这篇博客介绍了一个RNN起名器的基本思路和数据获取。
1. 起因
学习完一些RNN的基础知识,看过一些学术论文以后,像通过一个小项目来练练手。一来加强对模型本身的理解;二来可以提高编码能力和对框架的熟悉程度。
受到char-rnn的启发,同时考虑到歌词生成和诗歌生成没有什么新意,于是决定写一个名字生成器。
2.思路
取名字在中国一直是一个稳定的需求,但是国内起名字,一般需要综合生辰八字,甚至还要居住地址,因为这样取出来的名字是独一无二的。让我们先简化需求,第一步,我们要达成的目标就是根据一个姓和指定的名字长度,输出一些名字。
这个需求和生成诗词没有本质的区别,最大的不同就是训练数据。
起初我的想法是找一些现有的人口普查数据,使用现有的人名信息作为训练数据;但是转念一想,这些现有的人名不一定是好名字。于是,我又上一些姓名网站找到了一些不错的姓名推荐。当然,我没有把这些姓名一个个check过,暂且认为这些推荐都是不错的名字吧。
3.数据获取
确定了目标数据源以后,就可以开启爬虫了。具体爬的是哪个网站我就不说了,直接给出爬虫的代码。爬虫的代码也不再解析了,代码上的注释写的很清楚,也不是重点。
4.字向量的训练
这个项目中用到的字向量,不是随机生成的;而是使用预训练的字向量,具体使用python第三方库:gensim。
下面简单总结下训练过程,参考这篇博客:
(一).下载训练语料
使用中文wiki语料库(1.2G)作为训练语料。
(二).安装gensim
使用pip安装即可:
pip install gensim
(三).预处理训练语料
python 1_process_wiki.py zhwiki-latest-pages-articles.xml.bz2 wiki.cn.text
1_process_wiki.py这个脚本目的是将训练语料的文本从xml文件中抽取出来。
生成的wiki.cn.text:

可以看到生成的语料都是繁体字,还包括一些英文。
(四).繁体转简体
使用一种叫opencc的工具:OpenCC(github地址),直接下载源码,然后:
make
sudo make install
编译安装完毕以后:
opencc -i wiki.cn.text -o wiki.cn.text.jian -c t2s.json
生成的wiki.cn.text.jian:

(五).删除其他字符
繁体转成简体后,要删除除了汉字字符外的其他字符。
汉字字符unicode范围:\u4e00-\u9fa5
可以通过下面的正则匹配:
ss = re.findall(ur'[\n\s\r\u4e00-\u9fa5]', line)
执行脚本2_remove_words.py:
python 2_remove_words.py wiki.cn.text.jian wiki.cn.text.jian.removed
生成的wiki.cn.text.jian.removed:

(六).分割训练语料
既然是训练字向量,那么必须把每个字符分割开。
执行脚本3_seperate_char.py:
python 3_separate_words.py wiki.cn.text.jian.removed wiki.cn.text.jian.removed.sep
生成的wiki.cn.text.jian.removed.sep:
(七).训练字向量
执行脚本4_train_word2vec_model.py:
python 4_train_word2vec_model.py wiki.cn.text.jian.removed.sep wiki.cn.text.jian.model wiki.cn.text.jian.vector
-
wiki.cn.text.jian.model:gensim可以直接加载的文件。
-
wiki.cn.text.jian.vector:其他程序也可以读取的以文本保存的向量文件。
生成的wiki.cn.text.jian.vector:
在gensim中测试:
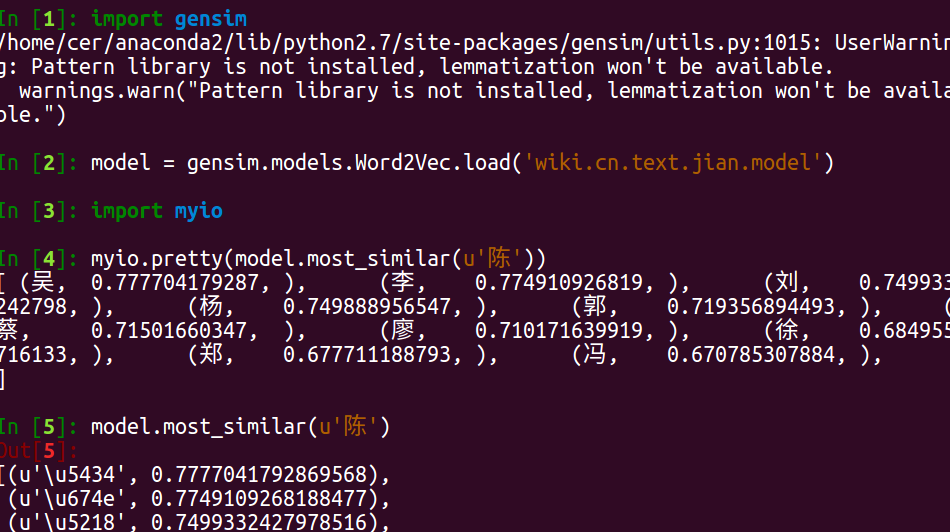
注:myio.pretty()是我自己写的函数,只为print出list中的汉字。




网友评论