关于Android模块化我有一些话不知当讲不当讲
最近公司一个项目使用了模块化设计,本人参与其中的一个小模块开发,但是整体的设计并不是我架构设计的,开发半年有余,在此记录下来我的想法。
[TOC]
模块化场景
为什么需要模块化?
当一个App用户量增多,业务量增长以后,就会有很多开发工程师参与同一个项目,人员增加了,原先小团队的开发方式已经不合适了。
原先的一份代码,现在需要多个人来维护,每个人的代码质量也不相同,在进行代码Review的时候,也是比较困难的,同时也容易会产生代码冲突的问题。
同时随着业务的增多,代码变的越来越复杂,每个模块之间的代码耦合变得越来越严重,解耦问题急需解决,同时编译时间也会越来越长。
人员增多,每个业务的组件各自实现一套,导致同一个App的UI风格不一样,技术实现也不一样,团队技术无法得到沉淀。
架构演变
在刚刚开始的时候,项目架构使用的是MVP模式,这也是最近几年很流行的一个架构方式,下面是项目的原始设计。
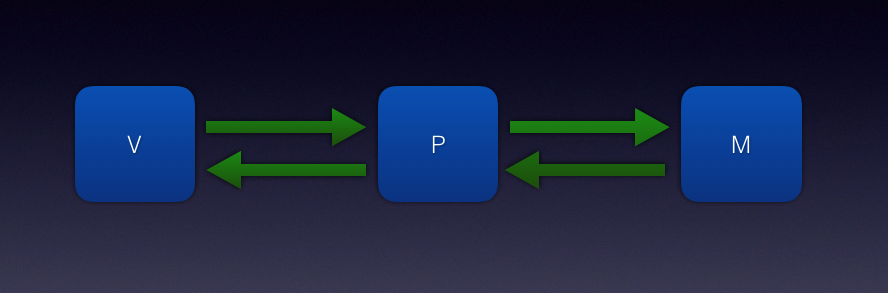 MVP
MVP
随着业务的增多,我们添加了Domain的概念,Domain从Data中获取数据,Data可能会是Net,File,Cache各种IO等,然后项目架构变成了这样。
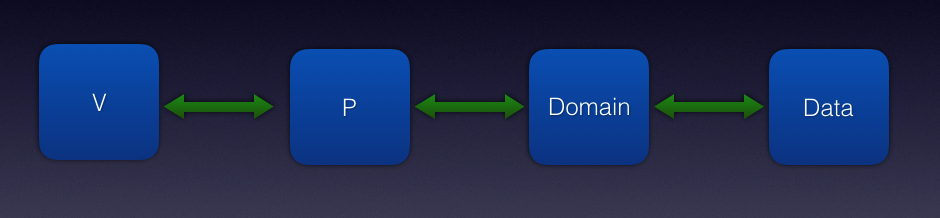 MVP2
MVP2
再然后随着人员增多,各种基础组件也变的越来越多,业务也很复杂,业务与业务之间还有很强的耦合,就变成了这样的。
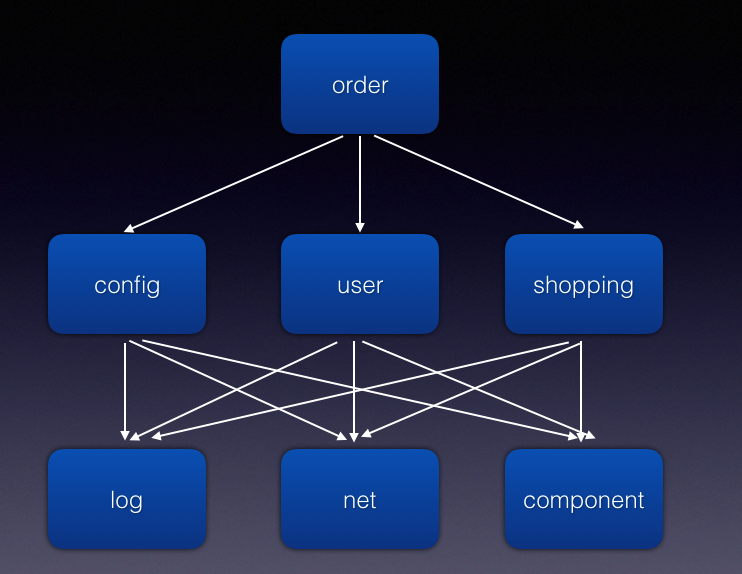
使用模块化技术以后,架构变成了这样。
 组件化架构
组件化架构
技术要点
这里简单介绍下Android项目实现模块化需要使用的技术以及技术难点。
Library module
在开始开始进行模块化之前,需要把各个业务单独抽取成Android Library Module,这个是Android Studio自带一个功能,可以把依赖较少的,作为基本组件的抽取成一个单独模块。
如图所示,我把各个模块单独分为一个独立的项目。
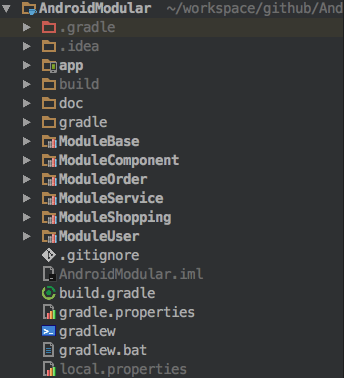 组件化架构
组件化架构
在主项目中使用gradle添加代码依赖。
// common
compile project(':ModuleBase')
compile project(':ModuleComponent')
compile project(':ModuleService')
// biz
compile project(':ModuleUser')
compile project(':ModuleOrder')
compile project(':ModuleShopping')
Library module开发问题
在把代码抽取到各个单独的Library Module中,会遇到各种问题。最常见的就是R文件问题,Android开发中,各个资源文件都是放在res目录中,在编译过程中,会生成R.java文件。R文件中包含有各个资源文件对应的id,这个id是静态常量,但是在Library Module中,这个id不是静态常量,那么在开发时候就要避开这样的问题。
举个常见的例子,同一个方法处理多个view的点击事件,有时候会使用switch(view.getId())这样的方式,然后用case R.id.btnLogin这样进行判断,这时候就会出现问题,因为id不是经常常量,那么这种方式就用不了。
同样开发时候,用的最多的一个第三方库就是ButterKnife,ButterKnife也是不可以用的,在使用ButterKnife的时候,需要用到注解配置一个id来找到对应view,或者绑定对应的各种事件处理,但是注解中的各个字段的赋值也是需要静态常量,那么就不能够使用ButterKnife了。
解决方案有下面几种:
1.重新一个Gradle插件,生成一个R2.java文件,这个文件中各个id都是静态常量,这样就可以正常使用了。
2.使用Android系统提供的最原始的方式,直接用findViewById以及setOnClickListener方式。
3.设置项目支持Databinding,然后使用Binding中的对象,但是会增加不少方法数,同时Databinding也会有编译问题和学习成本,但是这些也是小问题,个人觉的问题不大。
上面是主流的解决方法,个人推荐的使用优先级为 3 > 2 > 1。
当把个模块分开以后,每个人就可以单独分组对应的模块就行了,不过会有资源冲突问题,个人建议是对各个模块的资源名字添加前缀,比如user模块中的登录界面布局为activity_login.xml,那么可以写成这样us_activity_login.xml。这样就可以避免资源冲突问题。同时Gradle也提供的一个字段resourcePrefix,确保各个资源名字正确,具体用法可以参考官方文档。
依赖管理
当完成了Library module后,代码基本上已经很清晰了,跟我们上面的最终架构已经很相似了,有了最基本的骨架,但是还是没有完成,因为还是多个人操作同一个git仓库,各个开发小伙伴还是需要对同一个仓库进行各种fork和pr。
