前言
这篇文章本来是我一年多前看《图解HTTP》做的笔记,但记完后放在文件夹的某个角落一直没管。前段时间撸项目练手的时候,在状态码上碰到了问题,因此又拿了出来翻了翻,同时又在原有的基础上做了些修改,补上了HTTPs的一些东西。这篇文章主要是对HTTP相对重要的知识的一些概括,想要好好学习HTTP还是需要看《图解HTTP》或者《HTTP权威指南》,才能构建较为完整的知识体系。最后,你没有猜错,我就是传说中的标题党,但希望这篇文章对你有用,哪怕是一丁点,2333。
1.HTTP简述(出自MDN)
超文本传输协议(HTTP)是用于传输诸如HTML的超媒体文档的应用层协议。它被设计用于Web浏览器和Web服务器之间的通信,但它也可以用于其他目的。 HTTP遵循经典的客户端-服务端模型,客户端打开一个连接以发出请求,然后等待它收到服务器端响应。 HTTP是无状态协议,意味着服务器不会在两个请求之间保留任何数据(状态)。虽然通常基于TCP / IP层,但可以在任何可靠的传输层上使用; 也就是说,一个不会静默丢失消息的协议,如UDP。
2.URL和URI
我们经常会接触到URL(统一资源定位符),它就是我们用于访问web的一个字符串地址.而URI对我们来讲就相对比较陌生了,它的名字叫做统一资源标识符(URI)。我们来看看它们具体的区别吧:
- URI:uniform resource identifier 统一资源标识符,一种资源的标识,它是一种抽象的资源标识,即可以是相对的,也可以是绝对的。
- URL:uniform resource location 统一资源定位符,同时一种资源的标识,但指明了如何定位Locate这个资源。因为它指明了定位的信息,所以必须是绝对的。
(我们平时所说的相对地址,其实只是相对于另一个绝对地址而言的)
2.1 URL
URL的基本格式如下:
schema://host[:port#]/path/.../[?query-string][#anchor]
| 格式 | 意义 |
|---|---|
| scheme | 指定低层使用的协议(例如:http, https, ftp) |
| host | HTTP服务器的IP地址或者域名 |
| port# | HTTP服务器的默认端口是80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如 http://www.cnblogs.com:8080/ |
| path | 访问资源的路径 |
| query-string | 发送给http服务器的数据 |
| anchor- | 锚 |
3.HTTP报文
3.1 HTTP报文格式
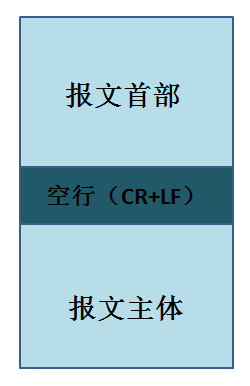
HTTP的报文格式主要分为报文首部和报文主体:
 image
image
其中的空行用于区分报文首部和报文主体内容,是由一个回车符和一个换行符组成的。
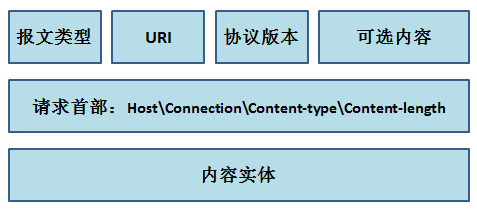
无论是请求报文还是响应报文都需要有报文首部,而报文主体有些请求报文是没有的。而请求报文的一般格式如下:
 image
image
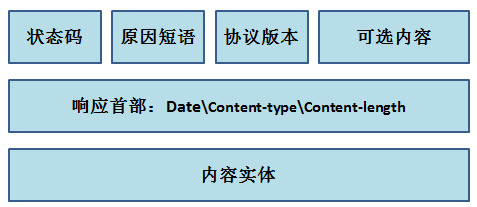
而响应报文的格式是这样的:
 image
image
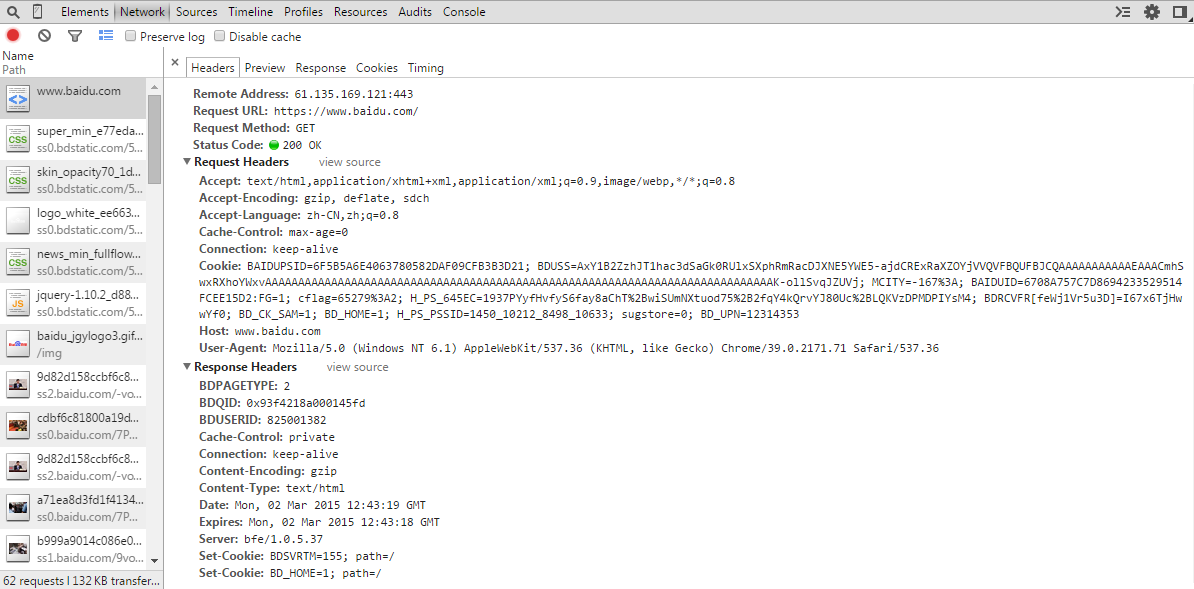
下面是谷歌浏览器的HTTP报文内容,其中request headers描述了请求报文头部的内容,response headers描述了响应报文头部的内容:
 image
image
其中最常见的属性如下:
- URL, 即http访问的地址
- request method, 报文的请求方式
- status code, 状态码以及状态短语
- Accept Encoding, 内容编码
- Connection, 连接方式
