最近一直忙着写SQLAlchemy的教程,但是在看到关系查询时,需要引入join的概念。也只怪的当初数据库没有学好,感觉不太能理解join机制的概念。故这里也尝试写一下对join的理解。本文是基于JOIN的Wiki。
在关系型数据库中,JOIN本质上是基于涉及的两个或者多个表进行结合重构的过程点。其创造的结果可以被保存为一个表(table)或者是作为一个表来使用。这个结合的过程的基础,或者说联系点,是存在于两个表之间的共通的列。一般来说,ANSI标准的SQL定义了如下这些JOIN操作类型:
- INNER
- LEFT OUTER
- RIGHT OUTER
- FULL OUTER
- CROSS
例表
关系型数据库通常数据关系的抽象来减少数据冗余。例如,一个Department会同多个Employ关联。
Employ表如下
| LastName | DepartmentID |
|---|---|
| Rafferty | 31 |
| Jones | 33 |
| Heisenberg | 33 |
| Robinson | 34 |
| Smith | 34 |
| Williams | Null |
Department表如下
| DepartmentID | DepartmentName |
|---|---|
| 31 | Sales |
| 33 | Engineering |
| 34 | Clerical |
| 35 | Marketing |
其中Employ表中的DepartmentID是Department表中的主键。将不同的表JOIN起来就是以一定的规则(例如开头我们提到的五种),将两者的信息结合起来构成一张大表。(毕竟Join过程需要耗费时间,有时候为了提高查询性能,会直接将这两个表的Join结果作为一个大表存储在数据库中,不过这会耗费更多的存储空间)。
下面是创建这些两个表的SQL指令
CREATE TABLE department
(
DepartmentID INT,
DepartmentName VARCHAR(20)
);
CREATE TABLE employee
(
LastName VARCHAR(20),
DepartmentID INT
);
INSERT INTO department VALUES(31, 'Sales');
INSERT INTO department VALUES(33, 'Engineering');
INSERT INTO department VALUES(34, 'Clerical');
INSERT INTO department VALUES(35, 'Marketing');
INSERT INTO employee VALUES('Rafferty', 31);
INSERT INTO employee VALUES('Jones', 33);
INSERT INTO employee VALUES('Heisenberg', 33);
INSERT INTO employee VALUES('Robinson', 34);
INSERT INTO employee VALUES('Smith', 34);
INSERT INTO employee VALUES('Williams', NULL);
CROSS JOIN
CROSE JOIN返回两张表的笛卡尔积,也就是不指定结合规则,让两表中的元素直接两两组合。
SELECT *
FROM employee CROSS JOIN department;
下面这个SQL指令本质是隐式的CROSE JOIN:
SELECT *
FROM employee, department;
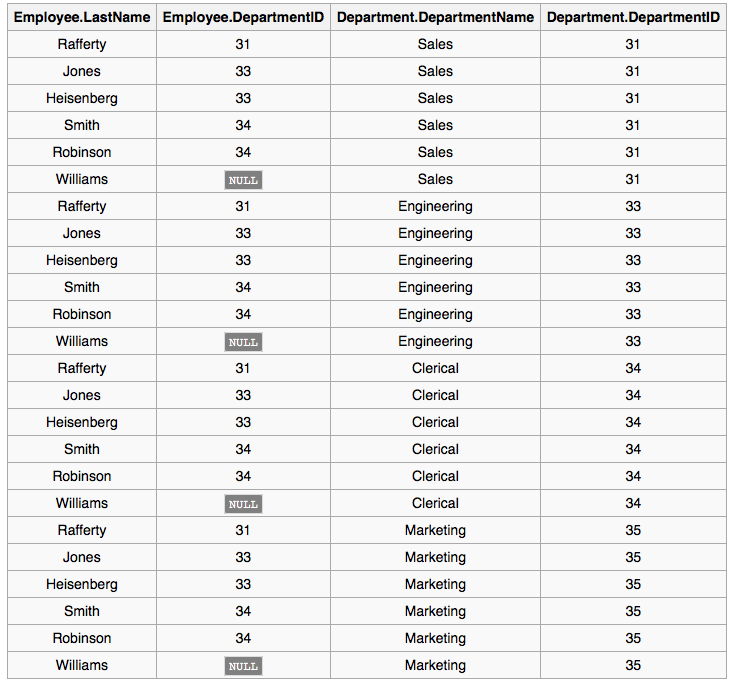
以开头的例表为例,执行结果为:
 CROSE JOIN
CROSE JOIN
CROSE JOIN没有应用任何筛选条件来控制返回的结果。当然其结果可以进一步通过WHERE来控制,从而产生等效于INNER JOIN的结果。通过这个语句用来检验数据库性能。
INNER JOIN
INNER JOIN要求在两个待JOIN的表(A和B)拥有有匹配的记录。这是一个非常用的JOIN方法,但是并非在每种情况下都是最优选择。和CROSE JOIN不同,INNER JOIN引入了predicate来指明结合的规则。查询指令最终对A中的每一行逐一和B中的各行进行比对,找到所有符合筛选条件的组合。这些组合被用来构造输出的新表。
