排序算法总结
排序算法
平均时间复杂度
冒泡排序
O(n2)
选择排序
O(n2)
插入排序
O(n2)
希尔排序
O(n1.5)
快速排序
O(N*logN)
归并排序
O(N*logN)
堆排序
O(N*logN)
基数排序
O(d(n+r))
一. 冒泡排序(BubbleSort)
基本思想:两个数比较大小,较大的数下沉,较小的数冒起来。
过程:
比较相邻的两个数据,如果第二个数小,就交换位置。
从后向前两两比较,一直到比较最前两个数据。最终最小数被交换到起始的位置,这样第一个最小数的位置就排好了。
继续重复上述过程,依次将第2.3...n-1个最小数排好位置。
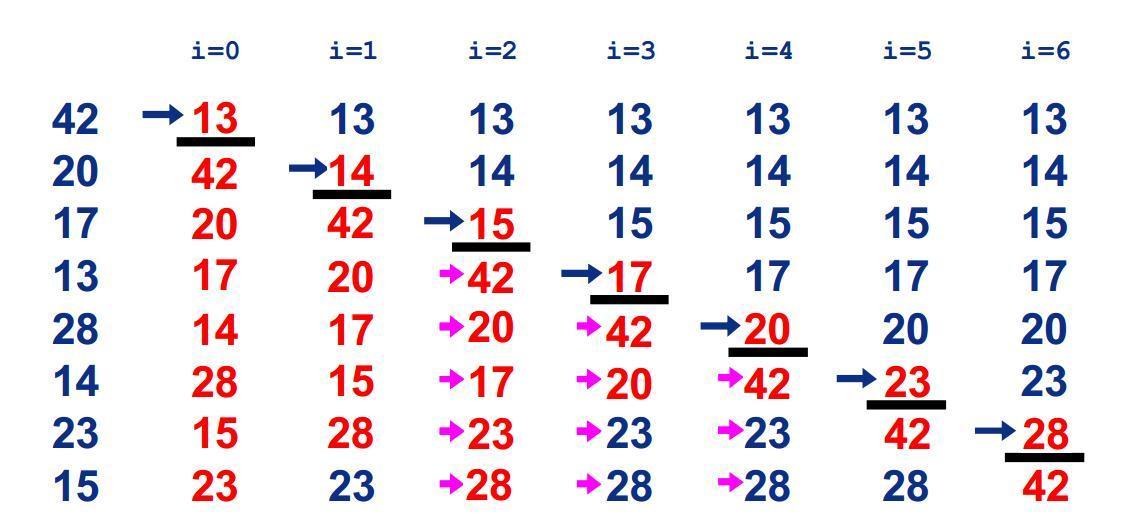 冒泡排序
冒泡排序
平均时间复杂度:O(n2)
python代码实现:
def bubble_sort(lists):
# 冒泡排序
count = len(lists)
for i in range(0, count):
for j in range(i + 1, count):
if lists[i] > lists[j]:
lists[i], lists[j] = lists[j], lists[i]
return lists
二. 选择排序(SelctionSort)
基本思想:第1趟,在待排序记录r1 ~ r[n]中选出最小的记录,将它与r1交换;第2趟,在待排序记录r2 ~ r[n]中选出最小的记录,将它与r2交换;以此类推,第i趟在待排序记录r[i] ~ r[n]中选出最小的记录,将它与r[i]交换,使有序序列不断增长直到全部排序完毕。
过程:
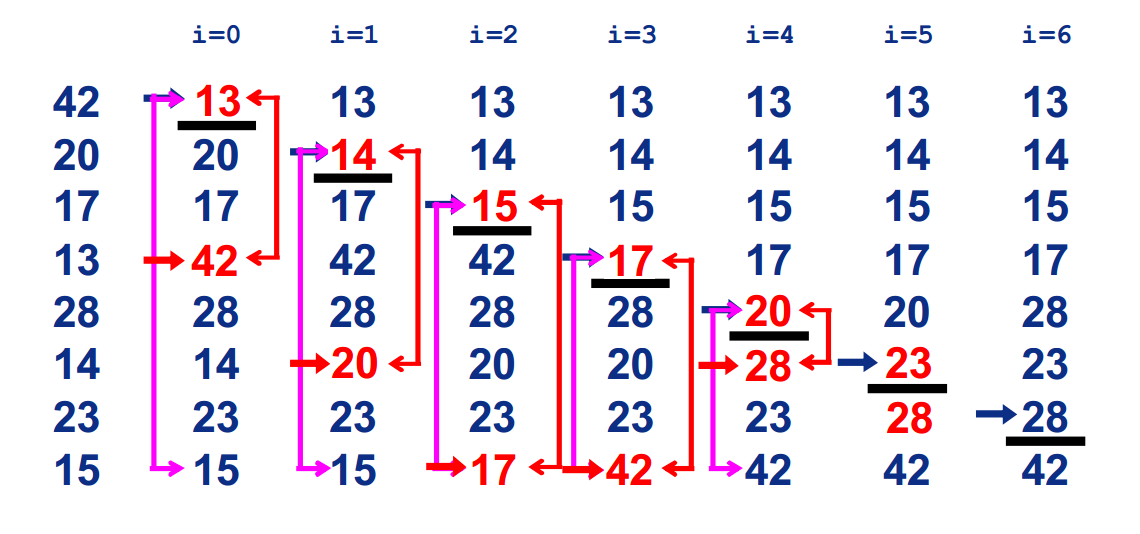
选择排序
平均时间复杂度:O(n2)
python代码实现:
def select_sort(lists):
# 选择排序
count = len(lists)
for i in range(0, count):
min = i
for j in range(i + 1, count):
if lists[min] > lists[j]:
min = j
lists[min], lists[i] = lists[i], lists[min]
return lists
三. 插入排序(Insertion Sort)
基本思想:在要排序的一组数中,假定前n-1个数已经排好序,现在将第n个数插到前面的有序数列中,使得这n个数也是排好顺序的。如此反复循环,直到全部排好顺序。
过程:
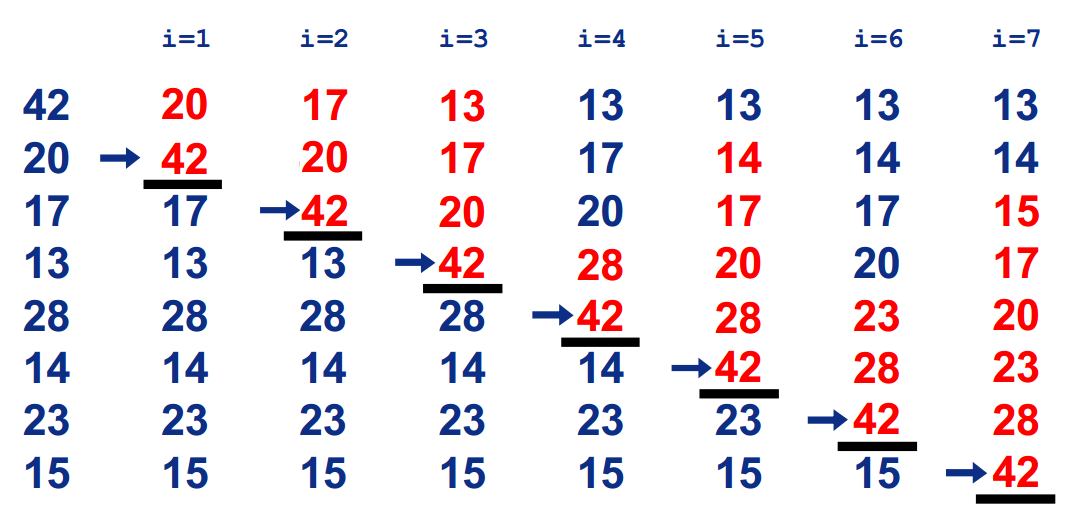
