‘grt123’团队的解决方案——NDSB 2017竞赛
原文:Solution of the 'grt123' team
注:本文为The Data Science Bowl (DSB) 2017竞赛的第一名获奖团队‘grt123’的解决方案,如需查看代码可访问Github。
引言
所使用的模型为基于三维卷积神经网络的结节检测和癌症分类的统一框架,以经过预处理后的3D肺部CT图作为输入,输出为d带边框标记的可疑结节和患癌的概率。
该解决方案可划分为三个模型:
- 预处理;
- 结节检测;
- 肿瘤分类。
预处理
将所有原始数据转换为HU值所表示。
掩膜提取
对每个切片,2D图像使用高斯滤波()和二值化(阈值为-600)处理,所有小于
或离心率大于0.99的2D connected components被去除;再计算得到的二值化的3D矩阵中,仅保留非边缘部分以及体积在
之间的部分。
保留非边缘部分是为了去除肺部周围较暗的部分。而去除离心率大于0.99部分,对此还不明白。
对保留区域做进一步分析。对每一个component,计算其面积(Area)以及到切片中心的距离(MinDist)。若component面积大于且其到切片中心的平均距离大于
,则将其去除。剩余的component以并集的形式组合,掩膜以基于图像灰度的形式呈现。

凸包与扩张
不断腐蚀掩膜直至两个components的体积相同,再分别将它们扩大到原来的大小,并与原始掩膜相交。对于每个掩膜,若增加的面积未超过50%,则用凸包代替2D二值图像。
将整个肺部分为左、右两部分,即左、右肺。
掩膜进一步扩张10体素,用于包含一些周围的区域。最后,一个完整的掩膜由两个component的掩膜组成,即左、右肺的掩膜组成。
对于结节与肺的外壁相连的情况,需要对掩膜进行凸包与扩张操作。
灰度标准化
将HU值[-1200, 600]线性变换为[0, 255],且掩膜以外的灰度值均设为170,扩张区域内的灰度值若高于210,则将该部分的灰度值设为170。
数据集
使用LUNA16数据集和NDSB3中的stage 1数据集用于训练模型。
