系列文章回顾
SQL 常用优化手段总结 - 分析 SQL 语句的一般步骤
SQL 常用优化手段总结 - 索引的应用
SQL 常用优化手段总结 - 索引的使用误区
SQL 常用优化手段总结 - 小技巧
SQL 常用优化手段总结 - 认识数据库锁
经过上一章艰苦卓绝的训练与尝试,我们成功分析出了有问题的 sql 语句。接下来该针对问题语句进行更进一步的优化了。索引往往在这个时候被引入来解决 sql 的运行效率的问题。
虽然索引的使用十分广泛,但是部分开发人员对索引的知识没有成体系的了解,造成了误用索引。误用索引不仅不能解决问题,还会进一步恶化性能。
好消息是,过阅读索引相关的章节的内容你将掌握以下几个知识点,从而建立起正确运用索引的基本知识。
- 索引是什么,都有哪些索引?
- 与索引相关的术语的基本概念。
- 哪些典型的场景能够使用索引?
- 哪些典型的场景无法使用索引?
索引是什么?都有哪些索引?
和书本能够利用目录快速定位到具体内容一样,索引也能够快速查询到数据库表中的具体内容。索引就是数据库的目录。
真正的索引是在 mysql 存储引擎中实现的。所以每种不同的存储引擎都对应了不同的索引类型。
常见的索引类型分为以下四种:
- B-tree 索引:最常见的索引类型
- Hash 索引:只有 Memory 引擎支持
- R-tree 索引(空间索引):MyIsam 存储引擎支持的一个特殊索引类型。主要用于地理空间数据类型。
- Full-text 索引:全文索引也是 MyIsam 的特殊索引类型。
B-tree 索引是一个结构类似二叉树的索引。本篇文章只介绍 B-tree 索引的运用,关于其他索引请自行查阅网络资料进行学习。
能够使用索引的典型场景
全值匹配
有如下一张测试表。主键为 id,无任何其他索引。
 image_1bg37jhm96kr1qgl1864cobor39.png-31.8kB
image_1bg37jhm96kr1qgl1864cobor39.png-31.8kB
指定索引中所有列的具体值。索引中的所有列,都有等值匹配的条件。
现在看看 explain 的返回值情况。
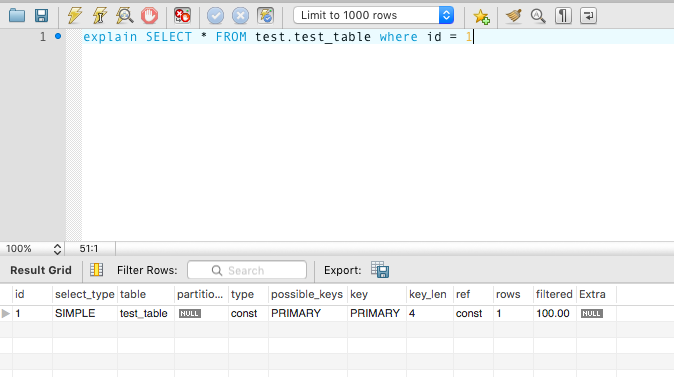
explain SELECT * FROM test.test_table where id = 1
 image_1bg3j72qh160nmvnta15um1n2434.png-40.7kB
image_1bg3j72qh160nmvnta15um1n2434.png-40.7kB
explain 输出结果中字段 type 的值为 const,表示为常量。即对索引中的列有等值的匹配条件。
字段 key 的值为 Primary。表示索引优化器选择了主键索引进行优化。
匹配值的范围查询
现在我们给 test_table 这张表增加两个索引,如下:
CREATE TABLE `test_table` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
`birthday` datetime DEFAULT NULL,
`address` varchar(45) DEFAULT NULL,
`phone` varchar(45) DEFAULT NULL,
`note` varchar(45) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `NAME` (`name`) USING BTREE,
KEY `AGE` (`age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=145 DEFAULT CHARSET=utf8
现在尝试对索引的值进行范围查找。
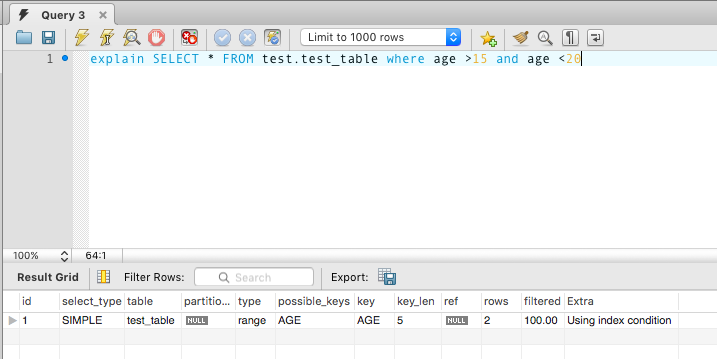
explain SELECT * FROM test.test_table where age >15 and age <20
 image_1bgoc670t130r1l2g11qp1e569nu9.png-46.8kB
image_1bgoc670t130r1l2g11qp1e569nu9.png-46.8kB