随着对代码的分割,但是主项目app的依赖变多了,如果修改了lib中的代码,那么编译时间是很恐怖的,大概统计了一下,原先在同一个模块的时候,编译时间大概需要2-3min,但是分开以后大概需要5-6min,这个是绝对无法忍受的。
上面的第一问题,可以这样解决,把各个子module分别使用单独的一个git仓库,这样每个人也只需要关注自己需要的git仓库即可,主仓库使用git submodule的方式,分别依赖各个子模块。
但是这样还是无法解决编译时间过长的问题,我们把各个模块也单独打包,每次子模块开发完成以后,发布到maven仓库中,然后在主项目中使用版本进行依赖。
举个例子,比如进行某一版本迭代,这个版本叫1.0.0,那么各个模块的版本也叫同样的版本,当版本完成测试发布后,对各个模块打对应版本的tag,然后就很清楚的了解各模块的代码分布。
gradle依赖如下。
// common
compile 'cn.mycommons:base:1.0.0'
compile 'cn.mycommons:component:1.0.0'
compile 'cn.mycommons:service:1.0.0'
// biz
compile 'cn.mycommons:user:1.0.0'
compile 'cn.mycommons:order:1.0.0'
compile 'cn.mycommons:shopping:1.0.0'
可能有人会问,既然各个模块已经分开开发,那么如果进行开发联调,别急,这个问题暂时保留,后面会对这个问题后面再表。
数据通信
当一个大项目拆成若干小项目时候,调用的姿势发生了少许改变。我这边总结了App各个模块之间的数据通信几种方式。
- 页面跳转,比如在订单页面下单时候,需要判断用户是否登录,如果没有则需要跳到登录界面。
- 主动获取数据,比如在下单时候,用户已经登录,下单需要传递用户的基本信息。
- 被动获得数据,比如在切换用户的时候,有时候需要更新数据,如订单页面,需要把原先用户的购物车数据给清空。
再来看下App的架构。
App架构
第一个问题,原先的方式,直接指定某个页面的ActivityClass,然后通过intent跳转即可,但是在新的架构中,由于shopping模块不直接依赖user,那么则不能使用原始的进行跳转,我们解决方式使用Router路由跳转。
第二个问题,原先的方式有个专门的业务单利,比如UserManager,直接可以调用即可,同样由于依赖发生了改变,不能够进行调用。解决方案是所有的需要的操作,定义成接口放在Service中。
第三个问题,原先的方式,可以针对事件变化提供回调接口,当我需要监听某个事件时候,设置回调即可。
页面路由跳转
如上分析,原先方式代码如下。
Intent intent = new Intent(this, UserActivity.class);
startActivity(intent);
但是使用Router后,调用方式改变了。
RouterHelper.dispatch(getContext(), "app://user");
具体的原理是什么,很简单的,做一个简单的映射匹配即可,把"app://user"与UserActivity.class配对,具体的就是定义一个Map,key是对应的Router字符,value是Activity的class。在跳转时候从map中获取对应的ActivityClass,然后在使用原始的方式。
可能有人的会问,要向另外一个页面传递参数怎么办,没事我们可以在router后面直接添加参数,如果是一个复杂的对象那么可以把对象序列化成json字符串,然后再从对应的页面通过反序列化的方式,得到对应的对象。
例如:
RouterHelper.dispatch(getContext(), "app://user?id=123&obj={"name":"admin"}");
注: 上面的router中json字符串是需要url编码的,不然会有问题的,这里只是做个示例。
除了使用Router进行跳转外,我想了一下,可以参考Retrofit方式,直接定义跳转Java接口,如果需要传递额外参数,则以函数参数的方式定义。
这个Java接口是没有实现类的,可以使用动态代理方式,然后接下来的方式,和使用Router的方式一样。
那么这总两种方式有什么优缺点呢。
Router方式:
- 有点:不需要高难度的技术点,使用方便,直接使用字符串定义跳转,可以好的往后兼容
- 缺点:因为使用的是字符串配置,如果字符输入字符,则很难发现bug,同时也很难知道某个参数对应的含义
仿Retrofit方式:
- 因为是Java接口定义,所以可以很简单找到对应的跳转方法,参数定义也很明确,可以直接写在接口定义处,方便查阅。
- 同样因为是Java接口定义,那么如果需要扩展参数,只能重新定义新方法,这样会出现多个方法重载,如果在原先接口上修改,对应的原先调用方也要做响应的修改,比较麻烦。
上面是两种实现方式,如果有相应同学要实现模块化,可以根据实际情况做出选择。
Interface和Implement
如上分析,如果需要从某个业务中获取数据,我们分别需要定义接口以及实现类,然在获取的时候在通过反射来实例化对象。
下面是简单的代码示例
接口定义
public interface IUserService {
