被约写一篇关于 AlphaGo Zero 的科普文章,然后要求一定要让小学生都能看懂,于是我发现我写得自己都看不懂了……
这篇实在感觉写得很糟,七格大大也认为标题党严重,于是写完以后用重新推翻重写了一篇,这篇就丢出来让大家一起唾弃吧…………
1. 逗逼的开场白
在地球上的所有生物中,人类大概是最独特的一个。
它虽然不是最强壮的,不是跑得最快的,不是最能有用的,更不是会飞的,不是最长寿的,当然也不是身体素质最好的,但却是最善于作死的。
这不,就在不久前,毁灭人类第四代已经被研发出来的,据说它的796代孙子能占领地球并返回过去猎杀未来,最终被人类穿越而来的保护者给终结了,呃,串场了……
AlphaGo Zero 用 89:11 的咋舌战绩干翻曾碾压人类世界第一的柯洁的 AlphaGo Master 来了一次让全世界为之一亮的登场,让碳基世界再度爆发出了到底怎么定义灵魂才能让人类永远处于比 AI 更高级的灵性地位的脑洞大征集,而一些更有悲世情怀的人比如我本人则开始考虑到底几年以后会被 AI 赶出办公室沦落街头开始学习用碗与卖萌讨生活,为此深入了解一下到底什么是人工神经网络什么是人工智能,对于将来势在必行的 AI 卢德运动来说也是很有必要的。
2. 苍井不空
要了解人类文明到底会被什么样的后继者取代或者超越,我们就必须来了解一下什么是人工神经网络。
人工神经网络,顾名思义,就是对神经网络的人工模拟。
这一思路很简单,那就是虽然我们无法像定义物理定律那样定义智能,从而想推导物理过程一样推演智能,但我们可以模仿那些具有智能的自然世界客体,从而通过模仿来获得智能,并最后看能否超越已有的自然之物。
这样的思路古已有之,衍生出仿生学这一门很有趣的学问。
人工神经网络就是这么一类仿生的造物,只不过它所模仿的对象,是大自然中最神秘也是最复杂的客体:神经网络。
生物的神经网络是由大量神经元组成的有向连通网络,它由节点与连线两部分构成,前者负责对信号的处理加工,后者决定了整个网络的拓扑结构。
更加距离来说,神经网络中的神经元就是这么一个东西,它从外界连接而来的上家接受到一批货物,然后根据自己的一套规则来决定传给下家的应该是一批什么样的货物——甚至可以扣下不传。
你可以把整个神经网络理解为一个巨大的高速公路网络,神经元就是一个个收费站。眼睛鼻子耳朵把一批货物传进这个高速公路网络,经过一批批收费站的盘剥之后,手和脚收到最终留下的东西,并根据这留下的东西进行行动:到底是躲开还是给一巴掌。
这么一讲,是不是觉得神经网络似乎很 Low ?
人工神经网络也是这样的,只不过它在模拟的过程中进行了大量的近似,比如说,人工神经网络认为每个节点的激活函数形式上都是相同的。
更加具体来说,在人工神经网络中,节点就是一个函数,输出的值传递给下一个节点,输入的值求和后作为函数的自变量。而连接则是一个增益权值,用来将输出节点的输出值增益后累加在输入节点的输入端上。
