认识几种编码方式
ASCII
计算机发明之后需要使用0和1来表示字符,于是美国人在50年代发明了 ASCII (美国标准信息交换代码,American Standard Code for Information Interchange) 码。它由128个字符组成,包括大小写字母、数字0-9、标点符号、非打印字符(换行符、制表符等4个)以及控制字符(退格、响铃等)组成,每个字符占7位(1字节是8位)。比如 'a'的 ASCII码10进制是97,二进制是 01100001。
ISOLatin-1
可以认为ASCII是美国发明针对英语设计的,但欧洲人在用的时候出现了问题。对于一些特殊的拉丁字符,比如法文德文里某些字符,ASCII字符集就不包括。于是欧洲人发明了一种8位字符集是ISO 8859-1Latin 1,也简称为ISOLatin-1。它对ASCII做了个扩充,对于0-127之间的字符还使用ASCII里的字符不变, 把位于128-255之间的字符表示拉丁字母表中特殊语言字符。
UNICODE
后来计算机不断发展扩展到亚洲非洲,如何用计算机使用的二进制表示这些语言又成了问题。ISOLatin-1的8位字符集只能表示256个字符,而仅汉语就有80000以上个字符。如何把地球上绝大多数语言用一种编码方式表示出来呢? 于是发明了UNICODE编码,只用2个字节(16位)就可以编码地球上几乎所有地区的文字。
但是,UNICODE只是理论上的编码方式,相当于给世界上每个文字打了个编号,但这编号具体如何在计算机里面存储,可以有多种实现方式。比如utf-8和gbk。
前面说了UNICODE只是给每个文字打了个编号,为啥不把这个编号直接转化成二进制存储在计算机里面呢? 比如英文字母s的编号是115, 用二进制表示是00000000 1110011, 中文日的编号是26085 (16进制是65e5) ,二进制是11001011 1100101。老外才没那么傻,对于老外这种日常纯粹是用英文字符的人来说明明之前1个字节就能存储一个字母,现在为了全球大一统非要存储为2个字节,相当于一个之前一个1M的文档,现在变为2M。于是老外耍了赖,英文字母s是115没错,但我就用1个字节1110011表示,而你中文日是26085号也没错,但是你不能在使用2个表示,而是用2个甚至6个字节表示。(为了英文的特权,牺牲其他语言的存储空间的便利),这个编码方式就是UTF-8。
** UTF-8 **
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。UTF-8用1到6个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
那GBK又是如何产生的呢?
GBK
这时候中国人不干了,为啥你制定了全球大一统的规则,却为了自己的便利又破坏规则,连这点小便宜都不放过(典型的美国人作风)? 明明用2个字节就能表示中文一个汉字,现在UTF-8编码中文竟然需要2个甚至4个字节来表示。于是中国制定一套自己的规则,于是用2个字节来表示一个汉字,总共可以覆盖2万多个文字。 对于英文,好吧让一步,还保留和你UTF-8同样的方式使用一个字节来表示。
下图是把当前文章分别保存为 gbk 何 utf-8两种编码格式下文件大小的对比,表明用 gbk 确实省空间
 记住:UNICODE只是给字符一个代号,而GBK和UTF-8使用不同的规则来表示同一个代号。
记住:UNICODE只是给字符一个代号,而GBK和UTF-8使用不同的规则来表示同一个代号。网页乱码如何产生的呢?
下面这个流程是我们写入文件到展示文件的简单描述:
我们使用编辑器编写 HTML 文件
保存编写的HTML文件
使用浏览器打开HTML文件
HTML文件在浏览器展示
乱码产生的根源就在与第2步骤和第4步。
在第2步保持文件时会把我们写入的文字使用编辑器默认的编码方式进行保存。如果大家使用的是vscode编辑器,默认的编码方式是utf-8。
 在第4步浏览器打开网页时,它并不知道你的这个文件是使用什么编码方式,于是自作主张使用了默认解码方式。如下图所示,文件保存为GBK格式,在Chrome打开时默认使用 ISO -8859的解码方式,导致编码和解码不匹配,产生乱码。
在第4步浏览器打开网页时,它并不知道你的这个文件是使用什么编码方式,于是自作主张使用了默认解码方式。如下图所示,文件保存为GBK格式,在Chrome打开时默认使用 ISO -8859的解码方式,导致编码和解码不匹配,产生乱码。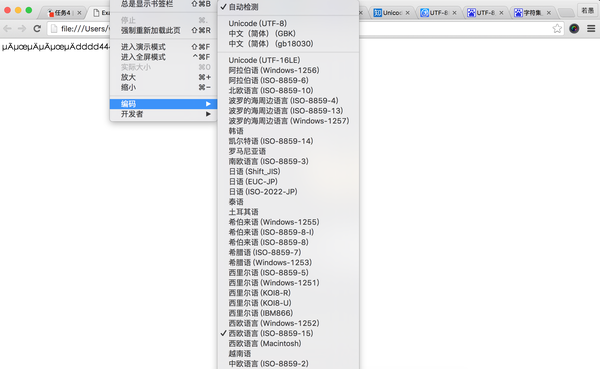 那如何规避这个问题呢?即如何通知浏览器用什么方式解码呢?
那如何规避这个问题呢?即如何通知浏览器用什么方式解码呢?首页,在文件保存的时候你自己要清楚是用哪种编码方式保存的。如果你的文件是保存为utf-8格式,那么一定要在html 的
<head>里添加<meta charset="utf-8">,这句话的意思是告诉浏览器在打开这个页面的时候不要去猜了,直接用utf-8去解码。 同理,如果你的文件保存为gbk格式,一定在文件里添加<meta charset="gbk">。总结:
- 乱码产生的根本原因是你保存的编码格式和浏览器解析时的解码格式不匹配导致的。
- 乱码一般是英文以外的字符才会出现。
为啥纯粹的英文不会出现乱码问题,即使编码方式和解码方式不一致?那是因为前面讲过了 utf-8、gbk对英文都是采用1个字节的编码方式,并且使用了相同的码
字。










网友评论