原文链接https://mxnet.readthedocs.org/en/latest/developer-guide/note_memory.html
如需转载请注明译者。
压榨深度学习的内存消耗翻译:吴岸城
深度学习的重要主题是关于训练更深度和更大型的网络。最近几年,硬件普遍升级的相当迅速,这种巨型的深度网络怪物常常对GPU RAMS有更多的需求。如果同样的网络模型我们能使用更少的内存意味着我们每批输入数据可以输入更多,也能增加GPU的利用率。
这篇文章讨论了深度神经网络中如何对内存分配优化,并且提供了一些候选的解决方案。这篇文章所讨论的解决方案并不意味着完结,但我们想其中的例子能对大部分情况有用。
计算图谱(图计算)
我们将从计算图谱开始讨论,这些篇幅的后面部分有一些工具可以帮助我们。图计算描述(数据流)在深度网络中的运算依赖关系。图里面的运算执行可以是细粒度也可以是粗粒度。以下给出计算图谱的两个例子。
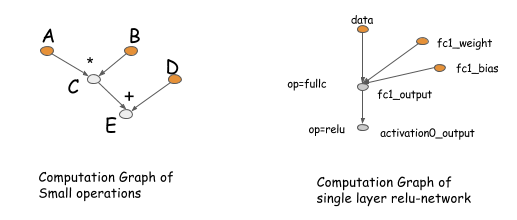
计算图谱的这些概念在如Theano,CGT的包中有深入体现。事实上,它们也隐含的存在于大多数网络结构的库中。这些库的主要区别是他们如何做梯度计算。这里有两种方法,在同一个图里用BP算法,或者用一个显式的后向通道(explicit backward path)计算所需梯度。
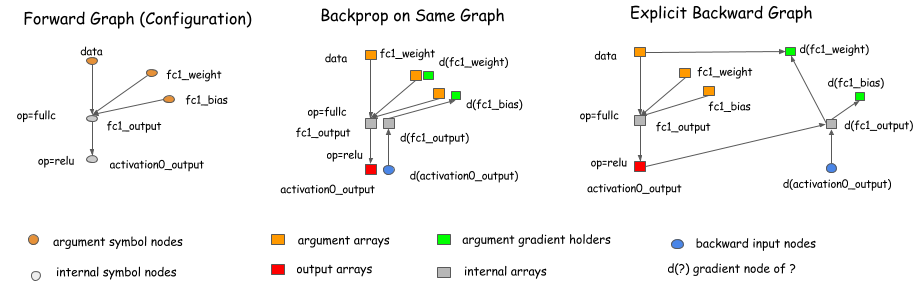
像caffe,cxxnet, torch这些库在同一个图中使用了BP算法。而像Theano,CGT这些库使用了显式后向通道逼近算法。这篇文章中我们采用了显式的后向通道,因为该方法在轮流的优化中可以带来更多的优势。
然而,我们要强调的是,选择显式后向通道法的执行并不限制我们使用Theano,
CGT库的范围。我们也可以将显式后向通道法用在基于层(前向,后向在一起)的库做梯度计算。下面的图表显示如何做到的。基本上,我们可以引出一个后向节点到图的前向节点,并且在后向的操作中可以调用layer.backward。
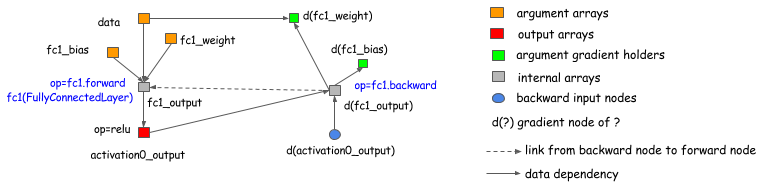
这次讨论中提供几乎所有已存在的深度学习库(这些库有些区别,比如高阶分化,这些不在本篇文章中讨论)
待更新。。












网友评论