介绍
什么是structure图? 如果你有看过群体遗传相关的文章,你对它肯定不会陌生。对那些还没有接触过的同学,那就直接上图吧:
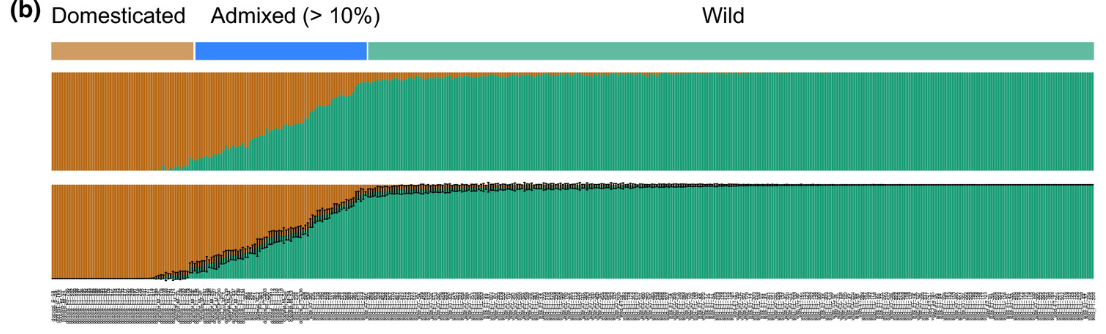
上图是选取于一个大麦群体遗传的研究。不同的颜色种类分别代表了种群的数目,橙色代表了驯化的大麦,绿色是野生的大麦。上下有两个图是,因为这个例子中选取了两种structure分析的方法:本别是(使用全部的SNPs还有随机抽取10组样本为1000的SNPs),两个结果几乎完全一致。下图黑色的“胡须”是分析结构产生的标准差。
Structure图,其实就是一款群体遗传分析软件——STRUCTURE生成的图。这个软件是由斯坦福大学Pritchard实验室开发,最早在2000年nature genetics上的文章被使用。
其目的也很简单,分析整个群体的结构。Structure图可以展示具体群体的亚群分类,告知该群体间是否有杂交,进而产生基因交流,已经每个个体混血的程度有多少?这些信息都是PCA图还有进化树无法提供的。
Structure图构建原理
- 获取样本基因型;即snp calling的结果,vcf file。
- 一般来说我们是不知道群体中十几包含了多少个亚群,我们一般把它设置为K。然后Structure软件就会使用贝叶斯算法,推算并模拟K分别在1~x的情况下,是如何分群,及每个个体血统分布情况。
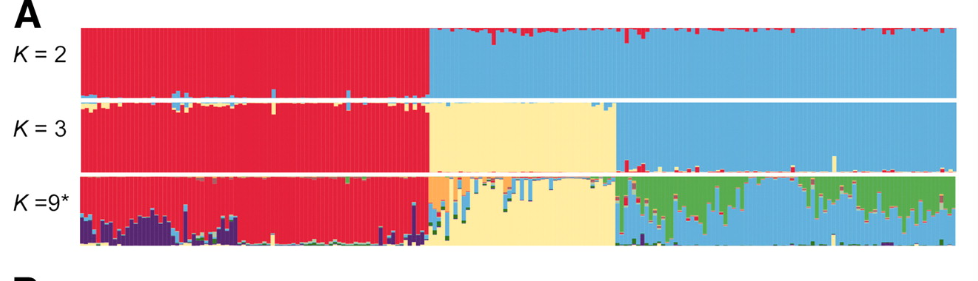
如下图你可以了解k=2,3,9的情况下,该物种是如何分群的,及每个个体的血统构成。例如K=3,有三种颜色,代表三个亚群。有一些个体,会掺杂两种颜色,证明这个个体具有杂合的血统,并且颜色的多少代表掺杂了对应祖先的比例。
但是问题来了如何决定那个K值所对应的图是对的?因为structure使用的是贝叶斯算法,每个K值模拟的结果都会产生一个最大似然值。软件中会以最大似然值对数的形式出现,该值越大,说明对应K模拟的结果越接近真实群体的情况。当K值不断增加,会出现一个饱和的最大似然值的点。该点对应的K值所生成的图就是最合适的模拟图。般随着K值升高,ln likelihood值也会不断升高,但会慢慢进入平台期。选择最优K值的目标是要找到那个拐点。
简单说来,就是要找的一个likelihood最大(越大越可靠)而且K值最小(亚群数最少)的模拟结果,往往这样的模拟对应的K值是最接近于群体的真实情况的。