String getUserName();
}
实现类
class UserServiceImpl implements IUserService {
@Override
public String getUserName() {
return "UserServiceImpl.getUserName";
}
}
反射生成对象
public class InjectHelper {
@NonNull
public static AppContext getAppContext() {
return AppContext.getAppContext();
}
@NonNull
public static IModuleConfig getIModuleConfig() {
return getAppContext().getModuleConfig();
}
@Nullable
public static <T> T getInstance(Class<T> tClass) {
IModuleConfig config = getIModuleConfig();
Class<? extends T> implementClass = config.getServiceImplementClass(tClass);
if (implementClass != null) {
try {
return implementClass.newInstance();
} catch (Exception e) {
e.printStackTrace();
}
}
return null;
}
}
实际调用
IUserService userService = InjectHelper.getInstance(IUserService.class);
if (userService != null) {
Toast.makeText(getContext(), userService.getUserName(), Toast.LENGTH_SHORT).show();
}
本示例中每次调用都是用反射生成新的对象,实际应用中可能与IoC工具结合使用,比如Dagger2.
EventBus
针对上面的第三个问题,原先设计的使用方式也是可以的,只需要把回调接口定义到对应的service接口中,然后调用方就可以使用。
但是我建议可以使用另外一个方式——EventBus,EventBus也是利用观察者模式,对事件进行监听,是设置回调更优雅方式的实现。
优点:不需要定义很多个回调接口,只需要定义事件Class,然后通过Claas的唯一性来进行事件匹配。
缺点:需要定义很多额外的类来表示事件,同时也需要关注EventBus的生命周期,在不需要使用事件时候,需要注销事件绑定,不然容易发生内存泄漏。
映射匹配
上面的介绍的各个模块之间通信,都运涉及到映射匹配问题,在此我总结了一下,主要涉及到一下三种方式。
Map register
Map register是这样的,全局定义一个Map,各个模块在初始化的时候,分别在初始化的时候注册映射关系。
下面是简单的代码示例,比如我们定义一个模块生命周期,用于初始化各个模块。
public interface IModuleLifeCycle {
void onCreate(IModuleConfig config);
void onTerminate();
}
User模块初始化
public class UserModuleLifeCycle extends SimpleModuleLifeCycle {
public UserModuleLifeCycle(@NonNull Application application) {
super(application);
}
@Override
public void onCreate(@NonNull IModuleConfig config) {
config.registerService(IUserService.class, UserServiceImpl.class);
config.registerRouter("app://user", UserActivity.class);
}
}
在Application中完成初始化
public class AppContext extends Application {
private ModuleLifeCycleManager lifeCycleManager;
@Override
public void onCreate() {
super.onCreate();
lifeCycleManager = new ModuleLifeCycleManager(this);
lifeCycleManager.onCreate();
}
@Override
public void onTerminate() {
super.onTerminate();
lifeCycleManager.onTerminate();
}
@NonNull
public IModuleConfig getModuleConfig() {
return lifeCycleManager.getModuleConfig();
}
}
