源文件放在github,随着理解的深入,不断更新,如有谬误之处,欢迎指正。原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowledge/md/spark_streaming使用kafka保证数据零丢失.md
spark streaming从1.2开始提供了数据的零丢失,想享受这个特性,需要满足如下条件:
1.数据输入需要可靠的sources和可靠的receivers
2.应用metadata必须通过应用driver checkpoint
3.WAL(write ahead log)
可靠的sources和receivers
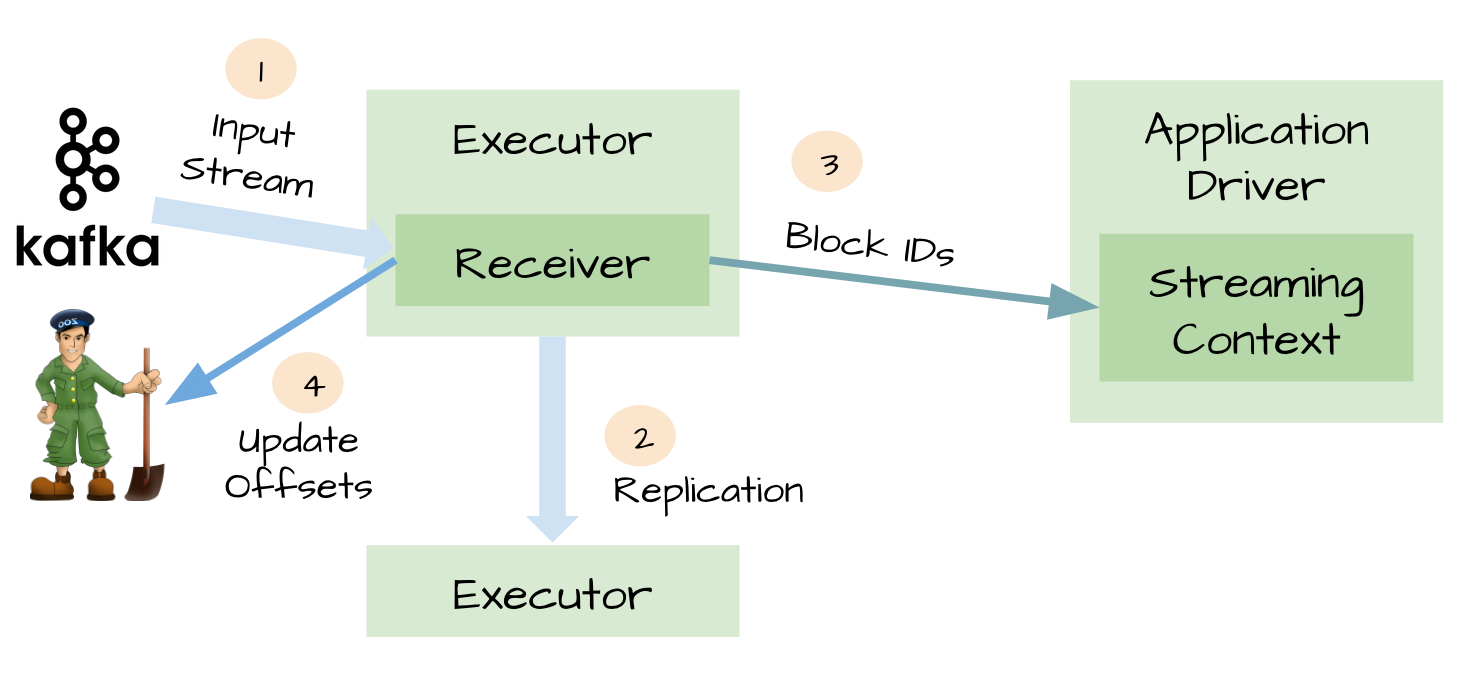
spark streaming可以通过多种方式作为数据sources(包括kafka),输入数据通过receivers接收,通过replication存储于spark中(为了faultolerance,默认复制到两个spark executors),如果数据复制完成,receivers可以知道(例如kafka中更新offsets到zookeeper中)。