type 为 range,说明优化器选择范围查询。索引 key 为 AGE 代表选择了 AGE 索引来加速访。注意本例中的 Extra 字段。Using index condition 代表在利用索引查询后,还需要对索引回表查询数据。但是把数据过滤操作下方到了存储引擎,从而减少了 IO 处理。
匹配最左前缀
利用索引进行查询时,一定要遵循左前缀查询规则。
首先在表上建立一个复合索引如下:
CREATE TABLE `test_table` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
`birthday` datetime DEFAULT NULL,
`address` varchar(45) DEFAULT NULL,
`phone` varchar(45) DEFAULT NULL,
`note` varchar(45) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `NAME` (`name`) USING BTREE,
KEY `AGE` (`age`) USING BTREE,
KEY `LeftMostPreFix` (`name`,`address`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=145 DEFAULT CHARSET=utf8
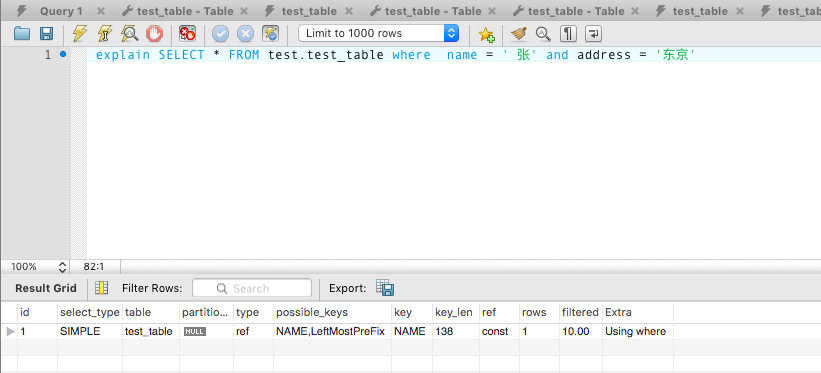
LeftMostPreFix 索引由 name、address 两列组成。在使用这个索引进行查询时,只有 name 、name and address 可以生效。
直接使用 address 或者 address 以及 name 进行查询时候,索引都无法生效。
explain SELECT * FROM test.test_table where name = ' 张' and address = '东京'
 image_1bg3g3bhb4ftec14kro8ns542a.png-50.8kB
image_1bg3g3bhb4ftec14kro8ns542a.png-50.8kB
但是,如果仅仅是使用 address 进行查询的话,则复合索引无法产生效果。
explain SELECT * FROM test.test_table where address = '东京'
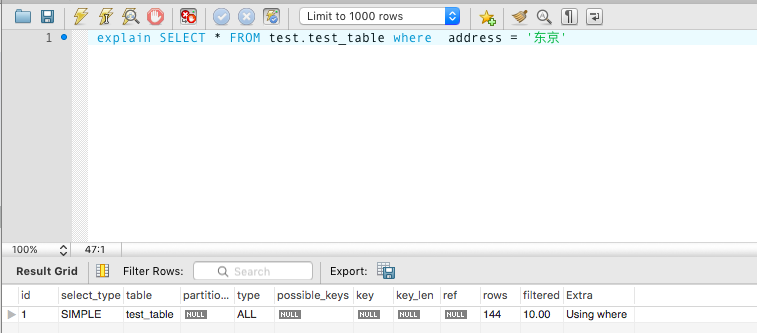 image_1bg3g4sv21oqh8be1bud1ptl114h9.png-41.9kB
image_1bg3g4sv21oqh8be1bud1ptl114h9.png-41.9kB
覆盖索引查询
当查询的所有列都处在索引字段中时,查询的效率会更高。
explain SELECT name FROM test.test_table where name = ' 林'
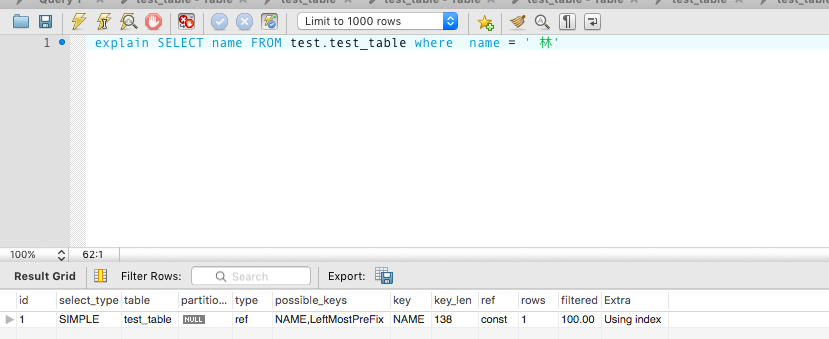 image_1bg3g8fg71pj3rck1j7p13cg1clhm.png-46.2kB
image_1bg3g8fg71pj3rck1j7p13cg1clhm.png-46.2kB
Extra 变成了 Using index。代表只需要访问索引就能得到全部数据,不需要通过索引获得地址后,再回表进行扫描。
左匹配列前缀
like 查询是一种常见的查询方式。和左前缀原则一样,进行 like 查询时也需要遵循左前缀匹配原则。
首先对表增加 address 列的索引。
CREATE TABLE `test_table` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
`birthday` datetime DEFAULT NULL,
`address` varchar(45) DEFAULT NULL,
`phone` varchar(45) DEFAULT NULL,
`note` varchar(45) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `NAME` (`name`) USING BTREE,
KEY `AGE` (`age`) USING BTREE,