public class ModuleLifeCycleManager {
@NonNull
private ModuleConfig moduleConfig;
@NonNull
private final List<IModuleLifeCycle> moduleLifeCycleList;
ModuleLifeCycleManager(@NonNull Application application) {
moduleConfig = new ModuleConfig();
moduleLifeCycleList = new ArrayList<>();
moduleLifeCycleList.add(new UserModuleLifeCycle(application));
moduleLifeCycleList.add(new OrderModuleLifeCycle(application));
moduleLifeCycleList.add(new ShoppingModuleLifeCycle(application));
}
void onCreate() {
for (IModuleLifeCycle lifeCycle : moduleLifeCycleList) {
lifeCycle.onCreate(moduleConfig);
}
}
void onTerminate() {
for (IModuleLifeCycle lifeCycle : moduleLifeCycleList) {
lifeCycle.onTerminate();
}
}
@NonNull
IModuleConfig getModuleConfig() {
return moduleConfig;
}
}
APT
使用注解的方式配置映射信息,然后生成一个类似Database一样的文件,然后Database文件中包含一个Map字段,Map中记录各个映射信息。
首先需要定义个Annotation。
如:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.CLASS)
public @interface Implements {
Class parent();
}
需要实现一个 Annotation Process Tool,来解析自己定义的Annotation。
代码略,此代码有点复杂,暂时不贴了。
编译产生的文件,大概如下所示。
public class Implement_$$_Database {
@NonNull
private final Map<Class<?>, Class<?>> serviceConfig;
public Implement_$$_Database() {
serviceConfig = new HashMap<>();
serviceConfig.put(IUserService.class, UserServiceImpl.class);
}
public <T> Class<? extends T> getServiceImplementClass(Class<T> serviceClass) {
return (Class<? extends T>) serviceConfig.get(serviceClass);
}
}
然后利用反射找到Implement_$$_Database这个类,然后从方法中找到配对。
public class InjectHelper {
@Nullable
public static <T> T getInstanceByDatabase(Class<T> tClass) {
Implement_$$_Database database = new Implement_$$_Database();
Class<? extends T> implementClass = database.getServiceImplementClass(tClass);
if (implementClass != null) {
try {
return implementClass.newInstance();
} catch (Exception e) {
e.printStackTrace();
}
}
return null;
}
}
然后在需要配置的地方添加注解即可。
@Implements(parent = IUserService.class)
class UserServiceImpl implements IUserService {
@Override
public String getUserName() {
return "UserServiceImpl.getUserName";
}
}
调用姿势。
binding.button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
IUserService userService = InjectHelper.getInstanceByDatabase(IUserService.class);
if (userService != null) {