Structure软件计算原理
Structure是与PCA、进化树相似的方法,就是利用分子标记的基因型信息对一组样本进行分类,分子标记可以是SNP、indel、SSR… …当然,对于重测序应用的最多的还是SNP。当然,structure本质上使用了与PCA、进化树完全不同的思路。进化树和PCA本质上都是计算样本序列间的差异程度,然后利用两两差异度聚类(进化树)或降维(PCA)来实现对样本的分类。
这个过程的逻辑如下:
1.亚群内符合哈温structure软件摒弃的以上的方法,先预设群体由若干亚群(k=x)构成,通过模拟算法找出在k=x的情况下,最合理的样本分类方法。最后再根据每次模拟的最大似然值,找出最适用这群体的K值。
这个过程的逻辑如下:
1.亚群内符合哈温平衡
那么,软件在如何确定样本的最优分类方法呢?其实基于一个假设:在各个亚群内部个体应该符合哈代-温伯格平衡,那么这个亚群内的基因频率分布应该可通过哈温平衡检验。例如,现在有40个个体的1个SNP位点的基因型,我预设亚群数k=2。我先随机将40个个体分成两份,然后检验是否符合哈温平衡。如果不符合,我继续调整分类策略,直到找到一种最优的分类方法:40个个体被分为了两份,每个亚群都由若干个体构成,每个亚群内部都最大程度地符合哈温平衡。
合哈代-温伯格平衡:(在理想状态下,各等位基因的频率和等位基因的基因型频率在遗传中是稳定不变的,即保持着基因平衡。该理想状态要满足5个条件:①种群足够大;②种群中个体间可以随机交配;③没有突变发生;④没有新基因加入;⑤没有自然选择。此时各基因频率和各基因型频率存在如下等式关系并且保持不变)
2.每个位点是独立的
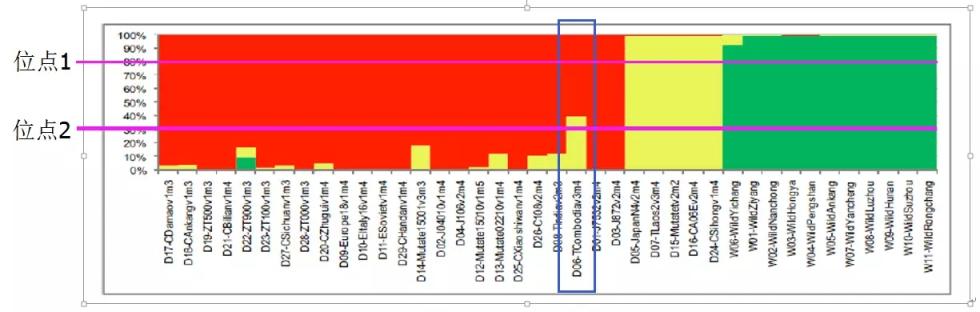
同一个体基因组上的不同SNP可能来源不同亚群体,这是由于杂交混血过程带来的效应。如下图的D06个体,就各有部分DNA来自红色和黄色的亚群体。从另一个维度理解,为了达到哈温平衡,对不同的位点的分类方法是不同的。例如下图中,位点1的分类和位点2的分类策略就不同。位点1将D06个体划为红色亚群,而位点2将D06个体划分为黄色亚群。也就是说,软件是对每个位点单独进行分群的。
3.每个样本的血统构成
既然对每个位点都完成分群了,自然最终就可以计算每个个体的血统构成了。
参考文章:
群体结构图形——structure堆叠图: http://www.genedenovo.com/news/364.html













网友评论