插入排序
相同的场景
平均时间复杂度:O(n2)
python代码实现:
# 插入排序
list1 = [42, 20, 17, 13, 28, 14, 23, 15]
def insert_sort(lists):
# 列表长度
count = len(lists)
for i in range(1, count): # 100 1-99 0-99
key = lists[i] # i指列表下表
j = i - 1
while j >= 0:
if lists[j] > key:
lists[j + 1] = lists[j]
lists[j] = key
j -= 1
return lists
print('插入排序结果:', insert_sort(list1))
四. 希尔排序(Shell Sort)
前言:数据序列1: 13-17-20-42-28 利用插入排序,13-17-20-28-42. Number of swap:1;数据序列2: 13-17-20-42-14 利用插入排序,13-14-17-20-42. Number of swap:3;如果数据序列基本有序,使用插入排序会更加高效。
基本思想:在要排序的一组数中,根据某一增量分为若干子序列,并对子序列分别进行插入排序。然后逐渐将增量减小,并重复上述过程。直至增量为1,此时数据序列基本有序,最后进行插入排序。
过程:
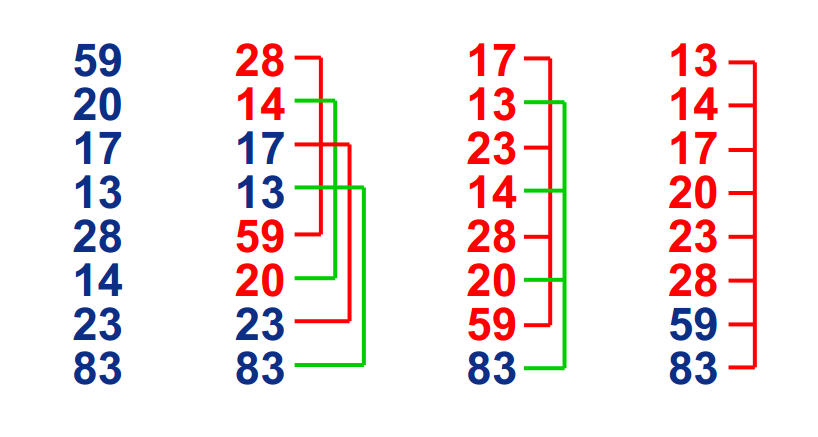
希尔排序
平均时间复杂度:
python代码实现:
list2 = [59, 20, 17, 13, 28, 14, 23, 83]
# 希尔排序
def shell_sort(lists):
count = len(lists)
# 增量缩减值 2倍
step = 2
# 初始增量值
group = int(count / step)
# print(group)
while group > 0:
for i in range(0, group):
j = i + group
while j < count:
k = j - group
key = lists[j]
while k >= 0:
if lists[k] > key:
lists[k + group] = lists[k]
lists[k] = key
k -= group
j += group
group = int(group / step)
return lists
print('希尔排序结果:', shell_sort(list2))