这样当receivers在接收数据过程中crash掉,不会有数据丢失,receivers没有复制的数据,当receiver恢复后重新接收。
 image
image
metadata checkpoint
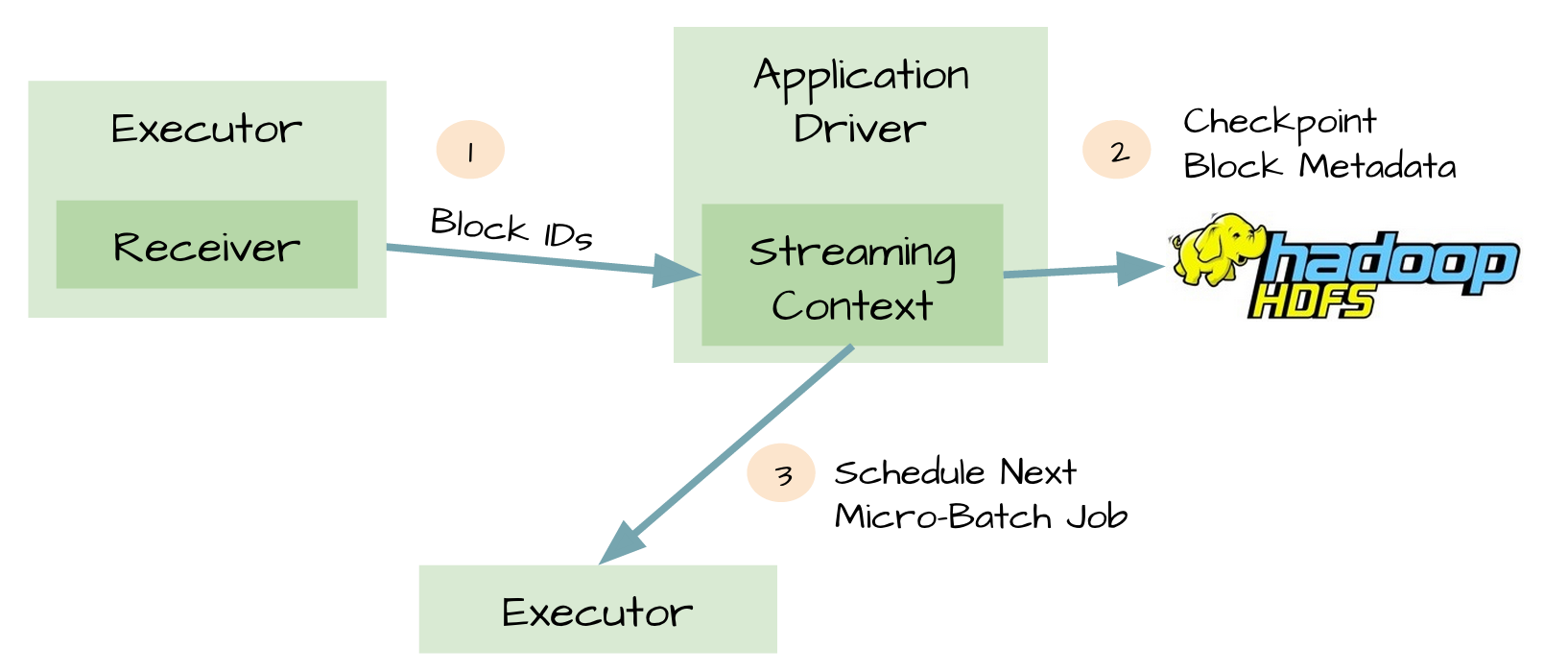
可靠的sources和receivers,可以使数据在receivers失败后恢复,然而在driver失败后恢复是比较复杂的,一种方法是通过checkpoint metadata到HDFS或者S3。metadata包括:
- configuration
- code
-
一些排队等待处理但没有完成的RDD(仅仅是metadata,而不是data)
 image
image
这样当driver失败时,可以通过metadata checkpoint,重构应用程序并知道执行到那个地方。
数据可能丢失的场景
