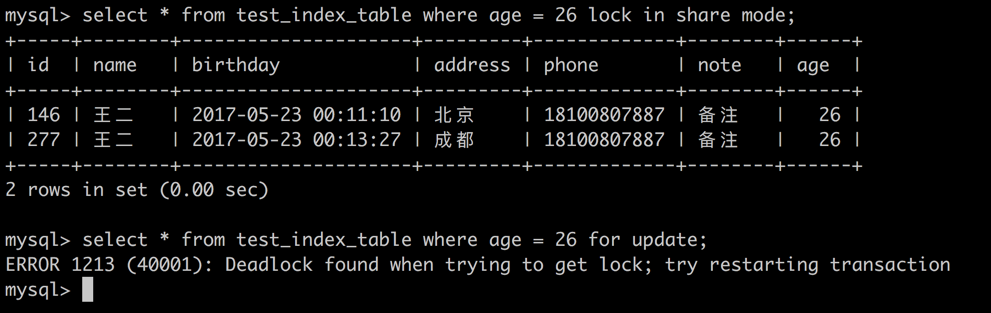
session 2 -> 针对 age = 26 的记录获取排他锁
由于当前数据集已经被 session 1 获取了共享锁,无法再获取排他锁,造成循环等待,数据库死锁操作退出。
 image_1bjc575bc1u001u2hormh858c33u.png-134.5kB
image_1bjc575bc1u001u2hormh858c33u.png-134.5kB
可见,两个 session 获得同一个数据集的共享锁,再分别尝试获取排他锁时会造成循环依赖,以至于引起数据库死锁报错,操作退出。
行锁与索引
光理解锁的基本概念是远远不够的。在 InnoDB 中,行锁是通过给索引上的索引项加锁来实现的。如果没有索引,InnoDB 将会通过隐藏的聚簇索引来对记录加锁。另外,根据针对 sql 语句检索条件的不同,加锁又有以下三种情形需要我们掌握。
- Record lock:对索引项加锁。
- Gap lock:对索引项之间的间隙加锁。
- Next-key lock:对记录记前面的间隙加锁。
Record lock:对索引项加锁。若没有索引项则使用表锁。
InnoDB 针对索引进行加锁的实现方式意味着:只有通过索引条件检索或者更新数据,InnoDB 才使用行级锁,否则 InnoDB 将会使用表锁更新数据,极大地降低数据库的并发执行性能。
session 1 -> 尝试对非索引件进行检索或者 update 获取排他锁。
现有一张拥有 NAME_ADDRESS 的复合索引与主键索引的数据表。请注意,AGE 索引已经被我删除了。
CREATE TABLE `test_index_table` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
`birthday` datetime DEFAULT NULL,
`address` varchar(45) DEFAULT NULL,
`phone` varchar(45) DEFAULT NULL,
`note` varchar(45) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `NAME_ADDRESS` (`name`,`address`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=283 DEFAULT CHARSET=utf8
 image_1bjc6kdko8ab31465117k510fc4b.png-150.2kB
image_1bjc6kdko8ab31465117k510fc4b.png-150.2kB
尝试对这张表进行非索引项的 Modify 语句。回想之前的概念:modify 语句会自动给当前数据集加上排他锁。
update test_schema.test_index_table set name = '王二' where age = 26
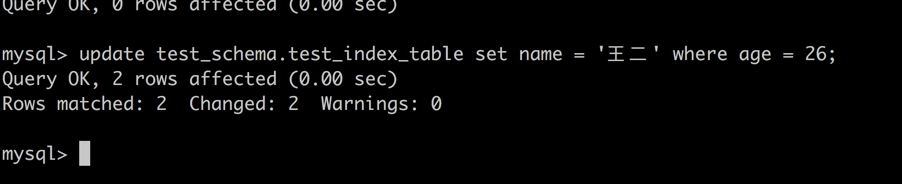 image_1bjc72brk1q6f8emjg01kts1fla4o.png-55.1kB
image_1bjc72brk1q6f8emjg01kts1fla4o.png-55.1kB
session2 -> 尝试对 age 为 27 的记录进行更新。
由于 age 字段为非索引字段,所以 session1 使用了表锁而非行锁来确保数据库并发访问的一致性。造成了 session 2 的更新操作阻塞。
 image_1bjc8m5pl140tb8tu0rk3g15so55.png-18kB