- Cookie, 添加的cookie内容
- Host, 目标主机
- User-Agent, 客户端浏览器的相关信息
- Set-Cookie, 指定想要在Cookie中保存的内容
接下来就聊一聊这些属性的作用
3.2 HTTP请求方式(request method)——GET and POST
发送HTTP的方式有很多,但最常用的还是POST和GET。
-
GET:GET方法可以用来请求访问已经被URL识别的资源。指定的资源经过服务端解析后返回响应的内容。简单来说,就是请求的资源是文本的话,那么就保持原样返回.
 image
image
-
POST:POST方法可以用来传输实体的主体。
 image
image
这两者的区别主要如下:
- 使用目标不同
POST与GET都用于获取信息,但是GET方式仅仅是查询,并不对服务器上的内容产生任何作用结果;每次GET的内容都是相同的。POST则常用于发送一定的内容进行某些修改操作。
- 大小不同
由于不同的浏览器对URL的长度大小有一定的字符限制,因此由于GET方式放在URL的首部中,自然也跟着首先,但是具体的大小要依浏览器而定。POST方式则是把内容放在报文内容中,因此只要报文的内容没有限制,它的大小就没有限制。
- 安全性不同
上面也说了GET是直接添加到URL后面的,直接就可以在URL中看到内容。而POST是放在报文内部的,用户无法直接看到。
总的来说,GET用于获取某个内容,POST用于提交某种数据请求,从使用场景来看,一般用户注册的内容是私密的,应该使用POST方式来保持私密,而当需要查询某个内容时,需要快速响应,则使用GET。
3.3 status code状态码
状态码通常就是服务器端对客户端说的话,分类如下:
| 状态码 | 含义 |
|---|---|
| 1** | 服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重新定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
常见的状态码:
- 200 通常的成功 OK
GET:请求的对应资源会作为响应返回。响应将包含描述或操作的结果。
POST:返回处理对应请求的结果。
- 204 成功处理请求,没有返回任何内容 No Content
表示服务器接收到的请求已经处理完毕,但是服务器不需要返回响应。比如,客户端是浏览器的话,那么浏览器显示的页面不会发生更新。
- 206 Partial Content
成功处理了部分GET请求
- 301 Moved Permanently
请求的网页已永久移动到新位置,永久性重定向
- 302 Found
网站临时性重定向,暂时不能访问(备案、被查)
- 303 See Other
该状态码表示由于请求对应的资源存在另一个URI,并指定必须使用GET方法定向获取请求的资源。和302不同的是,302是不会改变上次的请求方法
- 304 Not Modified
访问不了,并返回和上次一样的话,表示资源未被修改过,还是和上次访问时一样。
- 307 Temporary Redirect
临时重定向,和302、303类似,不同的是,不会指定客户端要用什么样的方法请求,
- 400 Bad Request
表示客户端中存在语法错误,导致服务器无法理解该请求。客户端需要修改请求的内容后再次发送请求。
- 401 Unauthorized
即用户没有必要的凭据。该状态码表示当前请求需要用户验证。
- 403 Forbidden
服务器已经理解请求,但是拒绝执行它。
- 404 Not Found
服务器找不到请求的网页。
- 500 Internal Server Error
服务器遇到错误,无法完成请求。
- 503 Service Unavailable
由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是暂时的.