而,所谓的网络的学习,就是在给定误差函数的情况下,通过调节整个网络成万上亿的增益权值来使得误差函数最小化的过程。一旦我们认为整个网络已经使得误差足够小了,我们就可以拿这个网络去套新来的输入,并认为此时的输出就是最符合预期的输出。
比如说,我们拿棋局作为输入,最后的输赢结果作为输出,从来进行学习,让网络对于任意给定的输入都尽可能找到获胜的下一步,这样的网络就可以用来下棋。
所谓多者异也,神经元本身就是一个将输入转换为输出的函数,看似很简单,但一旦形成一个大规模的网络结构后,这样的神经网络却可以做很多事情。
从本质上来说,我们可以认为神经网络所做的,就是在输入与输出之间找到一组恰当的映射关系。我们可以认为所有输入态构成的态空间与所有输出态构成的态空间,存在一种规律性的映射,只是我们暂时不知道这种映射关系的具体内容。而神经网络所做的,就是通过已知的输入态与输出态,尽可能找出这种映射关系。而为了找出这种可能非常复杂的映射关系,我们需要一个有足够强大表达能力的工具,这种工具就是多层神经网络——这就好比我们在大学里都被其折磨过的泰勒展开与傅里叶分解,为了得到越来越复杂的函数,泰勒展开与傅里叶分解的级数就要越来越多,当我们具有无穷多级分解的时候,理论上就可以用来模拟任意函数。
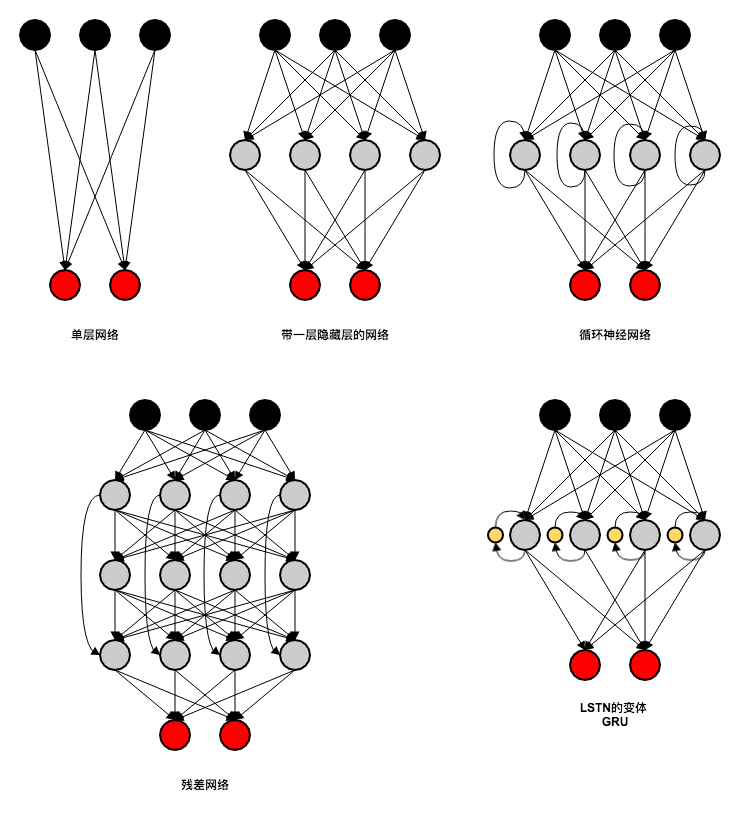
在这个基础上,人们又对网络结构进行了各种优化,从而针对各种不同的问题发展出了各种不同的人工神经网络。
比如,我们在输出和输出之间插入多层外界不可见的节点,而且每层节点只能和上一层节点相连,那就构成了多层神经网络,量大一点就是深度学习网络。
而后,我们认为每一层节点并不与上一层的每一个节点相连,而是之和具有相邻位置关系的节点相连,那么这就是局部化。
卷积之后,我们还认为连接的增益权值在每一个卷积中都是相同的,也就是只有点与点的相对位置能决定增益权值,而不是每个点都有自己的增益权值,那么这就是卷积。
接着我们还觉得应该只保留重要信息而去除次要信息,这就有了池化,类似 PS 里的一种滤镜。到这里就有了完整的卷积神经网络 CNN(Convolutional Neural Network)模型。
再接着,我们觉得输出不单单是输入的函数,还是历史记忆的函数,所以每一层的输入都应该包含自身上一次的输出,这样就有了循环神经网络 RNN(Reccurent Neural Network)。
接着我们发现 RNN 对短期记忆敏感,对长期记忆不敏感,于是就给网络引入了长期记忆,形成长短期记忆网络 LSTM(Long Short Term Memory Network)。
在接着我们发现这样的网络对线性序列挺管用,但对于复杂的树状或者网状逻辑结构的处理能力不强,于是就有了递归神经网络 RNN(Recursive Neural Network)。