五. 快速排序(Quicksort)
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
基本思想:(分治)
先从数列中取出一个数作为key值;
将比这个数小的数全部放在它的左边,大于或等于它的数全部放在它的右边;
对左右两个小数列重复第二步,直至各区间只有1个数。
辅助理解:挖坑填数
平均时间复杂度:O(N*logN)
python代码实现:
def quick_sort(lists, left, right):
# 快速排序
if left >= right:
return lists
key = lists[left]
low = left
high = right
while left < right:
while left < right and lists[right] >= key:
right -= 1
lists[left] = lists[right]
while left < right and lists[left] <= key:
left += 1
lists[right] = lists[left]
lists[right] = key
quick_sort(lists, low, left - 1)
quick_sort(lists, left + 1, high)
return lists
六. 归并排序(Merge Sort)
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归并过程为:比较a[i]和a[j]的大小,若a[i]≤a[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1;否则将第二个有序表中的元素a[j]复制到r[k]中,并令j和k分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到r中从下标k到下标t的单元。归并排序的算法我们通常用递归实现,先把待排序区间[s,t]以中点二分,接着把左边子区间排序,再把右边子区间排序,最后把左区间和右区间用一次归并操作合并成有序的区间[s,t]。
平均时间复杂度:O(NlogN)归并排序的效率是比较高的,设数列长为N,将数列分开成小数列一共要logN步,每步都是一个合并有序数列的过程,时间复杂度可以记为O(N),故一共为O(N*logN)。
python代码实现:
def merge(left, right):
i, j = 0, 0
result = []