上述过程也可以理解为对两表的笛卡尔积进行筛选后得到的结果。但是这样无疑性能会比较差,占用内存较多。实际的数据库实现中一般会采用其他的方法,如hash joins或者sorted-merge joins。
和CROSE JOIN类似,INNER JOIN也有显式和隐式两种写法。不过1992年隐式写法被deprecated掉了,也许现在有一些数据处于兼容性的考虑仍然支持这种写法。
显式的INNER JOIN会使用JOIN关键字,前面可以加INNER来指名JOIN种类,不加也可以。为了指明进行JOIN的规则,需要使用ON这个关键字。如下面这个例子:
SELECT *
FROM employee
INNER JOIN department ON employee.DepartmentID = department.DepartmentID;
隐式写法没有用到JOIN关键字,而是采用的对CROSE JOIN的结果进行筛选的方式。下面是隐式写法的一个例子:
SELECT *
FROM employee, department
WHERE employee.DepartmentID = department.DepartmentID;
上面两种写法的效果是一样的。上面例子中的查询,数据库使用两表中的Department列来进行join。来自两表的记录的DepartmentID吻合时,数据库会将LastName, DepartmentID以及DepartmentName 等两个表的属性结合起来构造出新表中的一行。如果DepartmentID不吻合,则不会产生新行。
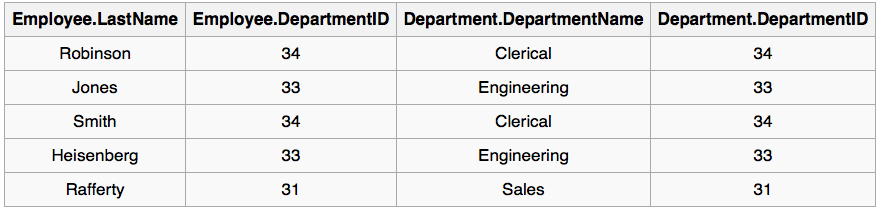
上面的SQL语句的执行结果如下:
 INNER JOIN
INNER JOIN
注意到名为William的雇员和名为Marketing的部门没有出现在上面的查询结果中。William没有关联的部门,Marketing没有关联的雇员。有时候我们不希望派车这些记录,此时就要使用OUTER JOIN了。+
注意:程序们在JOIN包含有NULL值的表时要特别注意,NULL不会和任何值匹配,包括自身(也就是NULL!=NULL),除非显示的在筛选条中记性控制(加入对NULL的判断)。在有些数据库中,强制启用了referential integrity,保证了不会出现NULL值,此时INNER JOIN可以安全的使用。由于数据库的实现细节各有不同,依靠数据库本身特性来避免NULL的问题不是很可靠,推荐的方法是尽量避免设置NULL,而是定义一个无意义的空值来代替。如字符串用""来代表NULL。
OUTER JOIN
使用OUTER JOIN时可以保证指定表的每条记录都出现----即使没有匹配。OUER JOIN又可以分为LEFT OUTER JOIN, RIGHT OUTER JOIN 和 FULL OUTER JOIN。取决于你想要保留的表是哪一个。
OUTER JOIN不存在隐式表达法。
LEFT OUTER JOIN
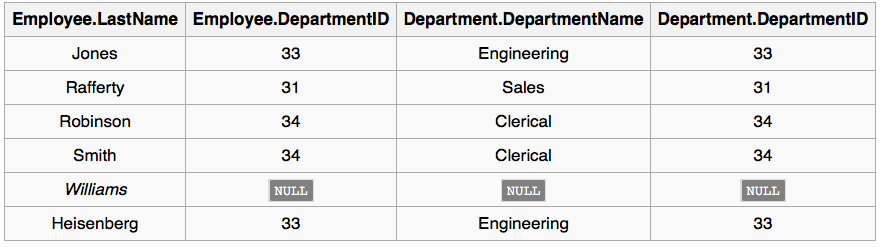
表A和表B的LEFT OUTER JOIN结果中总会保留左侧的A表的所有记录,即便A中的一些行没有B中的行与之对应。此时构造的新行中,所有的原B中的列的值会被填充为NULL。
如下例(OUTER关键字可以省略):
SELECT *
FROM employee
LEFT OUTER JOIN department ON employee.DepartmentID = department.DepartmentID;
筛选结果如下:
 LEFT OUTER JOIN
LEFT OUTER JOIN
RIGHT OUTER JOIN
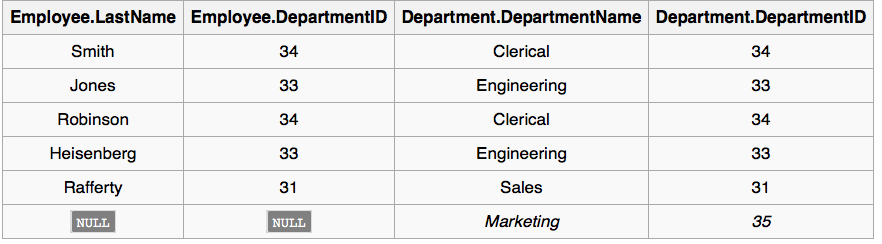
这个就好理解了,和LEFT OUTER JOIN是反着来的。如下面的例子。
SELECT *
FROM employee RIGHT OUTER JOIN department
ON employee.DepartmentID = department.DepartmentID;
查询的结果如下图:
 RIGH OUTER JOIN
RIGH OUTER JOIN
FULL OUTER JOIN
FULL OUTER JOIN同时保留两个表的列.