可靠的sources和receivers,以及metadata checkpoint也不可以保证数据的不丢失,例如:
- 两个executor得到计算数据,并保存在他们的内存中
- receivers知道数据已经输入
- executors开始计算数据
- driver突然失败
- driver失败,那么executors都会被kill掉
- 因为executor被kill掉,那么他们内存中得数据都会丢失,但是这些数据不再被处理
- executor中的数据不可恢复
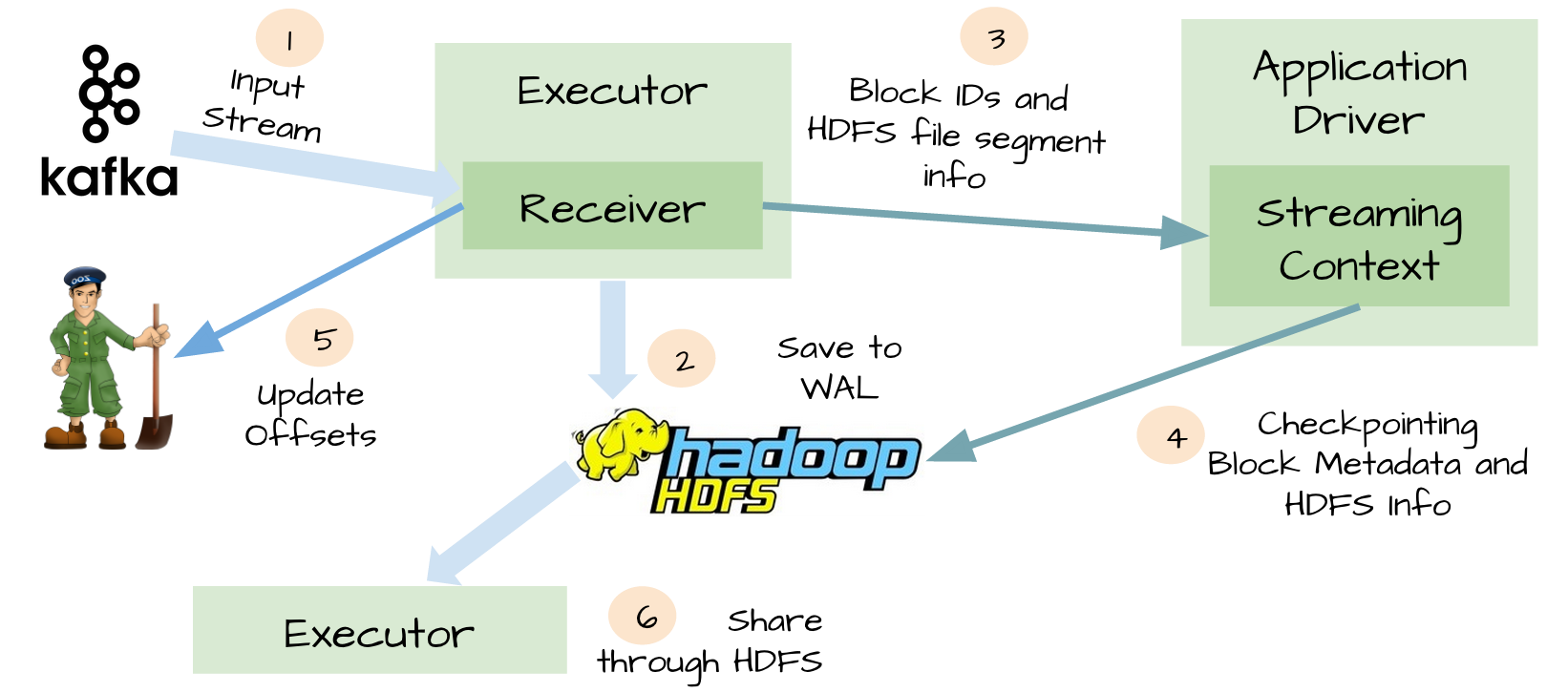
WAL
为了避免上面情景的出现,spark streaming 1.2引入了WAL。所有接收的数据通过receivers写入HDFS或者S3中checkpoint目录,这样当driver失败后,executor中数据丢失后,可以通过checkpoint恢复。
 image
image
At-Least-Once
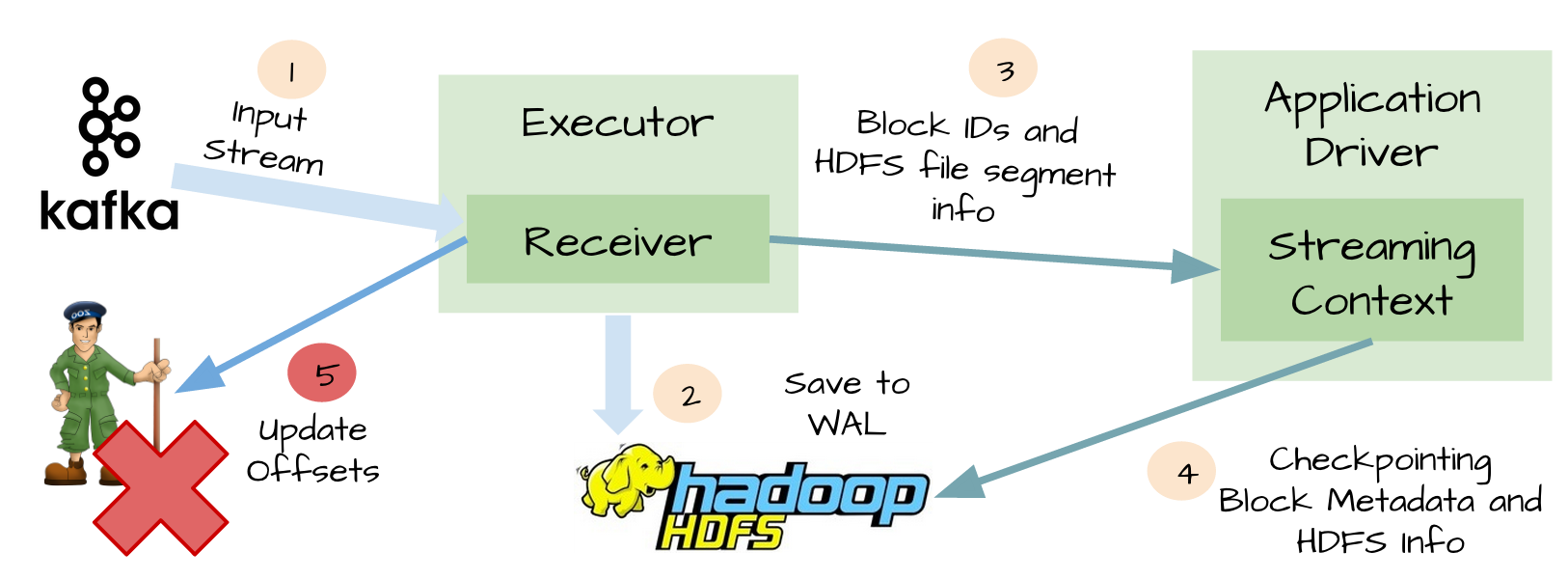
尽管WAL可以保证数据零丢失,但是不能保证exactly-once,例如下面场景:
-
Receivers接收完数据并保存到HDFS或S3
-
在更新offset前,receivers失败了
 image
image
-
Spark Streaming以为数据接收成功,但是Kafka以为数据没有接收成功,因为offset没有更新到zookeeper
-
随后receiver恢复了
-
从WAL可以读取的数据重新消费一次,因为使用的kafka High-Level消费API,从zookeeper中保存的offsets开始消费
WAL的缺点
通过上面描述,WAL有两个缺点:
- 降低了receivers的性能,因为数据还要存储到HDFS等分布式文件系统
- 对于一些resources,可能存在重复的数据,比如Kafka,在Kafka中存在一份数据,在Spark Streaming也存在一份(以WAL的形式存储在hadoop API兼容的文件系统中)
Kafka direct API
为了WAL的性能损失和exactly-once,spark streaming1.3中使用Kafka direct API。非常巧妙,Spark driver计算下个batch的offsets,指导executor消费对应的topics和partitions。消费Kafka消息,就像消费文件系统文件一样。
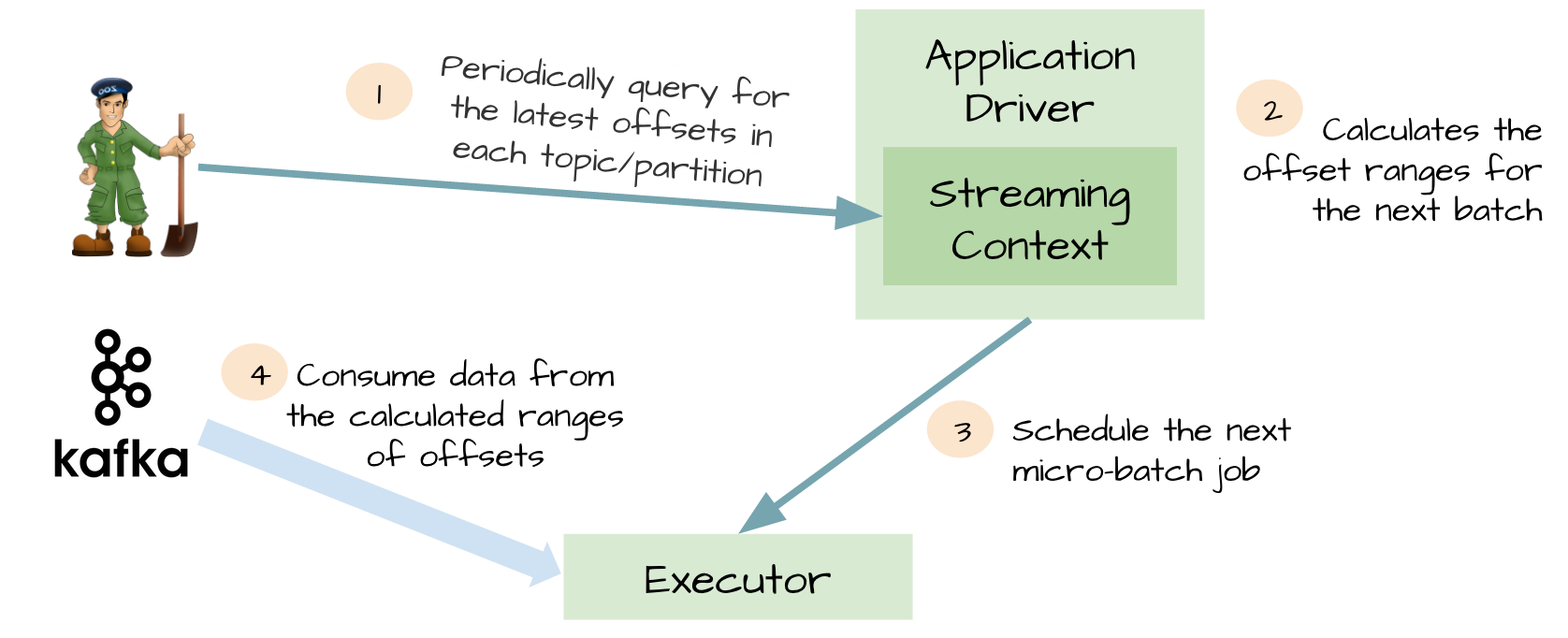 image
image
1.不再需要kafka receivers,executor直接通过Kafka API消费数据
2.WAL不再需要,如果从失败恢复,可以重新消费
3.exactly-once得到了保证,不会再从WAL中重复读取数据
总结
主要说的是spark streaming通过各种方式来保证数据不丢失,并保证exactly-once,每个版本都是spark streaming越来越稳定,越来越向生产环境使用发展。
参考
spark-streaming
Recent Evolution of Zero Data Loss Guarantee in Spark Streaming With Kafka









网友评论