源文件放在github,随着理解的深入,不断更新,如有谬误之处,欢迎指正。原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowledge/md/sort-shuffle.md
正如你所知,spark实现了多种shuffle方法,通过 spark.shuffle.manager来确定。暂时总共有三种:hash shuffle、sort shuffle和tungsten-sort shuffle,从1.2.0开始默认为sort shuffle。本节主要介绍sort shuffle。
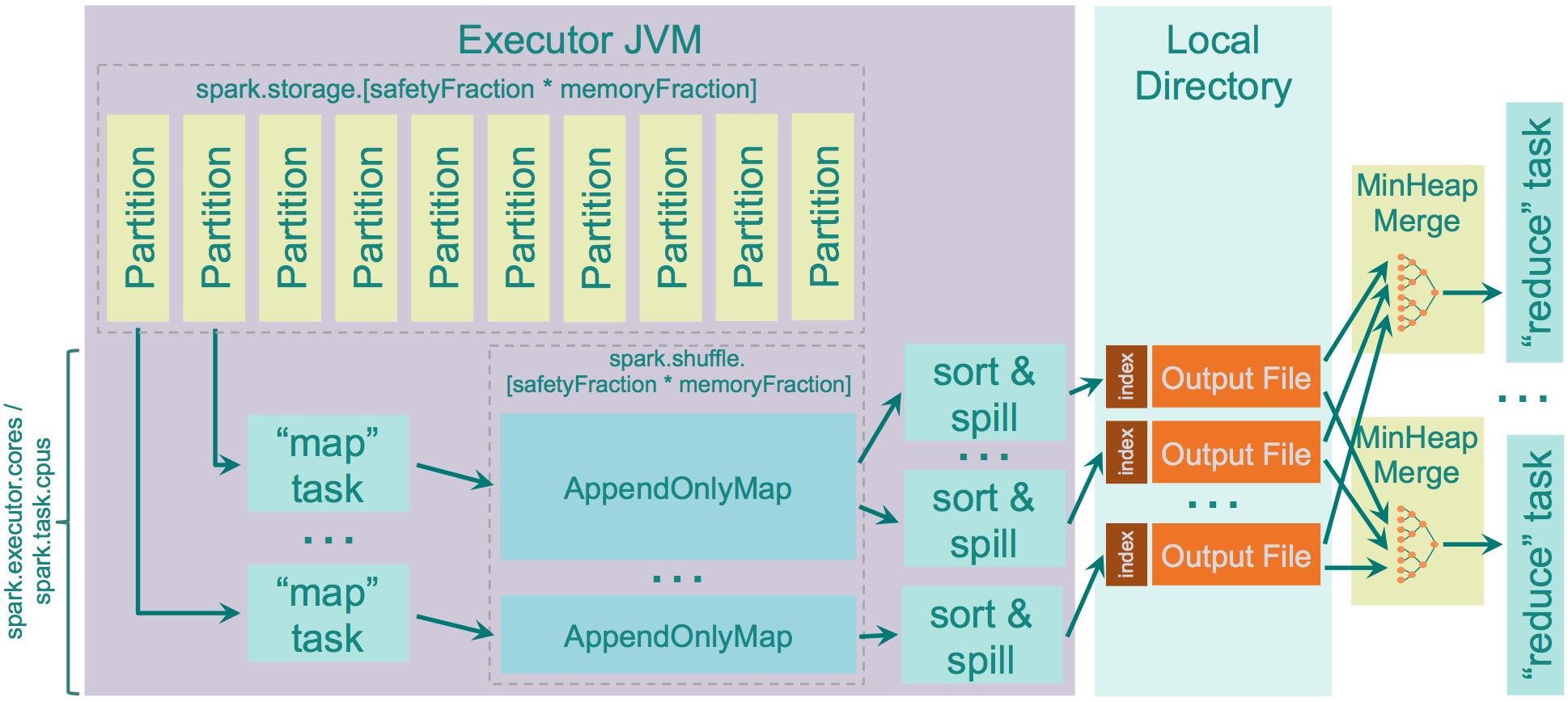
从1.2.0开始默认为sort shuffle(spark.shuffle.manager = sort),实现逻辑类似于Hadoop MapReduce,Hash Shuffle每一个reducers产生一个文件,但是Sort Shuffle只是产生一个按照reducer id排序可索引的文件,这样,只需获取有关文件中的相关数据块的位置信息,并fseek就可以读取指定reducer的数据。但对于rueducer数比较少的情况,Hash Shuffle明显要比Sort Shuffle快,因此Sort Shuffle有个“fallback”计划,对于reducers数少于 “spark.shuffle.sort.bypassMergeThreshold” (200 by default),我们使用fallback计划,hashing相关数据到分开的文件,然后合并这些文件为一个,具体实现为BypassMergeSortShuffleWriter。
 image
image
在map进行排序,在reduce端应用Timsort[1]进行合并。map端是否容许spill,通过spark.shuffle.spill来设置,默认是true。设置为false,如果没有足够的内存来存储map的输出,那么就会导致OOM错误,因此要慎用。
用于存储map输出的内存为:“JVM Heap Size” \* spark.shuffle.memoryFraction \* spark.shuffle.safetyFraction,默认为“JVM Heap Size” \* 0.2 \* 0.8 = “JVM Heap Size” \* 0.16。如果你在同一个执行程序中运行多个线程(设定spark.executor.cores/ spark.task.cpus超过1),每个map任务存储的空间为“JVM Heap Size” * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction / spark.executor.cores * spark.task.cpus, 默认2个cores,那么为0.08 * “JVM Heap Size”。
spark使用AppendOnlyMap存储map输出的数据,利用开源hash函数MurmurHash3和平方探测法把key和value保存在相同的array中。这种保存方法可以是spark进行combine。如果spill为true,会在spill前sort。
Sort Shuffle内存的源码级别更详细说明可以参考[4],读写过程可以参考[5]
优点
- map创建文件量较少
- 少量的IO随机操作,大部分是顺序读写
缺点
- 要比Hash Shuffle要慢,需要自己通过
spark.shuffle.sort.bypassMergeThreshold来设置合适的值。 - 如果使用SSD盘存储shuffle数据,那么Hash Shuffle可能更合适。
参考
[1]Timsort原理介绍
[2]形式化方法的逆袭——如何找出Timsort算法和玉兔月球车中的Bug?
[3]Spark Architecture: Shuffle








网友评论