SELECT *
FROM employee FULL OUTER JOIN department
ON employee.DepartmentID = department.DepartmentID;
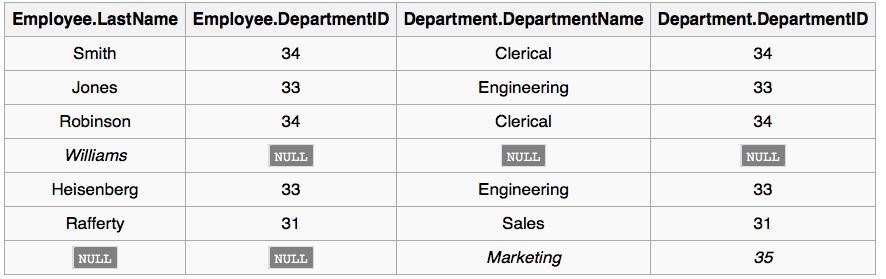 FULL OUTER JOIN
FULL OUTER JOIN
有些数据库不支持FULL OUTER JOIN,不过你可以通过INNER JOIN加上UNION ALL来实现同样的功能。下面给出了一个例子:
SELECT employee.LastName, employee.DepartmentID,
department.DepartmentName, department.DepartmentID
FROM employee
INNER JOIN department ON employee.DepartmentID = department.DepartmentID
UNION ALL
SELECT employee.LastName, employee.DepartmentID,
cast(NULL as varchar(20)), cast(NULL as integer)
FROM employee
WHERE NOT EXISTS (
SELECT * FROM department
WHERE employee.DepartmentID = department.DepartmentID)
UNION ALL
SELECT cast(NULL as varchar(20)), cast(NULL as integer),
department.DepartmentName, department.DepartmentID
FROM department
WHERE NOT EXISTS (
SELECT * FROM employee
WHERE employee.DepartmentID = department.DepartmentID)
Self-JOIN
一个特殊的情况是要JOIN的表其实是同一个表。例如,考虑下面这个表:
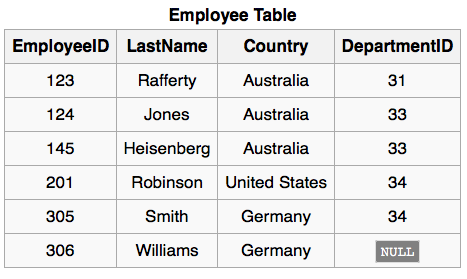 Self JOIN Table
Self JOIN Table
我们想要查找出来有哪些用户是来自同一个国家。也就是要讲上面这个表和它自身以Coutry这一列为基础进行JOIN。下面是一个例子:
SELECT F.EmployeeID, F.LastName, S.EmployeeID, S.LastName, F.Country
FROM Employee F INNER JOIN Employee S ON F.Country = S.Country
WHERE F.EmployeeID < S.EmployeeID
ORDER BY F.EmployeeID, S.EmployeeID;
查询结果如下:
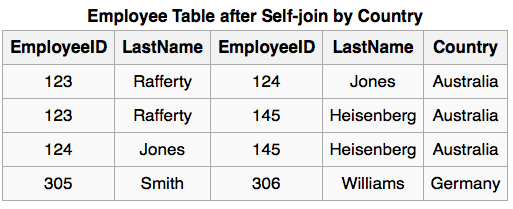 Self JOIN Result
Self JOIN Result
SQLAlchemy的教程第三部分快要出来了,欢迎大家关注~













网友评论