本文转自五月的仓颉 https://www.cnblogs.com/xrq730
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
本文是微信公众号【Java技术江湖】的《Spring和SpringMVC源码分析》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从spring基础入手,一步步地学习spring基础和springmvc的框架知识,并上手进行项目实战,spring框架是每一个Java工程师必须要学习和理解的知识点,进一步来说,你还需要掌握spring甚至是springmvc的源码以及实现原理,才能更完整地了解整个spring技术体系,形成自己的知识框架。
后续还会有springboot和springcloud的技术专题,陆续为大家带来,敬请期待。
为了更好地总结和检验你的学习成果,本系列文章也会提供部分知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
前言
xml的读取应该是Spring的重要功能,因为Spring的大部分功能都是以配置做为切入点的。
我们在静态代码块中读取配置文件可以这样做:
//这样来加载配置文件
XmlBeanFactory factory = new XmlBeanFactory(new ClassPathResource("beans.xml"));
(1)XmlBeanFactory 继承 AbstractBeanDefinitionReader ,使用ResourceLoader 将资源文件路径转换为对应的Resource文件。
(2)通过DocumentLoader 对 Resource 文件进行转换,将 Resource 文件转换为 Document 文件。
(3)通过实现接口 BeanDefinitionDocumentReader 的 DefaultBeanDefinitionDocumentReader 类对Document 进行解析,并且使用 BeanDefinitionParserDelegate对Element进行解析。
step1:
在平常开发中,我们也可以使用Resource 获取 资源文件:
Resource resource = new ClassPathResource("application.xml");
InputStream in = resource.getInputStream();
step2:
在资源实现加载之前,调用了 super(parentBeanFactory) -- /**Ignore the given dependency interface for autowiring.(忽略接口的自动装配功能)*/
调用XmlBeanDefinitionReader 的 loadBeanDefinitions()方法进行加载资源:
(1) 对Resource资源进行编码
(2) 通过SAX读取XML文件来创建InputSource对象
(3) 核心处理
可以很直观的看出来是这个function是在解析xml文件从而获得对应的Document对象。
在doLoadDocument方法里面还存一个方法getValidationModeForResource()用来读取xml的验证模式。(和我关心的没什么关系,暂时不看了~)
转换成document也是最常用的方法:
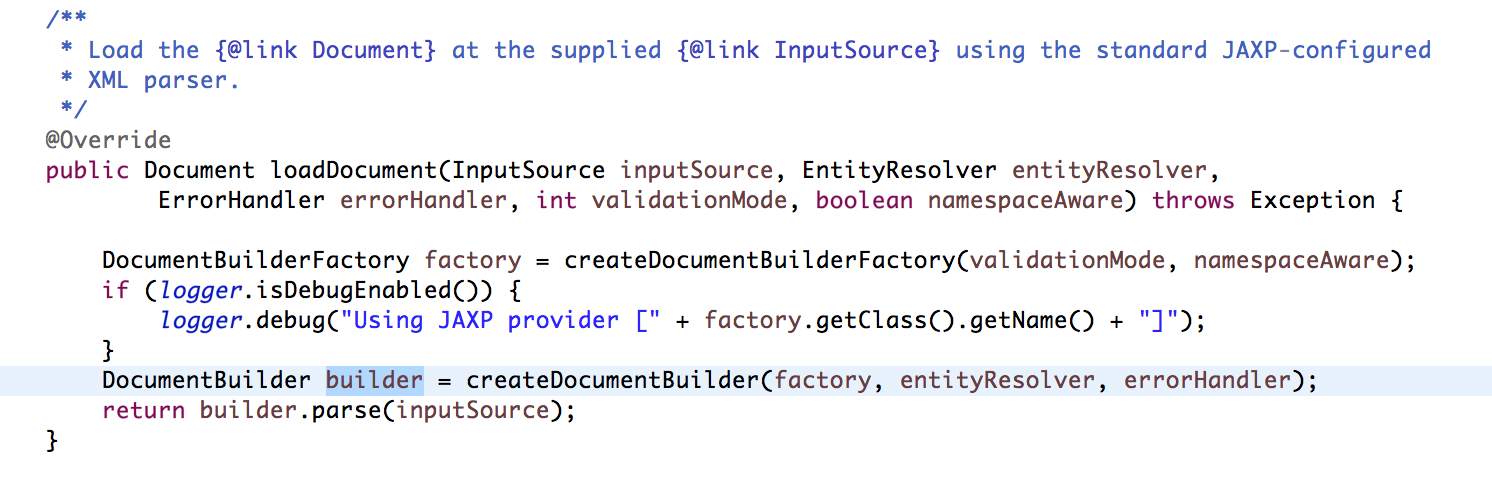
step3 : 我们已经step by step 的看到了如何将xml文件转换成Document的,现在就要分析是如何提取和注册bean的。
/**Register the bean definitions contained in the given DOM document*/
参数doc是doLoadBeanDefinitions()方法传进来的 loadDocument 加载过来的。这边就很好的体现出了面向对象的单一全责原则,将逻辑处理委托給单一的类去处理。
在这边单一逻辑处理类是: BeanDefinitionDocumentReader
核心方法: <font color="#FF0000">documentReader.registerBeanDefinitions(doc, createReaderContext(resource));</font>
<font color="#FF0000"></font>
<font color="#FF0000">开始解析:</font>
<font color="#FF0000"></font>
在Spring的xml配置中有两种方式来声明bean:
一种是默认的: <bean id = " " class = " " />
还有一种是自定义的: < tx : annotation-driven / >
通过xml配置文件的默认配置空间来判断:http://www.springframework.org/schema/beans
对于默认标签的解析:
对Bean 配置的解析:
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele); 返回BeanDefinitionHolder
这边代码大致看下来:
- 提取元素中的id和name属性
- 进一步解析将其他属性封装到 BeanDefinition 的实现类中
- 如果没有指定beanName 变使用默认规则生成beanName
- 封装类BeanDefinitionHolder
可以先了解一下 BeanDefinition 这个类的作用。
BeanDefinition是一个接口,对应着配置文件中<bean>里面的所有配置,在Spring中存在着三个实现类:
在配置文件中,可以定义父<bean>和子<bean>,父<bean>是用RootDefinition来表示,子<bean>是用ChildBeanDefinition来表示。
Spring 通过BeanDefiniton将配置文件中的<bean>配置信息转换为容器内部表示,并且将这些BeanDefinition注册到BeanDefinitonRegistry中。
Spring容器的BeanDefinitonRegistry就像是Spring配置信息的内存数据库,主要是以map的形式保存的。
因此解析属性首先要创建用于承载属性的实例:
然后就是各种对属性的解析的具体方法:







网友评论