而为了拥有更强的表达力,我们就要有更深的网络,可更深的网络训练起来又有各种问题,比如下降梯度的消失或者爆炸,为了解决这个问题就有人提出把不同深度的网络结合起来,这就有了残差网络 ResNet 。
我们用一个网络来识别数据,另一个网络来专门生成混淆数据进行干扰,这两个网络一起训练,最后达到双方最优的平衡态,这种自己和自己博弈以达到最优的方案,就有了生成对抗网络 GAN。
 神经网络示意图
神经网络示意图
事实上,随着问题的越来越复杂,我们总能发展出越来越多的网络结构模型,来应对日益复杂的局面,因此人工神经网络的发展远没有因为 AlphaGo Zero 对人类的碾压而结束。
因此,整个人工神经网络行业可以认为是在一个高速进化中的行业,神经网络模型作为一个物种,它所面临的生存压力就是被人类所抛弃不再使用。这么一想突然就感觉这个世界充满了残酷啊。
3. 从零到一
AlphaGo 家族已经演化到了四代目。
一代目AlphaGo Fan 以5:0的成绩击败了欧洲围棋冠军樊辉,二代目 AlphaGo Lee 以4:1的乘积击败了18次世界冠军李世石,而后璀璨的三代目 AlphaGo Master 先是在网上60:0横扫中日韩最顶尖高手,又以3:0碾压当今人类世界第一人柯洁。
而这位四代目,从什么都不知道只知道围棋规则的空白状态下,闭关三日后以100:0的惊艳战绩碾压二代目,18天后又以89:11的悬殊比分狠狠鄙视了三代目,并在总共闭关40天后成为 AlphaGo 家族中的当世第一狗。
而能做到这一切,对归功于更加优化的人工神经网络。
让我们回想一下人们自己是如何下棋的。
- 预估有哪些位置可以下棋
- 对可能的落子位置,思考对手的可能应对和自己的应对
- 根据可能的局面进行评估
- 对能想到的落子位置都进行一下上面的评估,然后选择最优的位置
其中,人类的经验在第一和第三步中发挥了重要的作用,而与具体对手的交战经验、了解程度以及过往个人的下棋经验以及能预估的步数脑力,则决定了第二步,预判的脑力也决定了第四不。
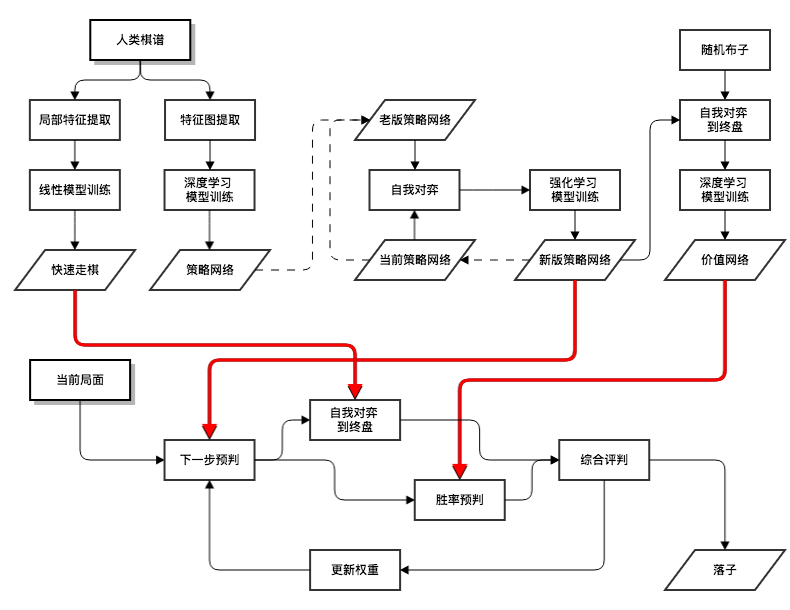
同样的过程在 AlphaGo 的下棋过程中也有体现,它的核心可以认为由四部分组成:
- 决策网络
- 快速走棋
- 价值网络
- 蒙特卡洛树搜索
 AlphaGo训练与下棋流程
AlphaGo训练与下棋流程
决策网络通过学习人类的棋谱来训练,此后又通过海量的自我对弈来不断提升,其主要功能是根据当前局面来给出下一步应该走哪里的预判,给出一系列落子选项。
而快速走棋则是通过随机走子到终盘若干次,来估算出每一个落子位置的胜率,这一步之所以用随机走子是因为计算量大耗时厉害。
价值网络是另一个神经网络,它可以根据局面的落子分布来估算每个位置的胜率,通过不断的自我对弈来训练获取。
最后将第二步与第三步估算出的胜率做一个平均,作为每个预期落子位置的胜率,交给蒙特卡洛树搜索进行最终的决策剪枝,给出最优的落子选择。
这个过程是不是和人下棋的过程很像?