3.4 内容编码 Accept Encoding
由于有些报文的内容会过大,为了减少传输时间,HTTP会采取一些压缩的措施,例如上面的报文信息中,Accept-Encoding就定义了内容编码的格式gzip。
总的来说内容编码的格式有以下几种:
- gzip:GNU压缩格式
- compress:UNIX系统的标准压缩格式
- deflate:是一种同时使用了LZ77和哈夫曼编码的无损失压缩格式
- identity:不进行压缩
3.5 持久化——connection
正常发送HTTP时,我们需要建立TCP的连接,然后再发送报文:
 image
image
如果每次都要发送HTTP报文都需要经历上面的拿过过程,无疑将会耗费很多时间在建立和断开连接的过程中,因此HTTP使用了connection属性,用于指定连接的方式,当当设置成keep-alive时,就会建立一条持久化的连接。这样就不需要每次都建立连接在中断连接:
 image
image
(HTTP1.1中connection默认开启keep-alive)
3.6 无状态的HTTP——cookie
由于HTTP是一种无状态的协议,这是由于Web服务器要面对很多浏览器的并发访问,为了提高Web服务器对并发访问的处理能力,在设计HTTP协议时规定Web服务器发送HTTP应答报文和文档时,不保存发出请求的Web浏览器进程的任何状态信息,从而减轻服务器端的负载,同时无状态也减小了HTTP请求的开销。
但当有些场景需要时刻记住用户的信息时,无状态很明显不能满足需求,因此HTTP提供了cookie来解决这个问题,cookie技术通过在请求和相应报文中写入cookie信息来控制客户端的状态。cookie会根据从服务端发送的相应报文内的一个叫做set-cookie的首部字段信息,通知客户端保存cookie。当下次客户端再往服务器发送请求的时候,客户端会自动在请求头加入cookie值后发送出去。在没有cookie状态下的请求:
 image
image
当存有cookie后的请求:
 image
image
简单来说Cookie是一种由服务器端确定,并保存在客户端浏览器中的内容。这样就与每次都去添加用户的信息,请求会自动添加cookie中对应的内容。
(关于浏览器端的数据存储感兴趣的可以看下这篇文章::聊一聊常见的浏览器端数据存储方案)
3.7 范围请求
在一些场景下,我们在使用HTTP报文请求一些很大的图片时,加载过程往往会很慢。(比如一些摄影网站)这时候我们就会发现一些图片是一块一块加载的。这是应为设置了HTTP请求的长度,从而分块的加载资源。在请求报文中使用Range属性,在响应报文中使用Content-Type属性都可以进行指定一定自己的HTTP请求。
3.8 报文首部总结
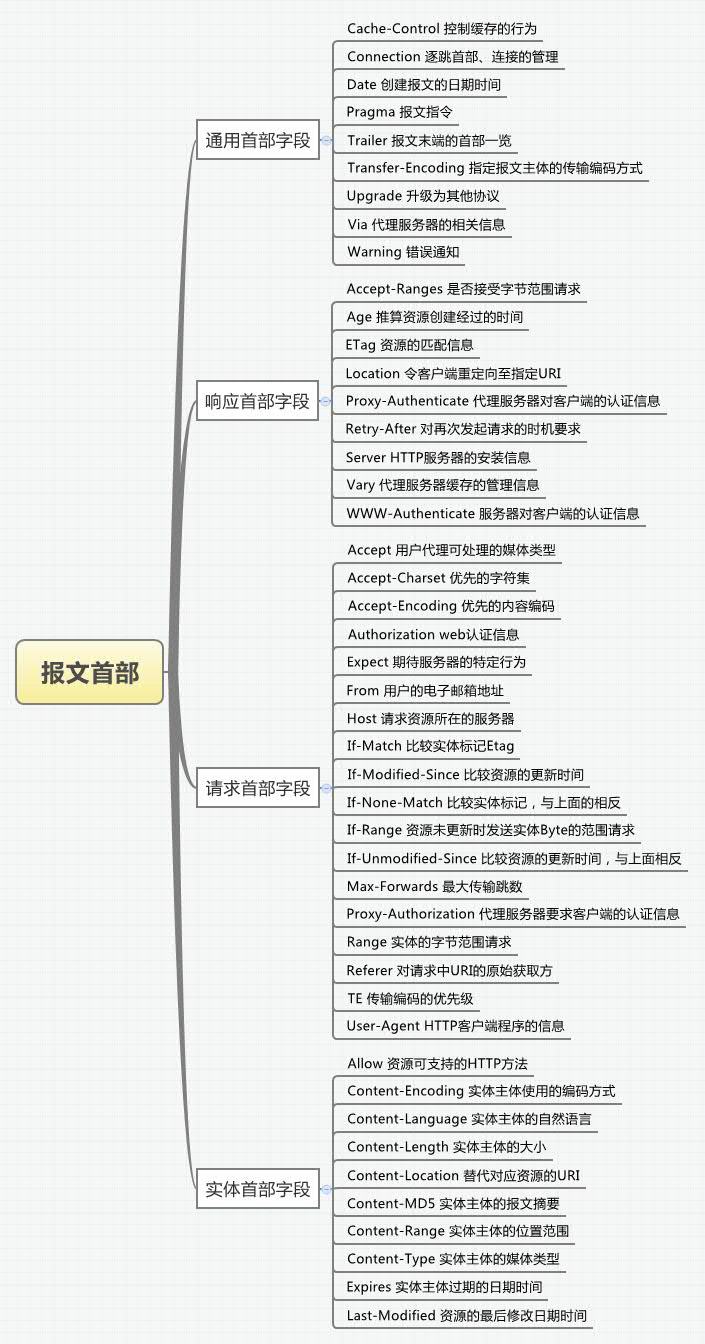 image
image
(图转自:http://www.cnblogs.com/xing901022/p/4311987.html)
4.HTTP方法
HTTP 支持几种不同的请求命令,这些命令被称为 HTTP 方法(HTTP method)。每