KEY `LeftMostPreFix` (`name`,`address`) USING BTREE,
KEY `ADDRESS` (`address`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=145 DEFAULT CHARSET=utf8
接着尝试使用 like 检索数据。
explain SELECT * FROM test.test_table where address like '东%'
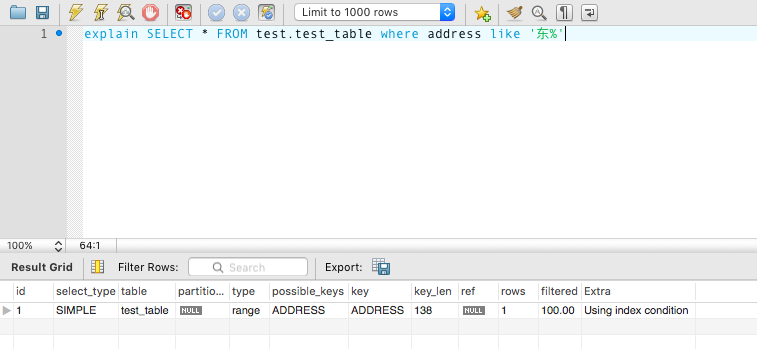 image_1bg3gpoh0126g1nbm1m64fsj1fmd1g.png-45.1kB
image_1bg3gpoh0126g1nbm1m64fsj1fmd1g.png-45.1kB
成功运用到索引 ADDRESS。查询类型为 range。
然后违背左前缀匹配原则,使用 Like 关键字再查询一次。
explain SELECT * FROM test.test_table where address like '%京'
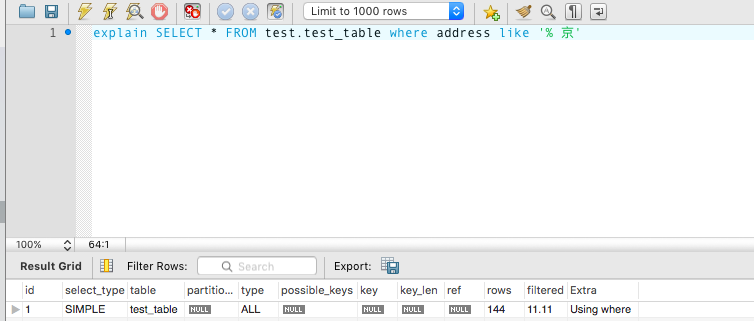 image_1bg3gr2rd4to4p01v9c74o7nn1t.png-41.9kB
image_1bg3gr2rd4to4p01v9c74o7nn1t.png-41.9kB
type 为 ALL、key 为 null 表示该次查询未使用索引,而是通过全表扫描进行了查询。全表扫描的性能在数据量较大时比较低下,应该尽量频繁进行全表扫描查询。
多条件匹配
使用 and 关键字查询是需求中常见的一种情况。
那么针对下面这样的索引结果,使用 and 关键字会带来怎样的查询效果呢?
CREATE TABLE `test_table` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
`birthday` datetime DEFAULT NULL,
`address` varchar(45) DEFAULT NULL,
`phone` varchar(45) DEFAULT NULL,
`note` varchar(45) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `NAME` (`name`) USING BTREE,
KEY `AGE` (`age`) USING BTREE,
KEY `LeftMostPreFix` (`name`,`address`) USING BTREE,
KEY `ADDRESS` (`address`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=145 DEFAULT CHARSET=utf8
尝试使用 name 与 age 的组合条件进行匹配与范围查询。
explain SELECT name FROM test.test_table where name = '张' and age < 20;
![image_1bg3i2mo0tslo88im17t51vfn2a.png-49.9kB][9]
表中含有索引 name 但没有 name 与 age 的复合索引。所以本次查询首先通过 NAME 索引定位到表地址,然后 using where 回表扫描根据 age < 20 过滤掉不符合条件的数据。由于 age < 20 条件的存在,即使语句只查询了 name 字段也必须回表扫描从而无法形成索引覆盖查询,对查询性能造成了影响。
总结
以上场景包含了精确匹配、模糊匹配、范围匹配、多条件匹配的查询语句,大部分业务用的查询都离不开这四种范畴。只要在使用索引时牢记住:
- 左前缀原则
- 尽量使用索引覆盖查询
- 索引常量的查询比范围索引查询效率更高
- 当查询涉及范围查询时,尽量将精确匹配的条件放在前面。
- 一张表中的索引只会被使用一次(or 条件语句除外)。mysql 会选择最优结果使用相应的索引。
便能享受索引所带来的性能提升。在下一章节,将会继续分享常见的索引误用场景。学会运用索引并且避免误用索引,是应对业务中常见的查询语句性能问题的关键所在。
参考书籍
《深入浅出 mysql》











网友评论