对于LUNA16数据集,其存在许多较小的注释结节,且临床经验认为直径6mm以下的肺结节无危险。但在NDSB3数据集中,存在较多的大直径结节,且结节多与主支气管相连。因此,针对两个数据集的差异,需去除LUNA16数据集中6mm的结节,同时对NDSB3数据集进行人工标注。
注:作者非专业人员,但下一阶段的模型能够对人工标注的信息进行修正。
结节检测
采用基于3D的proposal net的3D卷积神经网络用于检测可疑结节,直接使用预测的proposal作为检测结果。
输入数据
受限于显存,输入数据大小为,并随机选择两种patch:
- 70%的输入数据至少包含一个结节;
- 30%的输入数据不含结节。
其中,patch超出图像部分以170的灰度值填充。
同时,为了避免过拟合问题,使用数据增强方法。
正反例数据
正例数据
由于两部分数据集中结节大小分布不均,因此对30mm和40mm的大结节的采样频率设为其他结节的2倍和6倍。
根据实际数据集情况,进行针对性调整。
反例数据
对于一些易误诊为结节的数据,可使用hard negative mining方法解决。
具体方法为:
- 将不同的patch输入至网络得到不同置信度的输出映射;
- 随机选择N个反例数据构成候选池;
- 候选池中的数据以置信度值大小排序,并选出top-n的数据作为反例数据。
其中,未选中的数据忽略且不参与损失计算。
网络结构
网络基于U-net网络模型,由前馈路径和反馈路径构成,如下图所示:
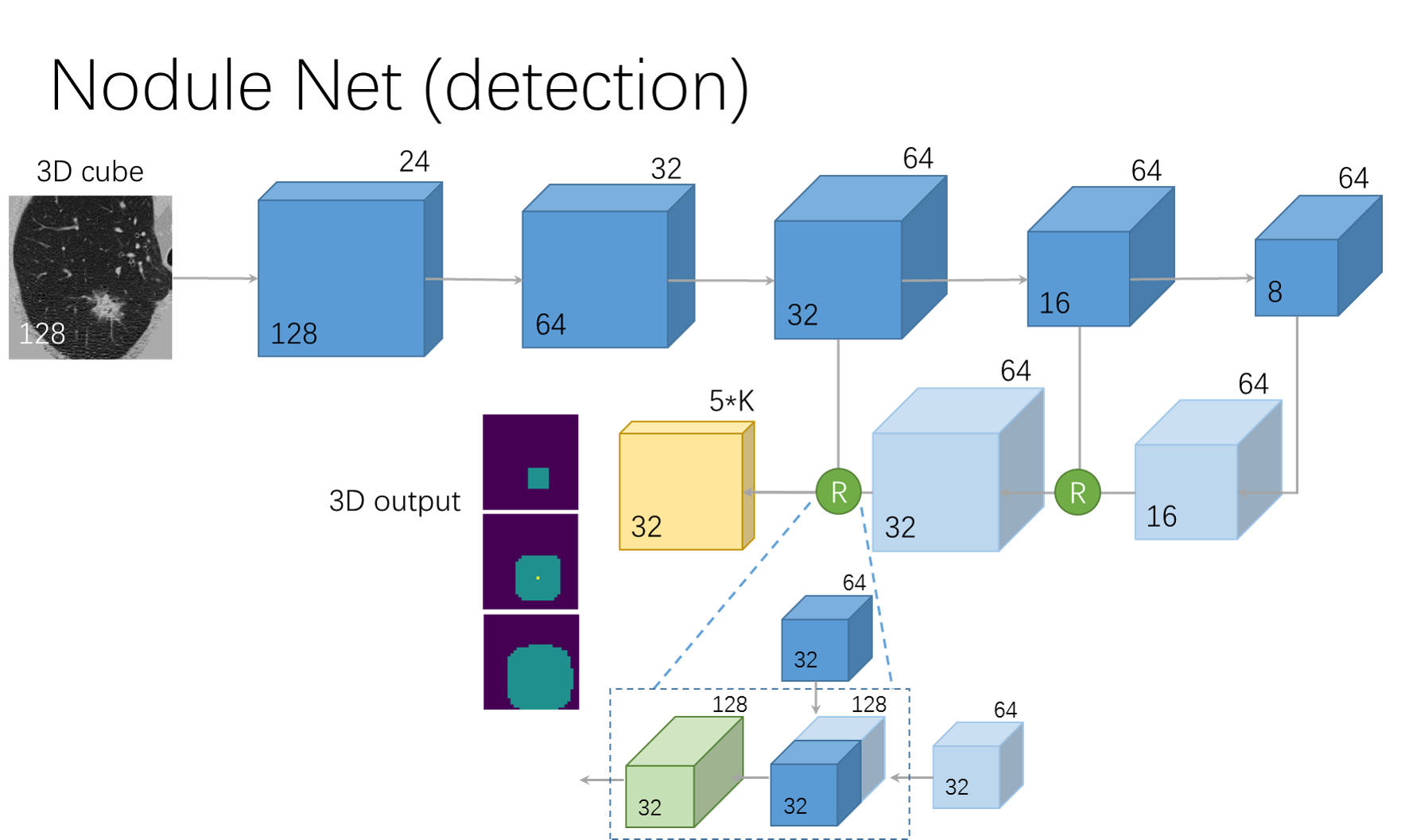
前馈路径
以两层卷积核为的卷积(channel为24)开始,且padding为1;其后为4个残差块,其中每个残差块由3个残差单元组成,而每个残差单元由卷积、Batch Norm、ReLU激活函数、卷积和Batch Norm组成,且卷积核大小均为
。除此之外,每个残差块均有一个最大池化层,大小为
,步长为2。
反馈路径
反馈路径由两层反卷积(装置卷积)层和两个融合单元构成。最后,由卷积核均为且channel为64和15的两层卷积层将数据大小转换为
。
反卷积层
卷积核大小为2,步长为2。
融合单元