Toast.makeText(getContext(), userService.getUserName(), Toast.LENGTH_SHORT).show();
}
}
});
注意点:
有时候,在生成最终的配置文件的时候,文件的名字是固定的,比如上面的Implement_$$_Database,最终的路径是这样的cn.mycommons.implements.database.Implement_$$_Database.java,然后通过编译到apk中或则是aar中。
但是有个问题,如果各个子模块都使用了这样的插件,那么每个子模块的就会有这个Implement_$$_Database.class,那么就会编译出错。
因为aar中包含的时候class文件,不是java文件,不能在使用APT做处理了。下面有2中解决方案。
-
子工程的插件生成的文件包含一定的规则,比如包含模块名字,如
User_Implement_$$_Database.java,同时修改编译过程,把java文件也打包到aar中,主工程的插件在编译时候,提取aar中的文件,然后合并子工程的所有的代码,这个思路是可行的,不过技术实现起来比较麻烦。 -
同一的方式类似,也是生成有一定规则的的文件,或者在特地package下生成class,这些class再通过接下来的所讲的Gradle Transform方式,生成一个新的Database.class文件。
Gradle Transform
这是Android Gradle编译提供的一个接口,可以供开发自定义一些功能,而我们就可以根据这个功能生成映射匹配,这种方式和APT类似,APT是运行在代码编译时期,而且Transform是直接扫描class,然后再生成新的class,class中包含Map映射信息。修改class文件,使用的是javassist一个第三方库。
下面简单讲述代码实现,后面有机会单独写一篇文章讲解。
首先定义一个注解,这个注解用于标注一个实现类的接口。
package cn.mycommons.modulebase.annotations;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.CLASS)
public @interface Implements {
Class parent();
}
一个测试用的接口以及实现类。
public interface ITest {
}
@Implements(parent = ITest.class)
public class TestImpl implements ITest {
}
定义一个静态方法,用于获取某个接口的实现类。
package cn.mycommons.modulebase.annotations;
public class ImplementsManager {
private static final Map<Class, Class> CONFIG = new HashMap<>();
public static Class getImplementsClass(Class parent) {
return CONFIG.get(parent);
}
}
如果不使用任何黑科技,直接使用Java技术,那么在定义时候需要主动的往CONFIG这个map中添加配置,但是这里我们利用transform,直接动态的添加。
定义一个ImplementsPlugin gradle插件。
public class ImplementsPlugin implements Plugin<Project> {
@Override
public void apply(Project project) {
AppExtension app = project.getExtensions().getByType(AppExtension.class);
app.registerTransform(new ImplementsTransform(project));
}
}
自定义的Transform实现。
public class ImplementsTransform extends Transform {
static final String IMPLEMENTS_MANAGER = "cn/mycommons/modulebase/annotations/ImplementsManager.class"
static final String IMPLEMENTS_MANAGER_NAME = "cn.mycommons.modulebase.annotations.ImplementsManager"
Project project
ImplementsTransform(Project project) {
this.project = project
}
void log(String msg, Object... args) {
String text = String.format(msg, args)
project.getLogger().error("[ImplementsPlugin]:${text}")
}
@Override
public String getName() {
return "ImplementsTransform"
}
@Override