其中,决策网络和价值网络分别给出了对于应该下哪里和局面胜率的估算,快速走棋则和蒙特卡洛树搜索则棋道了估算自己和对手应对并进行决策的作用。
而,决策网络的训练依赖于一开始的人类棋谱,从而是建立在人类数千年围棋经验之上的,而此后的决策网络与价值网络则完全来源于自我对弈。
但,至少最开始的围棋经验,还是建立在人类经验之上——网上数十万的人类高手对弈。
到了四代目 AlphaGo Zero,情况就发生了改变。
在 AlphaGo Zero 中,决策网络和价值网络合二为一,而且去掉了快速走棋的过程。
也就是说,在 AlphaGo Zero 中,我们只用一个基于残差网络的神经网络来做落子位置的预判和局面胜率的估算,然后通过蒙特卡洛树搜索来选择最优解,且整个神经网络的训练完全来源于狗自己和自己的对弈,并不需要人类之前任何的围棋经验。
这大概可以说是 AlphaGo Zero 最大的突破吧。
有趣的是,在前几年 DeepMind 以及 Facebook 的 DarkForest 都试过不引入快速走棋而只使用价值网络这样的神经网络来做预判,但当时的效果都不是特别理想。
由此可见,这次 AlphaGo Zero 的改变并不仅仅是将决策网络和价值网络融合,而是更加深入地优化了价值网络的整个结构。
而,对普通大众以及业内研究者来说,最优价值也是最有意思的,应该就是这次 AlphaGo 真的是从零开始学习围棋,且完全不依赖于人类的经验——实现了从 Zero 到 One 的突破。
4. 从一到零
人工神经网络的本质,就是找出输入与输出之间的内在联系与规律,从而利用找到的规律来对未来的输入提供最符合实际的输出。
说白了,就是找规律。
人类的学习过程也是一个找规律的过程,我们在学校中不断学习数学物理化学,语文英语历史,本质上就是在这些课程中掌握各个学科各个领域的基本内在规律。
我们通过不断地写作以及得到来自老师的所写内容的评价,来不断调整自己的写作技巧,从而当未来再有一个写作目标的时候,我们就知道如何能更好地写出一篇让人满意的文章。
这就是一个学习规律并使用规律的过程。
就这点来说,人工神经网络所做的就是这么一件事。
因此,人工神经网络自然也有一个有没有老师知道的问题。
这就是监督学习和无监督学习。
用更加技术的话来说,如果我们给出的数据集带有相关的标签或者评价数据,那么我们就可以利用这些已知的结果来告诉神经网络它的学习结果到底在多大程度上是好的,与真正的正确结果有多大的偏差,这在网络中以输出端的误差值来衡量,而整个网络的学习过程就是通过不断地调节节点之间连接的增益权值来改善输出,使得误差值降到最小。
而一旦达到了最小误差,我们就可以认为已经学到了一定程度了,也即我们找到了可以有效描述输出与输入之间相关性的函数。
而无监督学习,则不包括这类对结果的评价,网络只能自己来判断到底有没有学到位——当然,在围棋中规则和胜负判定本身也可以被看做是一种监督信号,所以也不能说是彻彻底底的无监督学习。
这点恰恰就是围棋类规则明确、结果可明确判断的行为的最大优点:对于最终的输出结果的好坏程度,并不需要人为因素的介入。
也就是说,当我们掌握了关于围棋规则的全部知识,以及判断胜负的明确规则之后,整个环节其实根本不需要人类的参与。
那么,为什么之前的 AlphaGo 等各类围棋程序都需要人类的经验来训练网络呢?