image_1bjc8m5pl140tb8tu0rk3g15so55.png-18kB
session1 -> 释放 session1 的表锁。
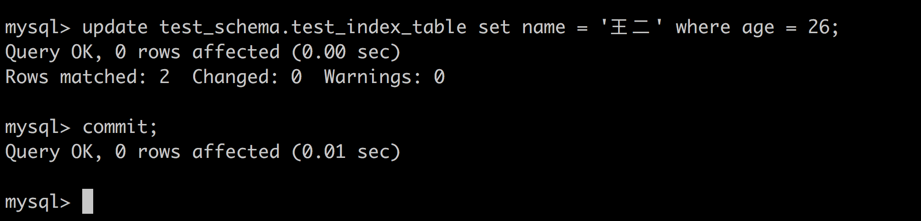 image_1bjc8p7431rf41ln915fu8i3ujr5i.png-61.7kB
image_1bjc8p7431rf41ln915fu8i3ujr5i.png-61.7kB
session2 -> 更新操作执行成功。
 image_1bjc8pv00vna1ud0r0nhns1j3i5v.png-40.6kB
image_1bjc8pv00vna1ud0r0nhns1j3i5v.png-40.6kB
针对索引加锁,而不是针对记录加锁。
刚才已经提到 innoDB 的行锁的实现方式是基于索引项的。这意味着即使你尝试获取不同行的排他锁,若使用了相同的索引键,也可能会造成锁冲突。
CREATE TABLE `test_index_table` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
`birthday` datetime DEFAULT NULL,
`address` varchar(45) DEFAULT NULL,
`phone` varchar(45) DEFAULT NULL,
`note` varchar(45) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `NAME_ADDRESS` (`name`,`address`) USING BTREE,
KEY `AGE` (`age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=283 DEFAULT CHARSET=utf8
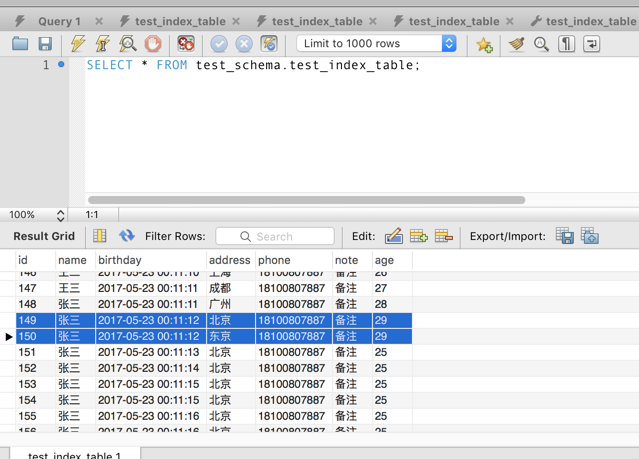 image_1bjcac76j1fen1ep2bq46lj1fip7j.png-146.1kB
image_1bjcac76j1fen1ep2bq46lj1fip7j.png-146.1kB
session1 -> 针对 age = 29 and address = 东京 获取排他锁。
通过观察表很容易得出本次我们期望获取排他锁的数据集应该是 id = 150 的记录。
 image_1bjcakqph1ma917icjmtv42pvr80.png-51.7kB
image_1bjcakqph1ma917icjmtv42pvr80.png-51.7kB
session1 -> 针对 age = 29 and address = 北京 获取排他锁。
尝试更新 id = 149 记录的操作竟然阻塞了。
 image_1bjcamhi417f8q44b19j2u1lnn8d.png-31.8kB
image_1bjcamhi417f8q44b19j2u1lnn8d.png-31.8kB
更新不同行的数据集,却产生了排他锁阻塞的原因其实很简单。由于 mysql 的行锁的实现方式基于索引,所以149与150对应到的索引项实际是同一个。所以 session2 在尝试获取排他锁时操作被 session1 阻塞。
next-key 锁
当利用范围条件而不是相等条件获取排他锁时,innoDB 会给符合条件的所有数据加锁。对于在条件范围内但是不存在的记录,叫做间隙。innoDB 也会对这个间隙进行加锁。另外,使用相等的检索条件时,若指定了本身不存在的记录作为检索条件的值的话,则此值对应的索引项也会加锁。
session 1 -> age >= 25 的索引项获取排他锁