public Set<QualifiedContent.ContentType> getInputTypes() {
return ImmutableSet.of(QualifiedContent.DefaultContentType.CLASSES)
}
@Override
public Set<? super QualifiedContent.Scope> getScopes() {
return ImmutableSet.of(
QualifiedContent.Scope.PROJECT,
QualifiedContent.Scope.PROJECT_LOCAL_DEPS,
QualifiedContent.Scope.SUB_PROJECTS,
QualifiedContent.Scope.SUB_PROJECTS_LOCAL_DEPS,
QualifiedContent.Scope.EXTERNAL_LIBRARIES
)
}
@Override
boolean isIncremental() {
return false
}
@Override
void transform(TransformInvocation transformInvocation)
throws TransformException, InterruptedException, IOException {
super.transform(transformInvocation)
long time1 = System.currentTimeMillis();
log(this.toString() + ".....transform")
TransformOutputProvider outputProvider = transformInvocation.outputProvider
outputProvider.deleteAll()
def classPool = new ClassPool()
classPool.appendSystemPath()
// 记录所有的符合扫描条件的记录
List<Entry> implementsList = []
// ImplementsManager 注解所在的jar文件
JarInput implementsManagerJar = null
// 扫描所有的文件
transformInvocation.inputs.each {
it.directoryInputs.each {
classPool.appendClassPath(it.file.absolutePath)
def dst = outputProvider.getContentLocation(it.name, it.contentTypes, it.scopes, Format.DIRECTORY)
FileUtils.copyDirectory(it.file, dst)
project.fileTree(dst).each {
String clazzPath = it.absolutePath.replace(dst.absolutePath, "")
clazzPath = clazzPath.replace("/", ".").substring(1)
if (clazzPath.endsWith(".class")) {
clazzPath = clazzPath.substring(0, clazzPath.size() - 6)
CtClass clazz = classPool.get(clazzPath)
// 如果class中的类包含注解则先收集起来
Implements annotation = clazz.getAnnotation(Implements.class)
if (annotation != null) {
implementsList.add(new Entry(annotation, clazz))
}
}
}
}
it.jarInputs.each {
classPool.appendClassPath(it.file.absolutePath)
if (implementsManagerJar == null && isImplementsManager(it.file)) {
implementsManagerJar = it
} else {
def dst = outputProvider.getContentLocation(it.name, it.contentTypes, it.scopes, Format.JAR)
FileUtils.copyFile(it.file, dst)
def jarFile = new JarFile(it.file)
def entries = jarFile.entries()
// 如果jar中的class中的类包含注解则先收集起来
while (entries.hasMoreElements()) {
def jarEntry = entries.nextElement()
String clazzPath = jarEntry.getName()
clazzPath = clazzPath.replace("/", ".")