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result += left[i:]
result += right[j:]
return result
def merge_sort(lists):
# 归并排序
if len(lists) <= 1:
return lists
num = len(lists) / 2
left = merge_sort(lists[:num])
right = merge_sort(lists[num:])
return merge(left, right)
七. 堆排序(HeapSort)
基本思想:
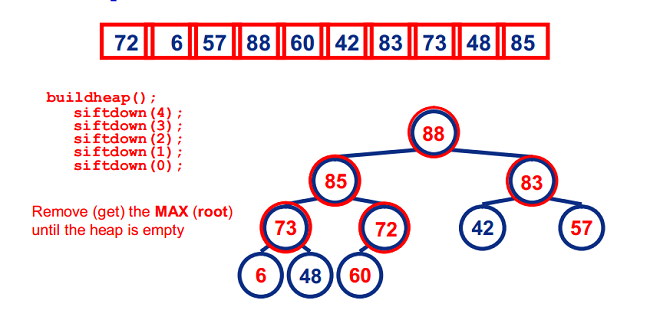 6660
6660
图示: (88,85,83,73,72,60,57,48,42,6)
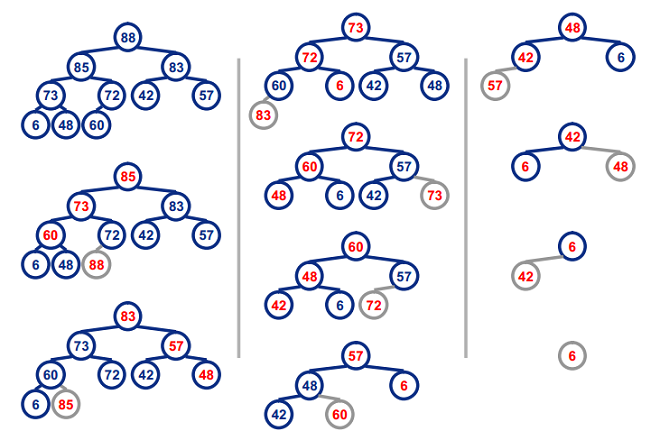 7770
7770
Heap Sort
平均时间复杂度:O(NlogN)由于每次重新恢复堆的时间复杂度为O(logN),共N - 1次重新恢复堆操作,再加上前面建立堆时N / 2次向下调整,每次调整时间复杂度也为O(logN)。二次操作时间相加还是O(N * logN)。
python代码实现:
def adjust_heap(lists, i, size):
lchild = 2 * i + 1
rchild = 2 * i + 2
max = i
if i < size / 2:
if lchild < size and lists[lchild] > lists[max]:
max = lchild
if rchild < size and lists[rchild] > lists[max]:
max = rchild
if max != i:
lists[max], lists[i] = lists[i], lists[max]
adjust_heap(lists, max, size)
def build_heap(lists, size):
for i in range(0, (size/2))[::-1]:
adjust_heap(lists, i, size)
def heap_sort(lists):
size = len(lists)
build_heap(lists, size)
for i in range(0, size)[::-1]:
lists[0], lists[i] = lists[i], lists[0]
adjust_heap(lists, 0, i)
