Data preparation
继续上次的内容,下载好数据后就可以正式开始鉴定了。首先回顾一下,下载好的数据。
- 基因组序列信息,存储基因组序列信息的.fasta文件。还有其蛋白质序列,也是以.fasta结尾的文件。一般来说注释的比较好的基因组都会含有这些文件。
- 基因组基因结构注释信息。储存基因的intron,exon,CDS,gene等坐标信息的.gff3或.gtf文件。
- 所感兴趣的基因家族隐马可夫模型,hmm文件
-rw-r----- 1 hhu pawsey0149 9738306 Oct 25 12:24 Arabidopsis_thaliana.TAIR10.41.gff3.gz
-rw-r----- 1 hhu pawsey0149 14623390 Oct 25 12:23 Arabidopsis_thaliana.TAIR10.cds.all.fa.gz
-rw-r----- 1 hhu pawsey0149 36462703 Oct 25 12:23 Arabidopsis_thaliana.TAIR10.dna.toplevel.fa.gz
-rw-r----- 1 hhu pawsey0149 9776319 Oct 25 12:22 Arabidopsis_thaliana.TAIR10.pep.all.fa.gz
-rw-r----- 1 hhu pawsey0149 118379 Oct 25 12:26 NBS-ARC.hmm
基因家族鉴定的工具hmmer
一般寻找基因家族,都可以通过保守结构域来预测,从而找到物种的某一基因家族,从而进行之后的分析。这里就需要用到HMMER,来鉴定物种某一基因家族。
HMMER3.1下载地址:http://hmmer.org/download.html
HMMER3.1 manual:http://eddylab.org/software/hmmer3/3.1b2/Userguide.pdf
hmmbuild/hmmsearch/hmmscan/hmmalign 这几个功能是主要用于蛋白质结构与分析和注释的hmmer中小工具
在鉴定基因家族时,常用到的工具是hmmsearch,里面常用的算法有三种。一般我们使用--cut_tc算法对隐马可夫模型进行搜索,tc算法是使用pfam提供的hmm文件中trusted cutoof的值进行筛选,相对比较可靠。
--cut_ga : use profile's GA gathering cutoffs to set all thresholding
--cut_nc : use profile's NC noise cutoffs to set all thresholding
--cut_tc : use profile's TC trusted cutoffs to set all thresholding
具体实战操作
下面会根据一篇经典文献中的方法,对拟南芥进行NBS-LRR基因组的探索。首先,回顾一下文献看看整体它的思路和方法。
Identification of NBS-LRR genes
Predicted proteins from the cassava genome were scanned using HMMER v3 [39] using the Hidden Markov Model (HMM) corresponding to the Pfam [40] NBS (NB-ARC) family (PF00931; http://pfam.sanger.ac.uk/). From the proteins obtained using the raw NBS HMM, a high-quality protein set (E-value < 1 × 10−20 and manual verification of an intact NBS domain) was aligned and used to construct a cassava-specific NBS HMM using hmmbuild from the HMMER v3 suite. This new cassava-specific HMM was used, and all proteins with an E-value lower than 0.01 were selected. NBS-LRR genes were further filtered based on manual curation and functional annotation against both the closest homolog from Arabidopsis and the UNIREF100 sequence database. Most of the proteins that were removed had at least a partial kinase domain, but no relationship to NBS-LRR genes; this result was expected because the NBS domain has smaller kinase subdomains