条 HTTP 请求报文都包含一个方法。这个方法会告诉服务器要执行什么动作(获取
一个 Web 页面、运行一个网关程序、删除一个文件等)。下表是一些常见的HTTP方法:
| HTTP方法 | 描述 |
|---|---|
| GET | 从服务器向客户端发送命名资源 |
| PUT | 将来自客户端的数据存储到一个命名的服务器资源中去 |
| DELETE | 从服务器中删除命名资源 |
| POST | 将客户端数据发送到一个服务器网关应用程序 |
| HEAD | 仅发送命名资源响应中的 HTTP 首部 |
(GET和PUT已在上面讨论过了,这里就不在讨论了)
4.1、PUT传输文件
PUT方法用于传输文件,就像FTP协议的翁建上传一样,要求在请求报文的主题中包含文件内容,然后保存到请求URI指定的位置。由于PUT方法不带验证机制,任何人都可以任何人都可以上传文件,存在安全性问题,因此一般的web网站不适用该方法。
4.2、DELETE删除文件
DELETE方法用来删除文件,是与put相反的方法,DELETE方法按照请求url删除指定的资源。其本质和PUT方法一样不带验证机制,所以建议少用DELETE方法。
4.3、HEAD获取报文首部
HEAD和GET方法一样,只是不返回报文主体部分,通常用于确认url的有效性及资源更新的日期时间等。
 image
image
5.HTTPS
5.1 什么是HTTPS
HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单来说就是是HTTP的安全版本,即在HTTP下加入SSL层,HTTPS的安全基石是SSL,因此加密的详细内容就需要SSL。 它现在已经被广泛应用,比如GitHub,支付宝,掘金等。
5.2 为什么需要HTTPS
这是由于HTTP有这么几个缺点:
- 传输的时候使用明文,这显然会被不法者截取干一些见不得人的勾当。
- 没有认证机制,这样我们就可以伪造一些HTTP访问,这显然会造成一些困扰。比如Jmeter就是典型的例子,伪造一大堆的HTTP URL然后压力测试,这也就是DOS攻击的一种。
- 无法验证报文的完整性,比如一个HTTP的报文已经被不法者截取并且篡改,服务器端也无法验证。
5.3 HTTP 与 HTTPS 的区别
正是由于以上这些缺点,HTTPS作出了以下一些改变:
- HTTP 是明文传输,HTTPS 通过 SSL\TLS 进行了加密
- HTTP 的端口号是 80,HTTPS 是 443
- HTTPS 需要到 CA 申请证书,一般免费证书很少,需要交费
- -HTTPS 的连接很简单,是无状态的;HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 HTTP 协议安全。
5.4 HTTPS的缺陷
可以说HTTPS相对于HTTP就是套上了黄金甲的圣斗士,变了身的奥特曼,沉睡了的毛利小五郎,不仅仅提升了安全,还提升了逼格。但HTTPS也有一些缺陷:
- 通信的速度变慢,由于需要加密,一个握手就多了好几个往返