这里最根本的问题就在于,虽然理论上整个过程只需要规则不需要人,但实际操作的时候要构造出一个可以有效自我学习自我博弈的神经网络是非常困难的,并不是就让他自己学着就能学好的。
虽然这种自我学习的想法并不是新概念,很久以前就已经有了,但这次成功地运用很显然会让这一技术重新焕发新的生命力。
我们可以想象,未来会有越来越多领域,被不需要人参与其中的人工神经网络所占领。
人在历史长河中所积累下来的东西,很可能不再被机器所重视。
那么,是这样的么?
5. 深井有冰
AlphaGo Zero 的整个学习过程中都不需要人的参与,且最后能战胜所有的人类,并发现了人类很多习以为常的定式都可以被打破,这点比自我学习与更优秀的神经网络更能引起大家的兴趣。
因此就引出了一个非常让人好奇的问题:
人类的经验到底在多大程度上是有效的?
人类之所以强大,除了个体智力之外,一个很重要的原因就是个体之间通过交流将经验与他人分享,从而使得经验在整个群体中被不断地保存、延续和进化。而这些经验又反过来帮助个体的人类提升自我,获得更强大的能力。
因此,假如有一天我们发现我们的经验是错误的,那么带来的震撼显然是非常巨大的。
那么,人的经验是否就一定是正确的呢?答案显然是否定的。
毕达哥拉斯及其信徒相信一切数都是有理数,因为有理数符合当时的普遍哲学理念(毕达哥拉斯的万物皆数),因此当他的弟子希伯索斯发现边长为有理数的正方形的对角边不能表达为一个有理数时,毕达哥拉斯恐慌了。
经验在真理面前受到了挑战,而结果我们都知道,希伯索斯被毕达哥拉斯囚禁并最终被丢进了海里。
哥白尼发现了太阳不是绕着地球转的,下场则是火刑柱。
以太说曾经也被认为是坚不可摧的铁律,最后在光速不变带来的相对论观下被摧毁,所幸这事发生在现代并没有人为此付出生命。
我们的经验,从本质上说是一种路径依赖的具有贝叶斯统计所赋予的正确性的产物,即经验的描述在过往的历史中都给出了符合实际的结果,所以我们持续不断地相信它是正确的。
这种相信带来的一个结果,就是当出现与经验不符的样例时,人们往往不会选择怀疑经验,而是怀疑样例本身是否出了问题。
这么做当然有其积极的一面,即只有当与经验不符的程度达到一定的时候,我们才会更新我们的经验,这样避免了经验的不稳定性。
但也有消极的一面,那就是在那些不好做出明确判断的领域,尤其是非自然科学领域,往往就会形成主流与非主流这样的派系之别,从而影响正常的发展。
以围棋来说,我们都知道围棋中有很多定式,这就是当某个局面出现的时候,按照这个定式下棋在以往的经验中往往可以占据更多的优势。
但我们又都知道围棋中几乎不可能有两局棋出现完全一样的局面,那么这样的经验到底在多大程度上有效呢?
这就是 AlphaGo 系列所带来的问题——定式也许在局部可以带来优势,但从整体来看,不按照定式来落子也许可以换来更大的优势,所以 AlphaGo 的棋谱中出现了大量的这类脱先。
在金庸的《天龙八部》中,虚竹之所以能破解珍珑棋局,就在于他完全不知道怎么下围棋,闭着眼睛随便一落子,恰好走的是所有围棋高手都认为是最不合理最吃亏的一步,但就是这一步在挤死白子的同时,打开了更大的空间,从而使得珍珑棋局被破。
也就是说,过往的经验告诉我们是死路的时候,恰恰在其中蕴藏了生路。
在 AlphaGo 系列中也是这样,我们以往的经验所圈定的范围在计算机强大的算力面前局限性暴露无遗,计算机在更大的搜索空间中找到了突破这种局限性的方法。
我们可以把问题抽象成一个巨大的状态空间,然后每个解决方案都是这个状态空间中的一个点,解决的好坏程度是这个点对一个的一个深度。那么理论上解决一个问题最好的方案,就是整个状态空间中最深的那个点。
而,人们积累经验的过程,就是在这个状态空间中,根据现在所处的点,找寻周围有没有更深的点,然后转移过去。
而一个好的经验,往往就是在一个局部最深的点,也就是状态空间中的一个极深点。但极深点未必是最深点。
对于状态空间非常巨大的情况,人工神经网络当然也没有办法遍历整个状态空间来找到真正的最深点,但凭借着强大的计算力,它可以找寻更大更广阔的范围,从而可以找到比人类的经验更好的解决方案。
于是,下面的问题就是人是否能接受机器给出的更优方案了。
让我们来做一个思想实验,假如说现在人工智能已经可以自己去做物理实验了(当然,在一定程度上,这事现在已经做到了),然后根据实验结果来自己建立数学理论,那么它们最后得到的物理理论在多大程度上会和人类现在的物理理论一样呢?