八. 基数排序(RadixSort)
** BinSort **
基本思想:BinSort想法非常简单,首先创建数组A[MaxValue];然后将每个数放到相应的位置上(例如17放在下标17的数组位置);最后遍历数组,即为排序后的结果。
图示:
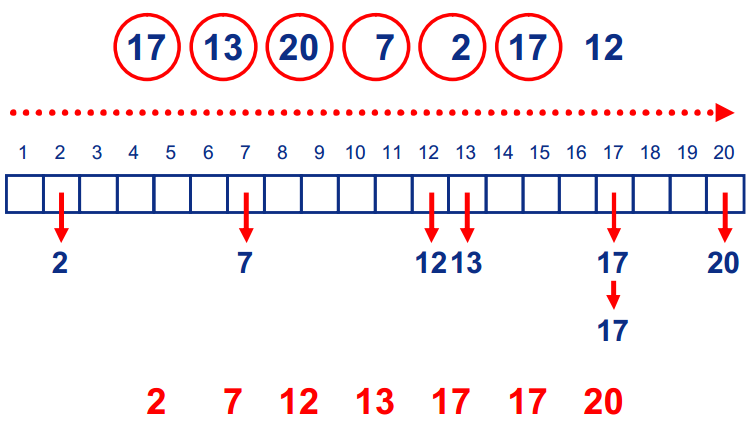
** BinSort **
问题: 当序列中存在较大值时,BinSort 的排序方法会浪费大量的空间开销。
** RadixSort **
基本思想: 基数排序是在BinSort的基础上,通过基数的限制来减少空间的开销。
过程:
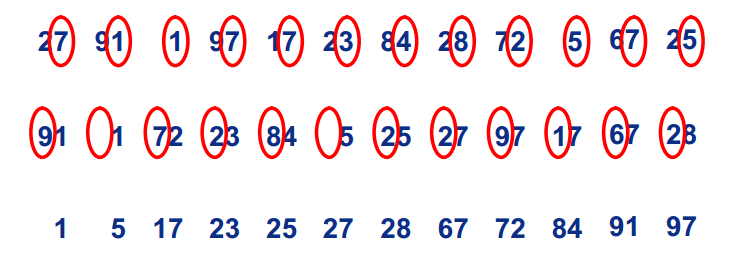 10101001
10101001
过程1
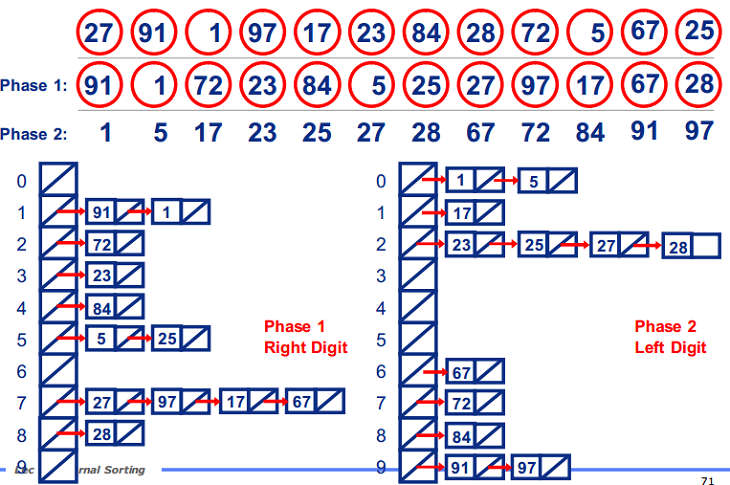 9990
9990
过程2
(1)首先确定基数为10,数组的长度也就是10.每个数34都会在这10个数中寻找自己的位置。(2)不同于BinSort会直接将数34放在数组的下标34处,基数排序是将34分开为3和4,第一轮排序根据最末位放在数组的下标4处,第二轮排序根据倒数第二位放在数组的下标3处,然后遍历数组即可。
python代码实现:
def adjust_heap(lists, i, size):
lchild = 2 * i + 1
rchild = 2 * i + 2
max = i
if i < size / 2:
if lchild < size and lists[lchild] > lists[max]:
max = lchild
if rchild < size and lists[rchild] > lists[max]:
max = rchild
if max != i:
lists[max], lists[i] = lists[i], lists[max]
adjust_heap(lists, max, size)
def build_heap(lists, size):
for i in range(0, (size/2))[::-1]:
adjust_heap(lists, i, size)
def heap_sort(lists):
size = len(lists)
build_heap(lists, size)
for i in range(0, size)[::-1]:
lists[0], lists[i] = lists[i], lists[0]
adjust_heap(lists, 0, i)










网友评论