每个融合单元均由一个前馈blob和反馈blob组成,其结果作为残差块的输入。
输出层
输出数据为4D的tensor,,其中3表示anchor个数,5表示回归量(
,即概率,三维坐标和bounding box直径大小)。
其中,对于激活函数采用sigmoid函数,其余不使用任何激活函数。
测试阶段中的全卷积输出
受限与显存,将图像分割为几个小部分,并分别对其进行处理,最后将其合并。其中,使用非极大值抑制法去除overlaping proposal。
肿瘤分类
由于受限于训练样本数,因而复用结节检测器阶段的N-net网络。
输入数据为结节的proposal,大小均为,其仅使用了结节中心点的信息。在分类器训练阶段,随机挑选proposal,且其选中的概率与proposal的置信度成正比;在测试阶段,只挑选top-5的proposal。
经卷积核为的最后一个卷积层得到输出结果;随后提取每个proposal中心处
的体素,并将其通过最大池化操作后得到128维的特征。
使用作为最终的分类方法。其中,
表示良性结节(the dummy nodule)患癌的概率。
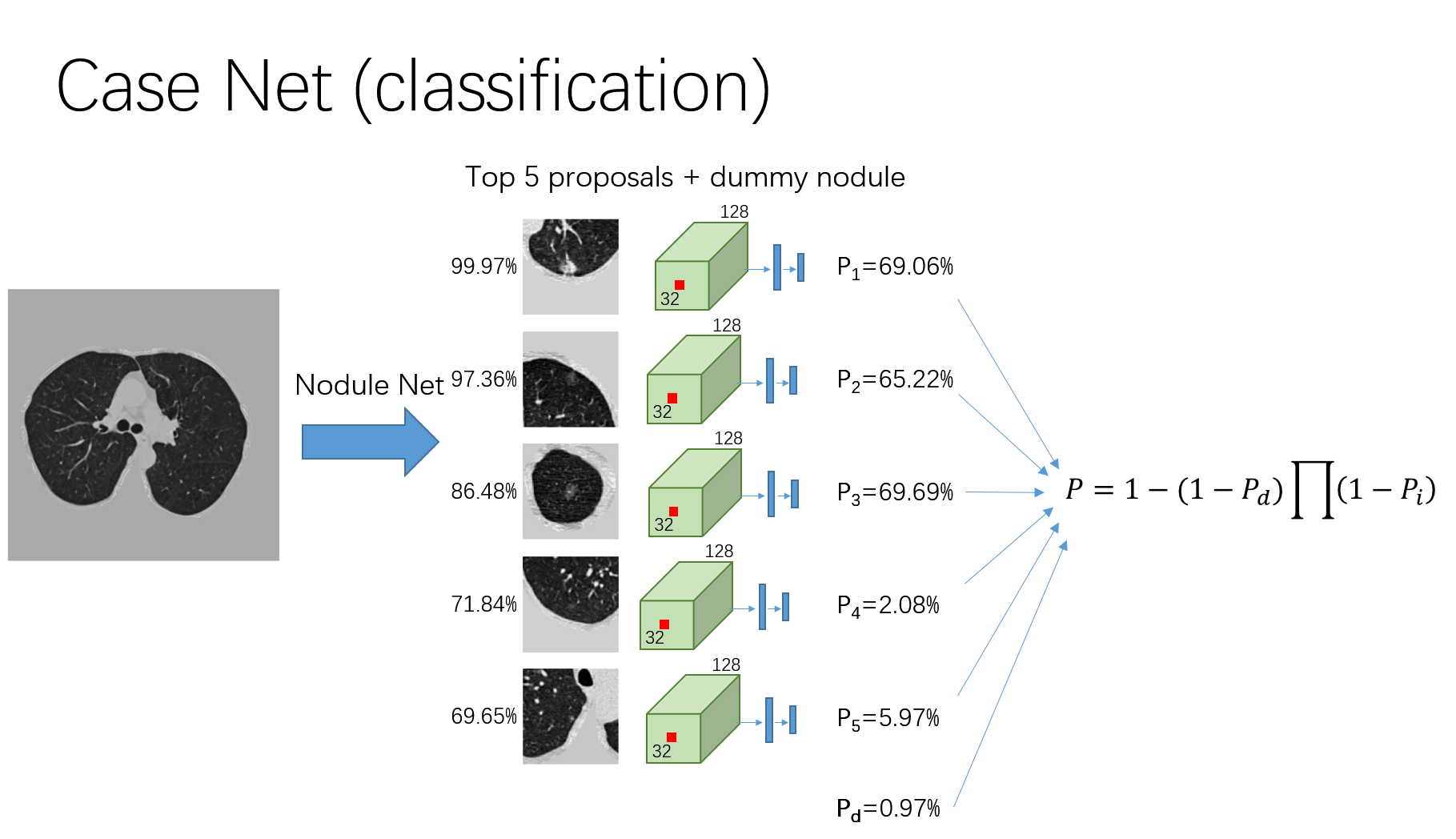
增加了一个额外的loss用于促进训练。若小于0.3且其对应的proposal在N-Net网络训练中标记为结节,则对于分类网络其loss将增加一个
。
训练过程
损失函数为交叉熵函数。为了避免过拟合采用了数据增强和正则化操作。
训练的步骤:
- transfer检测器训练参数后,再训练分类器;
- 采用gradient clipping方法训练分类器,随后存储BN(Batch Normalization)参数;
- 用存储的BN参数和gradient clipping方法交替训练检测器和分类器。
注:BN在训练阶段和测试阶段所计算的方法有所差异。因复用N-net网络,分类器和检测器交替训练,因而需对BN的参数做特殊处理。
实现
使用随机梯度下降算法和step-wise learning rate schedule方法训练网络,其中,当loss不再降低时,学习率降低1/10,直至网络收敛。




网友评论