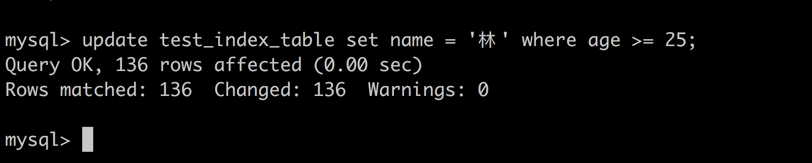 image_1bjcbkjc0hvp4j4km5stkj4a8q.png-44.8kB
image_1bjcbkjc0hvp4j4km5stkj4a8q.png-44.8kB
session 2 -> age = 39 的索引项获取排他锁
由于 session1 的操作产生了 next-key 锁的原因操作被阻塞
 image_1bjcbqhmr1di61iqk121ts151eee97.png-17.3kB
image_1bjcbqhmr1di61iqk121ts151eee97.png-17.3kB
session 1 -> 释放锁。
 image_1bjcbtjmh1k7s1kr61sqhcr31bv89k.png-15.3kB
image_1bjcbtjmh1k7s1kr61sqhcr31bv89k.png-15.3kB
session 2 -> 操作执行成功。同时给 age = 39 的索引项增加了 next-key 锁。
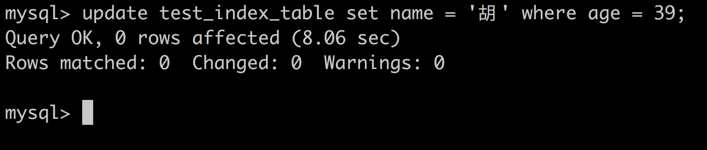 image_1bjcbud3c1ffnnuh11ghmt9vea1.png-41.7kB
image_1bjcbud3c1ffnnuh11ghmt9vea1.png-41.7kB
session 1 -> 尝试更新 age = 39 的索引项对应的记录。
由于上一步 session 2 的 next-key 锁的原因,本次操作被阻塞。
 image_1bjcc082u1nh1ur91bkl82mm9ae.png-16.9kB
image_1bjcc082u1nh1ur91bkl82mm9ae.png-16.9kB
可见,凡是会引起next-key 锁的操作都需要慎重考虑。稍不留意就会大幅度降低数据库的并发操作性能。也许你会觉得 next-key 锁的实现是不是欠妥。但是,mysql innoDB 实现 next-key 锁的一个重要原因就是为了防止事务的幻读。当存在 next-key 的情况下,执行中的事务无论外部插入多少数据也不会在事务提交之前读到新插入的数据集,从而保证了事务的一致性。
检查 InnoDB 行锁争用的情况
检查 InnoDB_row_lock 状态变量分析系统上的行锁竞争情况。
show status like "innodb_row_lock%"
如果锁竞争严重,innoDB_row_lock_waits 和 innoDB_row_lock_time_avg 的值比较高,则通过 information_schema 数据库中的表来查看锁情况。
select * from information_schema.innodb_locks
 image_1bjcd4j8t8vm1nh51ohn1g9c13chb8.png-60kB
image_1bjcd4j8t8vm1nh51ohn1g9c13chb8.png-60kB
后记
数据库优化手段章节的文章到此就告一段落了。开发 web 应用无论你使用什么语言,都离不开数据库的支撑。大型 web 应用的瓶颈最终往往都在 IO 处理上,所以工程师对数据库的理解实际上要比精通一门开发语言重要的多。
可惜的是,不少公司的技术人员,甚至于面试官对于成体系的数据库知识都还不够重视,在面试时常常对某些语言的【回字有几种写法的问题反复纠缠】。在我看来,一个优秀的工程师最重要的品质莫过于:写出维护性强,易读,可靠的程序,作成整齐简洁的文档。
最后,本系列的各项知识点对于开发人员来说非常重要。掌握了这些知识点,才算是基本入门关系型数据库,称得上一个合格的 web 后端工程师,写的出合格的应用程序。
参考书籍
《深入浅出 mysql》




网友评论