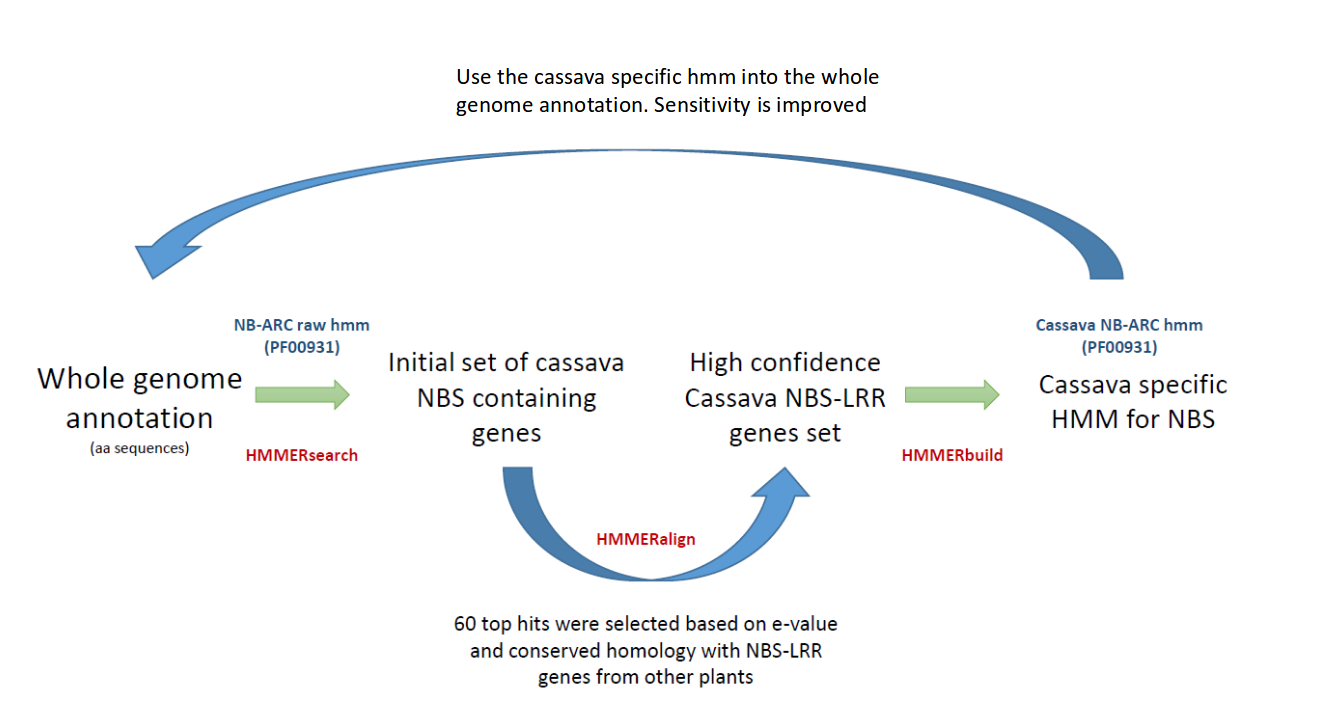
这副图就是对应了该文章的基因家族鉴定思路,首先在全基因组的范围内使用hmmersearch和NBS-ARC基因家族的隐马可夫模型进行基因家族的进行初步搜索,接着把质量比较高的基因家族候选基因筛选出来E-value < 1 × 10−20, 然后使用clustalw2对高质量的序列进行多序列比对,多序列比对后,对这些置信的序列进行隐马可夫模型的构建(使用hmmbuild),最后使用该新建的隐马可夫模型,进一步筛选完整的NSB基因家族序列(需再次过滤,找到基因家族的成员数量一般比第一步初步筛选的多)。
把该流程用到我测试数据中:
##目标基因家族搜索
hmmsearch --cut_tc --domtblout NBS-ABC.out NBS-ARC.hmm Arabidopsis_thaliana.TAIR10.pep.all.fa
##简单看看运算的初步输出结果
head NBS-ABC.out
##output
# --- full sequence --- -------------- this domain ------------- hmm coord ali coord env coord
# target name accession tlen query name accession qlen E-value score bias # of c-Evalue i-Evalue score bias from to from to from to acc description of target
#
AT1G61180.1 - 889 NB-ARC PF00931.22 252 1.4e-90 304.3 0.6 1 1 2.2e-92 2.5e-90 303.5 0.6 1 251 156 397 156 398 0.99 pep chromosome:TAIR10:1:22551271:22554684:1 gene:AT1G61180 transcript:AT1G61180.1 gene_biotype:protein_coding transcript_biotype:protein_coding description:LRR and NB-ARC domains-containing disease resistance protein [Source:UniProtKB/TrEMBL;Acc:Q2V4G0]
AT1G61180.2 - 899 NB-ARC PF00931.22 252 1.5e-90 304.2 0.6 1 1 2.2e-92 2.5e-90 303.5 0.6 1 251 156 397 156 398 0.99 pep chromosome:TAIR10:1:22551271:22554684:1 gene:AT1G61180 transcript:AT1G61180.2 gene_biotype:protein_coding transcript_biotype:protein_coding description:LRR and NB-ARC domains-containing disease resistance protein [Source:UniProtKB/TrEMBL;Acc:Q2V4G0]
###对其e-value进行筛选,筛选出高质量的NBS-LRR蛋白质序列。
grep -v "#" NBS-ABC.out|awk '($7 + 0) < 1E-20'|cut -f1 -d " "|sort -u > NBS-ARC_qua_id.txt
~/biosoft/seqtk/seqtk subseq Arabidopsis_thaliana.TAIR10.pep.all.fa NBS-ARC_qua_id.txt >NBS-ARC_qua.fa
对筛选出来的序列,使用clustalw2进行多序列的比较
clustalw2
**************************************************************
******** CLUSTAL 2.1 Multiple Sequence Alignments ********
**************************************************************
1. Sequence Input From Disc
2. Multiple Alignments
3. Profile / Structure Alignments
4. Phylogenetic trees
S. Execute a system command
H. HELP
X. EXIT (leave program)
Your choice: 1
Sequences should all be in 1 file.