if (clazzPath.endsWith(".class")) {
clazzPath = clazzPath.substring(0, clazzPath.size() - 6)
def clazz = classPool.get(clazzPath)
Implements annotation = clazz.getAnnotation(Implements.class)
if (annotation != null) {
implementsList.add(new Entry(annotation, clazz))
}
}
}
}
}
}
log("implementsManagerJar = " + implementsManagerJar)
Map<String, String> config = new LinkedHashMap<>()
implementsList.each {
def str = it.anImplements.toString();
log("anImplements =" + it.anImplements)
def parent = str.substring(str.indexOf("(") + 1, str.indexOf(")")).replace("parent=", "").replace(".class", "")
log("parent =" + parent)
log("sub =" + it.ctClass.name)
// 收集所有的接口以及实现类的路径
config.put(parent, it.ctClass.name)
}
log("config = " + config)
long time2 = System.currentTimeMillis();
if (implementsManagerJar != null) {
def implementsManagerCtClass = classPool.get(IMPLEMENTS_MANAGER_NAME)
log("implementsManagerCtClass = " + implementsManagerCtClass)
// 修改class,在class中插入静态代码块,做初始化
def body = "{\n"
body += "CONFIG = new java.util.HashMap();\n"
for (Map.Entry<String, String> entry : config.entrySet()) {
body += "CONFIG.put(${entry.key}.class, ${entry.value}.class);\n"
}
body += "}\n"
log("body = " + body)
implementsManagerCtClass.makeClassInitializer().body = body
def jar = implementsManagerJar
def dst = outputProvider.getContentLocation(jar.name, jar.contentTypes, jar.scopes, Format.JAR)
println dst.absolutePath
// 修改完成后,完成后再写入到jar文件中
rewriteJar(implementsManagerJar.file, dst, IMPLEMENTS_MANAGER, implementsManagerCtClass.toBytecode())
}
log("time = " + (time2 - time1) / 1000)
}
static boolean isImplementsManager(File file) {
return new JarFile(file).getEntry(IMPLEMENTS_MANAGER) != null
}
static void rewriteJar(File src, File dst, String name, byte[] bytes) {
dst.getParentFile().mkdirs()
def jarOutput = new JarOutputStream(new FileOutputStream(dst))
def rcJarFile = new JarFile(src)
jarOutput.putNextEntry(new JarEntry(name))
jarOutput.write(bytes)
def buffer = new byte[1024]
int bytesRead
def entries = rcJarFile.entries()
while (entries.hasMoreElements()) {
def entry = entries.nextElement()
if (entry.name == name) continue
jarOutput.putNextEntry(entry)
def jarInput = rcJarFile.getInputStream(entry)
while ((bytesRead = jarInput.read(buffer)) != -1) {
jarOutput.write(buffer, 0, bytesRead)
}
jarInput.close()
}
jarOutput.close()
}
}
具体代码可以参考这里
映射匹配总结
优点:
- Map:简单明了,很容易入手,不会对编译时间产生任何影响,不会随着Gradle版本的升级而受影响,代码混淆时候不会有影响,无需配置混淆文件。
- APT:使用简单,使用注解配置,代码优雅,原理是用代码生成的方式生成新的文件。