更重要的是,当我们发现人工智能得到的理论和我们的理论不一样的时候,我们会如何选择?
同样的,假如人工智能已经可以运用到股票市场、期货市场等金融市场中,那么他们能得到什么样的关于金融市场的经济学理论呢?我们又是否会照着人工智能提出的理论来理解金融市场呢?
如果人工智能运用到对社会的分析上呢?人工智能分析出为了解决全社会就业率低下、福利低下以及社会大范围不平等的问题的解决之道,是一个人类经验中不存在的方案,那么人们是否会采纳人工智能的建议呢?
到最后,如果有人把人工智能运用到伦理学上呢?
比如说,对于著名的火车疑难,即假定一辆火车正开过来,你在变轨器旁,如果不变轨,那么火车会压死一群人,而如果你变轨,那么火车就会压死另一群人,那么此时你是变轨还是不变轨?
这个问题在人类世界中已经是一个非常困难的论题了,其核心在于“不作为”本身也是一种“作为”,以及如何衡量生命的轻重这一不可能有标准答案的问题。
那么,如果某一天人工智能通过对人类行为的分析与学习、对人类社会发展的目标的研究与分析,然后遇到了这样一个问题的时候,它的选择我们会如何看待?
当人们不具备相关经验,或者说人工智能的选择超越了人类经验范畴的时候,人们会如何选择?
在围棋的世界中,我们可以说 AlphaGo Zero 为人类打开了更加广阔的围棋世界的大门,人们可以欢呼雀跃地迎接更多新的思想新的棋路,但当这个问题离开了黑白相间的棋盘而到了现实世界的时候,人们是否还会这么欣然接受呢?
未来很有可能人工智能会给出人们无法理解,无法接受,也完全不在人类的经验范畴内的解决方案,那么人类到底会如何看待这些方案呢?
6. 模仿游戏何处去?
无须人类参与的自我学习的人工智能系统的出现,无疑给了我们更多有趣的话题,特别是哲学爱好者,完全可以讨论知识论的天赋论与经验论到底哪个更有道理这样的话题。
还比如,人们可以继续争论到底怎么定义灵魂与智能,才能让人一直享有比人工智能更高级的存在的荣誉。
而,无论人们如何争论,对于真正研究人工智能与神经网络的人来说,路还是要继续走。我们还会有更多的人工神经网络被研究出来,有些会更多地从生物神经网络中吸取灵感,比如人工神经网络的受限玻尔兹曼机模型与多层神经网络的反向传播的提出者 Hinton,就提出与人脑神经结构更相似的 Capsule 模型。
我们对自然的模仿在我们真正地超越自然之前,是不会停歇的。
那么,人工智能是否真的会超越其所模仿的人类呢?
倒也未必——智能的方向可以有很多个,人不过是其中之一,朝着另一个方向而去的智能,又何必一定要绕过来超越一下人类呢?
没这个必要嘛。
通过本协议,您可以分享并修改本文内容,只要你遵守以下授权条款规定:姓名标示 、非商业性、相同方式分享。
具体内容请查阅上述协议声明。
本文禁止一切纸媒,即印刷于纸张之上的一切组织,包括但不限于转载、摘编的任何应用和衍生。网络平台如需转载必须与本人联系确认。













网友评论