7 formats accepted:
NBRF/PIR, EMBL/SwissProt, Pearson (Fasta), GDE, Clustal, GCG/MSF, RSF.
Enter the name of the sequence file : NBS-ARC_qua.fa
**************************************************************
******** CLUSTAL 2.1 Multiple Sequence Alignments ********
**************************************************************
1. Sequence Input From Disc
2. Multiple Alignments
3. Profile / Structure Alignments
4. Phylogenetic trees
S. Execute a system command
H. HELP
X. EXIT (leave program)
Your choice: 1
Sequences should all be in 1 file.
7 formats accepted:
NBRF/PIR, EMBL/SwissProt, Pearson (Fasta), GDE, Clustal, GCG/MSF, RSF.
Enter the name of the sequence file : new_NBS.aln
对这些置信的序列进行隐马可夫模型的构建(使用hmmbuild),构建更加准确地尽可能预测所有的基因家族成员。
hmmbuild NBS-ARC.second.out NBS-ARC_qua.aln
hmmsearch --cut_tc --domtblout NBS-ARC.second.out NBS-ARC_qua.hmm ../Arabidopsis_thaliana.TAIR10.pep.all.fa
最后对再次对这些基因进行过滤与提取
grep -v "#" NBS-ABC.second.out|awk '($7 + 0) < 1E-03' | cut -f1 -d " "|sort -u >final.NBS.list
~/biosoft/seqtk/seqtk subseq Arabidopsis_thaliana.TAIR10.pep.all.fa final.NBS.list >final_NBS-ARC_qua.fa
BLAST-based method
除了使用隐马可夫模型和hmmer搜索的方法外,使用同源比对blast的方法也是鉴定基因家族的其中一种方法。
首先我去了NCBI下载所有植物的存在于Ref-seq(一般认为是比较置信的植物基因序列)中的NBS序列
makeblastdb -in ref.nbs.plant.fa -dbtype prot
cat blastp.out |awk '$3>75' |cut -f1 |sort -u > blastp_result_id.list
最后我们还可将上述两种方法重合的gene id,找出两种方法共有的基因家族,这样结果就比较置信了。
comm -12 blastp_result_id.list hmm_out_id.list > common.list
~/biosoft/seqtk/seqtk subseq Arabidopsis_thaliana.TAIR10.pep.all.fa common.list >final_searh_NBS-ARC_qua.fa
最后可以通过一些网上的保守结构域搜索网页,进一步对所找出的结果进行验证:
比如:NCBI CD-Search tool
https://www.ncbi.nlm.nih.gov/Structure/bwrpsb/bwrpsb.cgi
Pfam的搜索:
https://pfam.xfam.org/search#tabview=tab1
又或者:InterProScan sequence search
https://www.ebi.ac.uk/interpro/search/sequence-search
这些工具都可再次验证所搜寻的蛋白质序列是不是含有基因家族对应的domain。在查看保守结构域后,如果该区域含有NBS所对应的保守结构域,例如LRR区域等,该蛋白质序列可以保留进行后续的分析。如果在该区域没有找到对应的保守区域,为了分析的严谨性,需进行进一步的排查来确定是否要去掉该序列。这种情况一般分为两种情况,第一种就是注释无误,该序列确实丢失了对应的保守结构域,需要去掉。第二种情况就是注释有误,该序列的结构域可能没有被完整的保留下来,这种情况应该截取该序列的上下游重新注释分析。




网友评论