-
对用户的机器负载的增加。(说出来你们可能不信,我们学校一到晚上,用HTTPS协议的网站基本上都上不了)
 image
image
6. HTTP认证
有一些网站需要用户的登录从而获取用户的个人信息来进行接下来的操作,因此需要随时知道这些消息,但是肯定不能每次都让用户输入用户密码,这样会让用户感觉很不爽,因此HTTP也自带了认证的功能,认证方式主要如下:
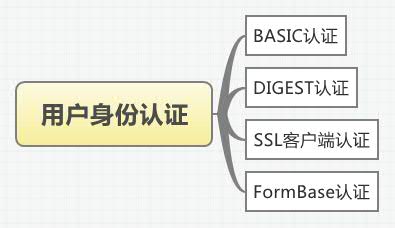 image
image
6.1 BASIC认证
其中BASIC认证是最简单的认证,大致过程如下:
- 客户端访问某URL。
- 服务器端返回401状态码,提示用户输入用户名密码。
- 用户输入用户名密码,通过BASE64编码传输。
- 服务器通过认证,返回状态码200
但它有以下缺陷:
- 仅仅通过BASE64编码,其实还是属于明文传输,安全性不高
- 有的浏览器不支持注销
6.2 DIGEST认证
正是由于BASIC认证存在弱点,因此从HTTP/1.1起就有了DIGEST认证,DIGEST认证同样使用质询/响应的方式,但不会像BASIC认证那样直接明文发送密码。
 image
image
6.3 SSL认证(比较常见)
SSL客户端认证是借由HTTPS的客户端证书完成认证的方式。凭借客户端证书认证,服务器可确认访问是否来自已登录的客户端。
SSL客户端认证的步骤:
- 服务器接收到需要认证资源的请求时,服务器会发送CertificateRequest报文,要求客户端提供客户端证书。
- 客户端将客户端证书信息以Client Certificate报文方式发送给服务器。
- 服务器验证客户端证书验证通过后才能领取证书内客户端的公开密钥,然后开始HTTPS加密通信。
像支付宝,网银之类对安全要求很高的网站,在登录时,都需要下载一个数字认证,这个数字认证就属于一种SSL客户端的验证。但它的缺点也很明显,需要手动下载,对于现在越来越懒的网民们来讲会感觉很麻烦(包括我)
6.4 表单认证(最常用的)
最后一种认证方式是最常见的,我们可以通过cookie或session来进行认证。
Session管理和Cookie应用的结合
我前面提到过,HTTP是无状态协议,无法实现状态管理,因此有了cookie。我们就可以使用Cookie来管理Session(会话),以弥补HTTP协议中不存在的状态管理功能。
认证步骤:
- 客户端把用户的ID和密码等相关信息放入报文的实体部分,然后通常以POST请求的方式发送给服务器。
- 服务器会发放用以识别用户的Session ID。通过验证从客户端发送过来的登录信息进行身份认证,将用户的认证状态和Session ID绑定后记录在服务器端。
- 客户端接收到Session ID后,会将其作为Cookie保存在本地。下次向服务器发送请求时,浏览器自动发送Cookie,Session ID会随之发送到服务器。服务端通过验证接收到的Session ID识别用户和其认证状态,然后用户就能执行特定的操作了。
参考资料:




网友评论