- Transform:使用简单,使用注解配置,代码优雅,原理是用代码生成的方式生成新的文件,不过生成的文件的时期和APT不同,会编译时间产生少许影响。
缺点:
- Map:在需要新添加映射的时候,需要手动添加,不然不会生效,代码不优雅。
- APT:在编译时期生成文件,会编译时间产生少许影响,同时在不同的Gradle的版本中可能会产生错误或者兼容问题。需要配置混淆设置,不然会丢失文件。技术实现复杂,较难维护。
- Transform:在编译时期生成文件,会编译时间产生少许影响,同时在不同的Gradle的版本中可能会产生错误或者兼容问题。需要配置混淆设置,不然会丢失文件。技术实现复杂,较难维护。
从技术复杂性以及维护性来看,Map > APT = Transform
从使用复杂性以及代码优雅性来看,Transform > APT > Map
开发调试技巧
Debug
上面介绍了很多关于模块化的概念以及技术难题,当模块化完成以后,再进行完成开发时候还是会遇到不少问题。不如原先代码在一起的时候很方便的进行代码调试。但是进行模块化以后,直接使用的是aar依赖,不能直接修改代码,可以使用下面技巧,可以直接进行代码调试。
在根目录下面创建一个module目录以及module.gradle文件,这个目录和文件是git ignore的,然后把对应的模块代码clone到里面,根目录的setting.gradlew apply module.gradle文件,如下所示,如果需要源码调试,则在module中添加对应的模块。然后在app的依赖中去掉aar依赖,同时添加项目依赖即可。当不需要源码调试好,再修改为到原先代码即可。
try {
apply from: "./module.gradle"
} catch (e) {
}
module.gradle
include ':ModuleShopping'
比如调试shopping模块
// common
compile 'cn.mycommons:base:1.0.0'
compile 'cn.mycommons:component:1.0.0'
compile 'cn.mycommons:service:1.0.0'
// biz
compile 'cn.mycommons:user:1.0.0'
compile 'cn.mycommons:order:1.0.0'
// compile 'cn.mycommons:shopping:1.0.0'
compile project(':ModuleShopping')
当然还有个更具技术挑战性方案,使用gradle插件的形式,如果发现root项目中包含的模块化的源码,则不适用aar依赖,直接使用源码依赖,当然这个想法是不错的,不过具有技术挑战性,同时有可能随着Gradle版本的升级,编写的gradle插件也要做相对于的兼容风险,这是只是简单提示一下。
容器设计
上面讲到的如果要调试代码时候,需要完整的运行的整个项目,随着项目的增大,编译时间可能变得很长。
我们可以做一个简单的,类似与主app模块一样,比如我是负责user模块的开发者,那么我只要调试我这个模块就行了,如果需要其他的模块,我可以简单的做一个mock,不是把其他的模块直接依赖过来,这样可以做到调试作用。等到再需要完整项目调试时候,我们在使用上面介绍的方式,这样可以节省不少开发时间。
还有一种实现调试的方式,比如上面的user模块,目录下面的build.gradle文件是这样的
apply plugin: 'com.android.library'
xxx
xxx
我们可以在gradle.properties中设置编译变参数isLibModule,当需要完整调试好,设置为isLibModule=false,这样我这个子模块就是一个apply plugin: 'com.android.application'这样的模块,是可以单独运行的一个项目
try {
if (isLibModule) {
apply from: "./build_lib.gradle"
}else{
apply from: "./build_app.gradle"
}
} catch (e) {
}
可能有时候还是需要单独的运行环境,android编译方式有2中,一种是debug,一种是release。当打包成aar的时候,使用的是release方式,我们可以把需要调试的代码全部放到debug中,这样打包的时候就不会把调试的文件发布到aar中。不过这种实现方式,需要对Android项目的目录有较高的认识,才可以熟练使用。
CI
上面介绍的各个模块需要单独到独立的git仓库,同时打包到单独的maven仓库,当开发完成后,这时候就需要进行打包,但这个是一个简单和重复的事情,所以我们需要一个工具来完成这些事情,我们可以利用CI系统来搞定这件事情,这里我推荐Jenkins,主流厂商使用jenkins作为CI服务器这个方案。
具体的步骤就是,需要对每个模块的git仓库做web hook,我们公司使用的是git lab,可以对git的各种操作做hook,比如push,merge,tag等。
当代码发送了变化了,我们可以发送事件到CI服务器,CI服务器再对各个事件做处理,比如user模块develop分支有代码变化,这个变化可能是merge,也有可能是push。我们可以把主项目代码和user项目的代码单独clone下拉,然后编译一下,确认是否有编译问题,如果有编译通过,那么在使用相关gradle命令发布到maven仓库中。
不管每次编译结果怎样,是成功还是失败,我们都应该把结果回馈给开发者,常见的方式是邮件,不过这个信息邮件方式可能很频繁,我们建议使用slack。
总结
模块化架构主要思路就是分而治之,把依赖整理清楚,减少代码冗余和耦合,在把代码抽取到各自的模块后,了解各个模块的通信方式,以及可能发生的问题,规避问题或者解决问题。最后为了开发和调试方便,开发一些周边工具,帮助开发更好的完成任务。













网友评论